
1.発声に困難を抱える人の音声コミュニケーションを支援するモデル用のデータセットの開発(2/2)まとめ
・全体的にパーソナライズ手法は全重症度レベルと条件にわたって大幅な改善をもたらした
・個人向けに最適化されたASRモデルの単語誤り率は人間の専門家と比較しても低かった
・幅広い音声障害と重症度を認識する個人向けに最適化したASRモデルの有効性が確認できた
2.パーソナライズASRモデルの有効性
以下、ai.googleblog.comより「Personalized ASR Models from a Large and Diverse Disordered Speech Dataset」の意訳です。元記事は2021年9月9日、Katrin TomanekさんとBob MacDonaldさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Timothy Dykes on Unsplash
これを達成するために、私たちはエンコーダネットワークを適応させることに焦点を当てています。つまりモデルの「特定の話者の特定の音響を扱う一部分」を変更します。これは、音声障害が私たちのコーパスで最も一般的だったためです。
上位3つのエンコーダーレイヤー(およびジョイントレイヤーとデコーダーレイヤー)を固定しながら、(8つのうち)下位5つのエンコーダーレイヤーのみを更新すると、最良の結果が得られ、過剰適合を効果的に回避できることがわかりました。
これらのモデルをバックグラウンドノイズやその他の音響効果に対してより堅牢にするために、乱れた音声の一般的な特性に合わせて特別に調整されたSpecAugmentを採用しています。
さらに、事前にトレーニングされた基本モデルの選択が重要であることがわかりました。典型的な音声の巨大で多様なデータ(複数の領域と音響条件)でトレーニングされた基本モデルは、私たちのシナリオに最適であることが証明されました。
結果
少なくとも300の発話を録音した約430人の話者向けに個人向けに最適化されたASRモデルをトレーニングしました。
発話データの10%はテストセット(フレーズの重複なし)としてトレーニングに使用しないで保持され、個人向けに最適化したモデルと最適化していないベースモデルの単語誤り率(WER:Word Error Rate)を比較するために使用されました。
全体として、私たちのパーソナライズアプローチは、すべての重症度レベルと条件にわたって大幅な改善をもたらします。重度の言語障害がある場合でも、ホームオートメーションで良く使用される短いフレーズのWERの中央値は約89%から13%に低下しました。会話や介護者などの他の領域でも、精度が大幅に向上しました。
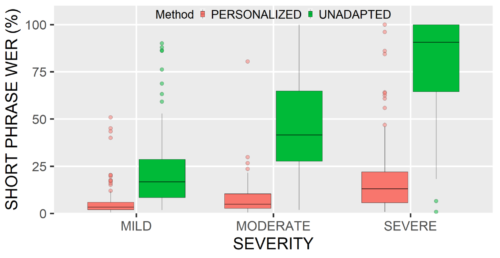
ホームオートメーションに関する言い回しにおける個人向け最適化モデルと最適化を行っていないモデルのASRモデルのWER
個人向け最適化がうまく機能しないケースを理解するために、いくつかのサブグループを分析しました。
・HighWERおよびLowWER
WERを5分割した上位1群および下位1群に基づいた個人向けの最適化性能が高いモデルと低いモデルのWERの分布
・SurpHighWER
驚くほどWERが高い話者(HighWERグループの典型的な言語障害または軽度の言語障害のある参加者)
さまざまな病状と言語障害の症状がASRに不均一に影響を与えると予想されます。
HighWERグループ内の言語障害タイプの分布は、脳性麻痺による「神経原性の発話障害(dysarthria)」のモデル化が特に困難であることを示しています。当然のことながら、重症度の中央値もこのグループの方が高いです。
ASRの精度に影響を与える話者固有の技術的要因を特定するために、ASRのパフォーマンスが低い(HighWER)と優れている(LowWER)参加者間のメタデータの違い(Cohen’s D)を調べました。
