
1.CoAtNets:畳み込みと自己注意の利点を備えたハイブリッドモデル(2/2)まとめ
・CNNよりTransformerモデルの方が大規模データセットに対応する能力が高い
・CoAtNetsは畳み込みと自己注意を組み合わせたハイブリッドモデル
・CoAtNetはViTモデルよりも4倍速く学習可能でImageNetで最先端のスコアを更新
2.CoAtNetsとは?
以下、ai.googleblog.comより「Toward Fast and Accurate Neural Networks for Image Recognition」の意訳です。元記事の投稿は2021年9月16日、Mingxing TanさんとZihang Daiさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by marco xu on Unsplash
CoAtNet:大規模な画像認識のための高速で正確なモデル
EfficientNetV2は依然として典型的な畳み込みニューラルネットワーク(CNN:Convolutional Neural Networks)ですが、Vision Transformer(ViT)に関する最近の研究では、AttentionベースのTransformer モデルがJFT-300Mのような大規模データセットで畳み込みニューラルネットワークよりも優れたパフォーマンスを発揮することが示されています。
この観察に触発されて、より速くより正確なビジョンモデルを見つけることを目的として、畳み込みニューラルネットワークを超えて研究をさらに拡大しました。
論文「CoAtNet: Marrying Convolution and Attention for All Data Sizes」では、畳み込みと自己注意(self-attention)を組み合わせて、大規模な画像認識のための高速で正確なニューラルネットワークを開発する方法を体系的に研究します。
私たちの研究は以下の観察に基いています。
・畳み込みはその誘導バイアスのために一般化能力に優れている事が多い(つまり、トレーニング時と評価時の間のパフォーマンスギャップが少ない)
・自己注意はそのグローバルな受容野(global receptive field)のおかげでより大きなモデル容量を持つ傾向がある(つまり、大規模なトレーニングに適合する能力)
畳み込みと自己注意を組み合わせることにより、私達のハイブリッドモデルはより優れた一般化とより大きな容量の両方を実現できます。
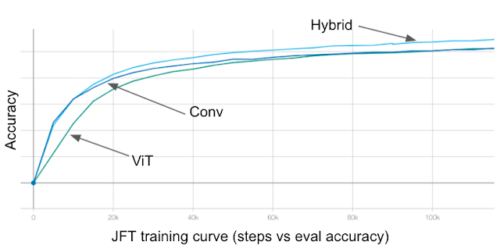
畳み込み(Conv)、自己注意(VIT)、およびハイブリッド(Hybrid)モデルの比較
畳み込みモデルはより速く収束し、ViTはより優れた容量を持ち、ハイブリッドモデルはより速い収束とより優れた精度の両方を実現します。
私たちは、研究結果から2つの重要な洞察を観察しました。
(1)深さ方向の畳み込みと自己注意は、単純な相対的注意(relative attention)によって自然に統合することができます。
(2)畳み込み層と注意層を、各段階(解像度)で必要な容量と計算を考慮して垂直に積み重ねることは、一般化、容量、および効率の向上に驚くほど効果的です。
これらの洞察に基づいて、CoAtNets(「coat」ネットと発音)という、畳み込みと注意の両方を備えたハイブリッドモデルの系統を開発しました。次の図は、CoAtNetネットワークアーキテクチャ全体を示しています。

CoAtNetアーキテクチャの全体図
サイズがHxWの入力画像が与えられた場合、まず最初のステージ(S0)で畳み込みを適用し、サイズをH / 2 x W / 2に縮小します。サイズは各段階で縮小し続けます。 Lnは層の数を指します。
