1.発声に困難を抱える人を自分自身の声で話せるようにする試み(2/2)まとめ
・通常のNATモデルはカンマの後にくる「two」と「too」を混同してしまう
・PnG NATモデルは、入力として音素に加えて書記素を受け取るので空白を適切に扱える
・Project Euphoniaは、言語障害のある人の理解を深めることに焦点を当てたプロジェクト
2.失った声を再現した技術
以下、ai.googleblog.comより「Recreating Natural Voices for People with Speech Impairments」の意訳です。元記事は2021年8月30日、Ye JiaさんとJulie Cattiauさんによる投稿です。
アイキャッチ画像はのクレジットはPhoto by Major Tom Agency on Unsplash
たとえば、入力として音素のみを受け取る通常のNATモデルから合成されたオーディオは次のようになります。
対照的に、同じ入力テキストでPnG NATから合成されたオーディオには、意味をより明確にする追加の一時停止が含まれています。
両方のモデルへ与えた入力テキストは次のとおりです。
「To cancel the payment, press one; or to continue, two.(支払いをキャンセルするには、1を押します。または続行するには2を)」
2つのバージョンでは、「two」の直前の一時停止の長さが異なることに注意してください。
通常のNATモデルによって出力されるバージョンの「two」という単語は、「too」と混同される可能性があります。「too」と「two」の発音は同一(したがって同じ音素表現)であるため、通常のNATモデルは、どちらが適切かを理解せず、コンマの後に続く事が最も多い単語である「too」を想定してしまいます。
対照的に、PnG NATモデルは、入力として音素に加えて書記素を取り、より適切な一時停止を行います。そのため、違いをより簡単に見分けることができます。
PnG NATモデルは、事前トレーニングされたPnG BERTモデルをエンコーダーとしてNATモデルに統合します。エンコーダーから出力された隠れ特徴表現は、各音素の持続時間を予測するためにNATによって使用され、次に、上記で概説したように、オーディオスペクトログラムの長さに一致するようにアップサンプリングされます。最後のステップでは、Attentionを持たないデコーダーが、アップサンプリングされた隠れ特徴表現を音声音声スペクトログラムに変換します。これは、最終的にニューラルボコーダーによって音声波形に変換されます。
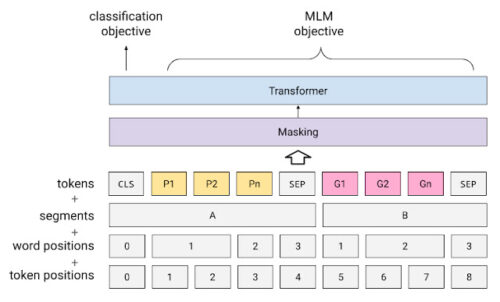
PnG BERTと事前トレーニングの目的
黄色のボックスは音素を表し、ピンクのボックスは書記素を表します。
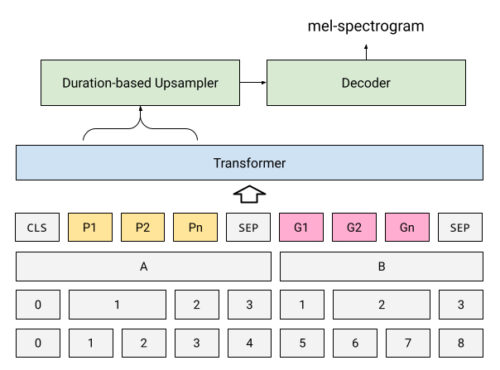
PnG NAT:PnG BERTでNATモデルの元のエンコーダーを置き換えます。
マスク言語モデル(MLM:Masked Language Model)のランダムマスキング事前トレーニングは削除されています。
スティーブ・グリーソンの声を再現するために、最初に31人のプロの話し手の声を録音してPnG NATモデルをトレーニングし、次に30分のグリーソンの録音で微調整しました。これらの後者の録音は、彼がALSと診断された後に行われたため、不明瞭な兆候を示しています。
微調整されたモデルは、これらの録音に非常によく似た音声を合成することができました。ただし、ALSの症状が影響を及ぼす発声の非流暢さはグリーソンのスピーチにすでに表れていたため、モデルは少し同様な非流暢さを示しました。
これを軽減するために、NATの音素持続時間制御と、プロの話し手でトレーニングされたモデルを活用しました。最初に、プロの話者とグリーソンの両方の各音素の持続時間を予測し、次に各音素の2つの持続時間の幾何平均を使用してNAT出力をガイドしました。その結果、モデルはグリーソンの声で話すことができますが、元の録音よりも流暢に話すことができます。
以下は、グリーソンの声で合成されたルーゲーリッグのスピーチの完全版です。
PnG NATは、ALSを持つ人々の声を再現するだけでなく、Google Cloud Custom Voiceを通じてさまざまな顧客の声を強化しています。
Project Euphonia
世界中の何百万もの人々が、彼らのスピーチに影響を与えるかもしれない神経学的状態となっています。ALS、脳性麻痺、ダウン症などの発声は、多くの人が理解するのが難しいと感じるかもしれず、この状態は、対面でのコミュニケーションを困難にする可能性があります。
彼らが、音声を契機として起動するテクノロジーを使用すると、常に確実に機能するとは限らないため、イライラすることもあります。
Project Euphoniaは、言語障害のある人の理解を深めることに焦点を当てておりGoogle Researchが先導しています。チームは、音声障害のある個人の音声認識を改善する方法(最近のブログ投稿とTODAY showを参照)、およびカスタマイズされたテキスト読み上げテクノロジー(元NFLプレーヤーのTim Shawを特集したyoutube ドキュメンタリー「The Age of A.I. シーズン 1 エピソード 2」を参照)を研究しています。
謝辞
Google Research、Google Cloud and Consumer Apps、およびGoogle Accessibilityチーム全体の多くの人々が、このプロジェクトとイベントに貢献しました。Michael Brenner, Bob MacDonald, Heiga Zen, Yu Zhang, Jonathan Shen, Isaac Elias, Yonghui Wu, Anne Keck, Danielle Notaro, Kevin Hogan, Zack Kaplan, KR Liu, Kyndra Price, Zoe Ortizを含みます。
3.発声に困難を抱える人を自分自身の声で話せるようにする試み(2/2)関連リンク
1)ai.googleblog.com
Recreating Natural Voices for People with Speech Impairments
2)sites.research.google
Project Euphonia
3)baseballhall.org
LUCKIEST MAN
4)www.youtube.com
The Age of A.I.

