
1.SupCon:対照学習を教師有り学習に拡張(1/2)まとめ
・自己教師あり特徴表現学習は対照学習を応用する事でより大幅に進歩した
・アンカー画像とマッチしないネガティブ画像を選択する際に問題があった
・SupConは教師有り学習のラベルを利用する事でこの問題を解決する
2.教師有り学習対照学習とは?
以下、ai.googleblog.comより「Extending Contrastive Learning to the Supervised Setting」の意訳です。元記事は2021年6月4日、AJ MaschinotさんとJenny Huangさんによる投稿です。
Contrastは画像関連用語では「明るい部分と暗い部分の輝度の対比」の意味で使われる事が多いですよね、って事でそこから連想したアイキャッチ画像のクレジットはPhoto by Ostap Senyuk on Unsplash
近年、さまざまな画像やビデオのタスクで使用される自己教師あり特徴表現学習(self-supervised representation learning)は、対照学習(contrastive learning)を応用する事でより大幅に進歩しています。
これらの対照的な学習アプローチは、通常、モデルにターゲット画像(アンカー(anchor)とも呼ばれます)にマッチする「ポジティブ(positive)画像」の特徴表現がembedding空間内で近くなるように配置し、また、多くのマッチしない「ネガティブ(negative)画像」をアンカーから遠ざかるように配置する事を学習させます。
自己教師あり学習が必要になる状況では画像にラベルが付与されている事は想定できないため、ポジティブ画像はアンカー画像に回転や切り抜きなどの画像編集操作を加えて水増しする手法(augmentation)を適用した画像であることが多く、ネガティブ画像はトレーニングミニバッチ内から他のサンプルが選択されます。
ただし、このネガティブ画像をランダムに選択する事で、偽陰性、つまりアンカーと同じクラスのサンプル画像からネガティブ画像が生成される可能性があり、これは特徴表現の品質低下を引き起こす可能性があります。更に、ポジティブ画像を生成するための最適な手法を決定することは、まだ活発な研究段階の領域です。
自己教師ありアプローチとは対照的に、完全教師あり学習手法では、ラベル付きデータを使用して、既存の同じクラスのサンプルからポジティブを生成できます。
これにより、アンカー画像を単純に水増し手法で編集してポジティブを作成するよりも、事前トレーニングでのデータの多様性を大きくできます。ただし、完全教師あり学習で対照学習を正常に適用するための研究はほとんど行われていません。
NeurIPS 2020で発表された論文「Supervised Contrastive Learning」では、SupConと呼ばれる新しい損失関数を提案します。これは、自己教師あり学習と完全教師あり学習のギャップを埋め、教師あり設定で対照学習を使用できるようにします。
ラベル付けされたデータを活用して、SupConは、同じクラスの正規化されたembeddingを互いに近づけるように促し、異なるクラスからのembeddingを押し離します。
これにより、潜在的な偽陰性を回避しながら、ポジティブ画像を選択するプロセスが簡素化されます。アンカー毎に複数のポジティブ画像を対応させるため、このアプローチでは、意味的に関連する情報を含みつつ、且つより多様なポジティブ画像を選択する改善ができます。
SupConを使用すると、従来の対照学習のように、ラベル情報を下流工程での学習でのみ使用するように制限するのではなく、特徴表現学習で積極的な役割を果たすこともできます。
私たちの知る限り、これは、クロスエントロピー損失を使用してモデルを直接トレーニングする一般的なアプローチよりも、大規模な画像分類問題で一貫して優れたパフォーマンスを発揮する最初の対照的な損失です。
重要な事は、SupConは実装が簡単で、トレーニングが安定していることです。多数のデータセットとアーキテクチャ(Transformerアーキテクチャを含む)のTop 1精度を一貫して向上させ、画像の破損やハイパーパラメータの変動に対して堅牢です。
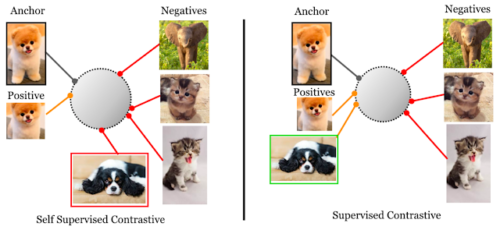
自己教師設定(左)と完全教師設定(右)での対照損失の違い
自己教師対照損失は、各アンカーの単一のポジティブ(つまり、同じ画像の拡張バージョン)を、ミニバッチの残りの部分全体から構成されるネガティブセットと対比します。しかしながら本論文で検討している教師あり対照損失は、同じクラスのすべてのサンプルのセットをポジティブ、バッチの残りの部分をネガティブとして対比します。
教師あり対照学習フレームワーク
SupConは、SimCLRとN-pairの両方の損失の一般化と見なすことができます。
前者はアンカーと同じサンプルから生成されたポジティブを使用し、後者は既知のクラスラベルを利用して異なるサンプルから生成されたポジティブを使用します。
各アンカーに多くのポジティブとネガティブを使用することで、SupConは、適切に調整するのが難しいハードネガティブマイニング(hard negative mining、つまり、アンカーに類似したネガティブを捜す)を必要とせずに、最先端のパフォーマンスを実現できます。

SupConは、複数の文献から得た損失を包含し、SimCLRおよびN-Pairの損失を一般化したものです。
この手法は、教師あり学習を使った画像分類手法を変更して、自己教師あり対照学習で使用する手法と構造的に似ています。
データが入力バッチとして与えられた時、最初にデータ水増しを2回適用して、バッチ内の各サンプルの2つのコピー、つまり「(各画像を回転したり切り抜いたりした)視点」を取得します。(ただし、拡張した視点をいくつでも作成して使用できます)
両方のコピーはエンコーダネットワークを介して順方向に伝播され、結果のembeddingはL2で正規化されます。標準的な方法に従って、特徴表現は追加の射影ネットワークを介してさらに伝播され、これは意味のある特徴表現を特定するのに役立ちます。
教師あり対照損失は、投影ネットワークの正規化された出力で計算されます。アンカーのポジティブは、アンカーと同じバッチインスタンス、またはアンカーと同じラベルを持つ他のインスタンスから発生した特徴表現で構成されます。その場合、ネガティブは残りのすべてのインスタンスになります。下流工程タスクのパフォーマンスを測定するために、凍結した特徴表現の上に線形分類器をトレーニングします。
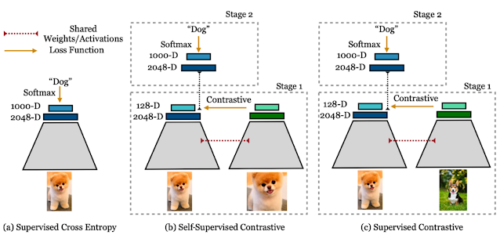
教師有りクロスエントロピー、教師あり対照損失、および教師あり対照損失の比較
左:クロスエントロピー損失は、ラベルとソフトマックス損失を使用して分類器をトレーニングします。
中央:自己教師あり対照損失は、対照損失とデータ拡張を使用して特徴表現を学習します。
右:教師あり対照損失も対照損失を使用して表現を学習しますが、同じ画像を水増しする事に加えて、ラベル情報を使用してポジティブ画像をサンプリングします。
3.SupCon:対照学習を教師有り学習に拡張(1/2)関連リンク
1)ai.googleblog.com
Extending Contrastive Learning to the Supervised Setting
2)arxiv.org
Supervised Contrastive Learning
3)github.com
google-research/supcon/
4)tfhub.dev
supcon | TensorFlow Hub