次に、初期の2つのステージ(S1とS2)は、主に深さ方向の畳み込みで構成されるMBConvビルディングブロックを採用します。
後の2つのステージ(S3とS4)は、主に比較的自己注意を持つTransformerブロックを採用しています。ViTの以前のTransformerブロックとは異なり、ここでは、Funnel Transformerと同様に、ステージ間のプーリングを使用します。最後に、分類ヘッドを適用してクラス予測を生成します。
CoAtNetモデルは、ImageNet1K、ImageNet21K、JFTなどの多くのデータセットにわたってViTモデルとその亜種を一貫して上回っています。畳み込みネットワークと比較した場合、CoAtNetは小規模データセット(ImageNet1K)で同等のパフォーマンスを示し、データサイズが大きくなるにつれて(ImageNet21KやJFTなど)大幅な向上を実現します。
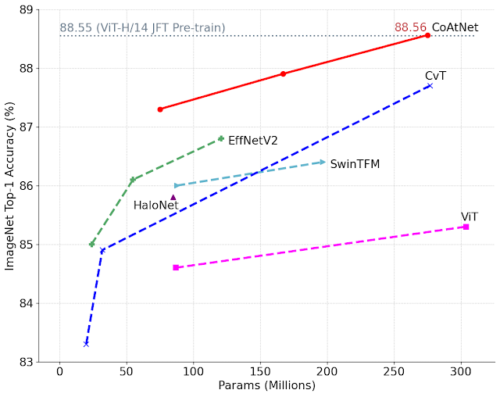
中規模のImageNet21Kデータセットで事前トレーニングした後のCoAtNetと従来モデルの比較
同じモデルサイズの条件下で、CoAtNetは一貫してViTモデルと畳み込みモデルの両方を上回ります。注目すべきことに、CoAtNetはImageNet21Kのみを使ったトレーニングで、より巨大なデータセットであるJFTで事前トレーニングされたViT-Hのパフォーマンスに到達することができます。
また、大規模なJFTデータセットでCoAtNetsを評価しました。同等の精度目標を達成するために、CoAtNetは以前のViTモデルよりも約4倍速くトレーニングし、さらに重要なことに、ImageNetで90.88%の新しい最先端のtop-1精度を達成します。
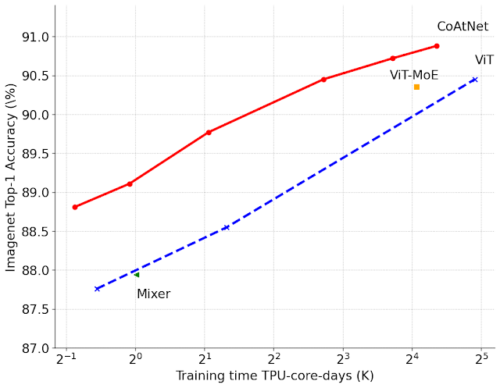
CoAtNetsと以前のViTの比較
さまざまなトレーニング予算でJFTデータセットを事前トレーニングした後のImageNetのトップ1の精度。4つの最高のモデルは、JFT-3B(約30億画像)を使用してでトレーニングされています。
結論と今後の作業
本投稿では、EfficientNetV2とCoAtNetという名前のニューラルネットワークの2つの系統を紹介しました。これらは、画像認識で最先端のパフォーマンスを実現します。
すべてのEfficientNetV2モデルはオープンソースであり、事前トレーニング済みモデルはTFhubでも入手できます。CoAtNetモデルもまもなくオープンソースになります。これらの新しいニューラルネットワークが研究コミュニティと業界に利益をもたらすことを願っています。将来的には、これらのモデルをさらに最適化し、ゼロショット学習や自己教師あり学習など、大容量の高速モデルを必要とすることが多い新しいタスクに適用する予定です。
謝辞
共著者のHanxiao LiuとQuoc Leに感謝します。また、Google Research、Brain Team、およびオープンソースの貢献者にも感謝します。
3.CoAtNets:畳み込みと自己注意の利点を備えたハイブリッドモデル(2/2)関連リンク
1)ai.googleblog.com
Toward Fast and Accurate Neural Networks for Image Recognition
2)arxiv.org
EfficientNetV2: Smaller Models and Faster Training
CoAtNet: Marrying Convolution and Attention for All Data Sizes
3)github.com
google / automl
4)tfhub.dev
efficientnet_v2