予想通り、全体的な発話の重症度は、HighWERグループよりもLowWERグループの方が有意に(p <0.01)低かったです。明瞭度(intelligibility)と重症度(severity)は、HighWERグループで最も顕著な非定型音声特徴でした。ただし、異常な韻律、調音(articulation)、発声など、他の音声特徴も出現しました。これらの音声特徴は、全体的な音声明瞭度を低下させることが知られています。
SurpHighWERグループはLowWERグループと比較してトレーニング用発話が少なくSNRが低く(p <0.01)、結果として大きな(負の)効果サイズ(effect sizes)が得られ、他のすべての要因は安定性を除いて小さな効果サイズを持っていました。
対照的に、HighWERグループは、すべての要因で中程度から大きな違いを示しました。
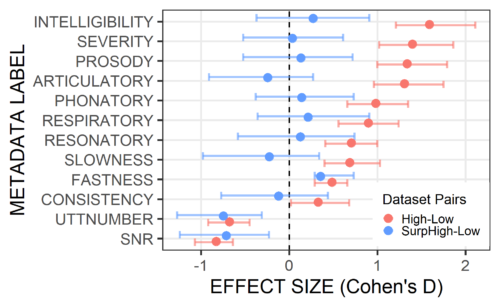
HighWER-vs-LowWERおよびSurpHighWER-vs-LowWERペアの音声障害および技術メタデータ効果サイズ
正の効果は、HighWERグループのグループ値がLowWERグループよりも大きいことを示しています。
次に、個人向けに最適化したASRモデルと人間と比較しました。3人のスピーチの専門家が、話者ごとに30の発話を個別に書き起こしました。個人向け最適化されたASRモデルのWERは、人間のリスナーのWERと比較して平均して低く、重症度によって増加することがわかりました。
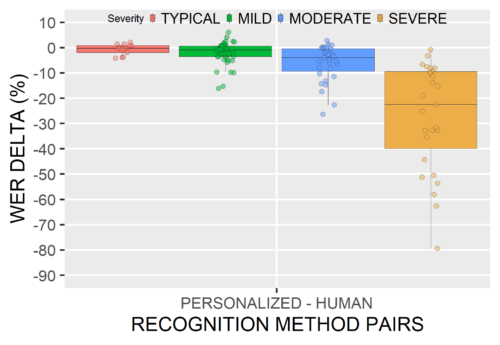
個人向けに最適化したASRモデルのWERと人間のリスナーの間のデルタ
負の値は、個人向けに最適化したASRが人間(専門家)のリスナーよりも優れたパフォーマンスを発揮した事を示します。
結論
100万を超える発話を持つEuphoniaの音声資料は、(障害の種類と重症度の点で)最大かつ最も多様な障害のある音声資料の1つであり、これらの種類の非定型音声のASR精度を大幅に向上させました。
私たちの結果は、ASRをより多くのユーザーが利用できるようにする可能性を秘めた、幅広い音声障害と重症度を認識するために個人向けに最適化したパーソナライズASRモデルの有効性を示しています。
謝辞
このプロジェクトの主な貢献者には、Michael Brenner, Julie Cattiau, Richard Cave, Jordan Green, Rus Heywood, Pan-Pan Jiang, Anton Kast, Marilyn Ladewig, Bob MacDonald, Phil Nelson, Katie Seaver, Jimmy Tobin, そして Katrin Tomanekが含まれます。
Françoise Beaufays, Fadi Biadsy, Dotan Emanuel, Khe Chai Sim, Pedro Moreno Mengibar, Arun Narayanan, Hasim Sak, Suzan Schwartz, Joel Shorなど、Google全体の多くの音声研究チームのメンバーからプロジェクトEuphoniaが受けたサポートに感謝します。
そして最も重要なことは、スピーチのサンプルを録音してくれた1300人を超える参加者と、これらの参加者とのつながりを助けてくれた多くの擁護団体に心から感謝します。
3.発声に困難を抱える人の音声コミュニケーションを支援するモデル用のデータセットの開発(2/2)関連リンク
1)ai.googleblog.com
Personalized ASR Models from a Large and Diverse Disordered Speech Dataset
2)sites.research.google
Project Euphonia
3)www.isca-speech.org
Disordered Speech Data Collection: Lessons Learned at 1 Million Utterances from Project Euphonia
Automatic Speech Recognition of Disordered Speech: Personalized Models Outperforming Human Listeners on Short Phrases

