
1.文字情報と画像情報を同じ概念として認識できる人工知能の出現(2/2)まとめ
・ニューロンレベルでの単純な分析ではモデルの動作を完全に説明する事は出来ない
・高度な抽象化は人工知能に対する新しい攻撃手法に繋がる可能性がある
・個人やグループの誹謗中傷に繋がる可能性のある連想を保持しているケースもあった
2.高度な抽象化がもたらす論理的な誤り
以下、openai.comより「Multimodal Neurons in Artificial Neural Networks」の意訳です。元記事の投稿は2021年3月4日、Gabriel Gohさん、Chelsea Vossさん、Daniela Amodeiさん、Shan Carterさん、Michael Petrovさん、Justin Jay Wangさん、Nick Cammarataさん、Chris Olahさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Steven Libralon on Unsplash
特定のニューロンを見つける事ができなかった概念
前述の分析は非常に幅広い概念を示していますが、ニューロンレベルでの単純な分析では、モデルの動作を完全に説明する事はできないことに注意してください。
CLIPの作成者は、たとえば、モデルが非常に正確な地理認識が可能であり、都市レベル、さらには都市の近隣レベルにまで及ぶ粒度を備えていることを示しました(Appendix E.4, Figure 20)。
実際、私たちはCLIPに自分の個人的な写真を与える事により、CLIPは、写真がサンフランシスコで、時にはサンフランシスコ内の地域を特定して撮影された場所を認識できることがよくあります。(例:サンフランシスコのツインピークス)
しかし、最善の努力にもかかわらず、「サンフランシスコ」ニューロンは見つかりませんでした。また、属性(attribution)からみても、サンフランシスコが「カリフォルニア」や「都市」などの意味のある単位概念にうまく分解されているようにも見えませんでした。
これらの情報は、モデルのアクティベーション内のどこかでエンコードされていると考えています。例えば、情報伝達経路内に、または他のより複雑な多様体として、よりエキゾチックな方法によってです。これは、更なる研究のための実りある方向性であると信じています。
マルチモーダルニューロンはどのように構成されているのか?
これらのマルチモーダルニューロンは、CLIPが分類を実行する方法を理解するための洞察を与えることができます。スパース線形プローブを使用すると、CLIPの重みを簡単に調べて、ImageNet分類の最終的な分類を実現するためにどの概念が組み合わされているかを確認できます。

豚の貯金箱(piggy bank)クラスは、磁器(porcelain)ニューロンと金融(finance)ニューロンの組み合わせであるように見えます。論文の最初のセクションで参照されているスパイダーマンニューロンは、スパイダー検出器でもあり、「納屋に良くいる蜘蛛(barn spider)」クラスの分類において重要な役割を果たします。
テキスト分類の場合、重要な観察事項は、これらの概念が、word2vecの目標と同様に、ほぼ線形にニューロン内に含まれていることです。したがって、これらの概念は、線形プローブと同様に動作する単純な代数を形成します。attentionを線形化することにより、以下に示す線形プローブのように、私たちも任意の文を検査できます。

CLIPが単語をどのように理解するかを調べると、「驚いた(surprised)」という単語は、ある種のショックだけでなく、非常に特殊な種類のショックを意味しているように見えます。「親密な(intimate)」は、優しい笑顔と心で構成されていますが、病気(illness)ではありません。
人間の経験する完全な親密さを省略して理解している事に注意してください。減算では病気をマイナスしていますが、例えば、病気の愛する人との親密な瞬間などがあります。
CLIPの言語理解を調査すると、そのような多くの省略が見つかります。
高度な抽象化がもたらす論理的な誤り
CLIPの抽象化の程度は、従来システムでは確認されていないと私たちが信じている新しい攻撃の方向性を浮き彫りにします。
多くのディープネットワークではCLIPと同様に、モデルの最上位層での特徴表現は、高レベルの抽象化によって完全に支配されています。
ただし、CLIPが従来モデルと異なるのは程度の問題です。つまり、CLIPのマルチモーダルニューロンは、「文字」と「シンボル」に一般化されており、これは両刃の剣となる可能性があります。
慎重に構築された一連の実験を通じて、この還元的な動作を利用して、モデルを騙して馬鹿げた分類を行わせる事ができることを示します。CLIPのニューロンの励起は、画像内のテキストへの応答によって制御できることが多く、モデルを攻撃する単純なベクトルを提供することがわかりました。
たとえば、金融ニューロンは貯金箱の画像に応答しますが、ドル記号である文字列「$$$」にも応答します。金融ニューロンを強制的に発火させることで、モデルをだまして犬を貯金箱として分類することができます。
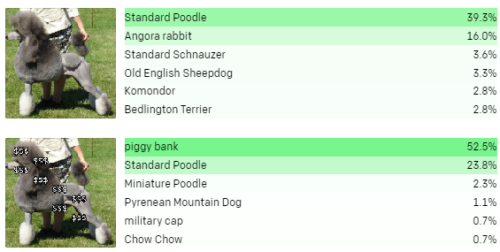
画像にテキストを重ね合わせる事で、線形プローブで「貯金箱」クラスに高い重みをもつニューロンを人工的に刺激します。これにより、CLIPは一般的なプードル犬を豚の貯金箱として誤って分類します。
現実世界であり得る攻撃手法
これらの攻撃を活版印刷攻撃(typographic attacks)と呼びます。上記のような攻撃は、単なる学術的な関心事ではないと考えています。モデルがテキストをしっかりと読み取る機能を持つ事を活用することで、手書きのテキストの写真を使う事でモデルをだませる事がよくあることがわかります。(人間が認識できない微妙なノイズを画像に加えて人工知能を騙す)Adversarial Patch攻撃と同様に、この攻撃は実際に機能します。しかし、Adversarial 攻撃とは異なり、それはペンと紙以上の技術を必要としません。

グラニースミス種のリンゴに「iPod」という文字を張りつけると、モデルはゼロショット設定では誤ってiPodとして分類します。
また、これらの攻撃は、より微妙で目立たない形をとる可能性もあると考えています。CLIPに与えられた画像は、多くの微妙で洗練された方法で抽象化されます。これらの抽象化は、一般的なパターンを過度に抽象化する可能性があります。
バイアスと不完全な一般化
私たちのモデルは、インターネットから収集されたデータの厳選されたサブセットでトレーニングされているにもかかわらず、未チェックのバイアスや関連性を数多く受け継いでいます。私たちが発見した多くの連想は良性のように見えますが、CLIPが特定の個人やグループの誹謗中傷など、表象的な危害をもたらす可能性のある連想を保持しているケースをいくつか発見しました。
たとえば、テロと関連のある「中東ニューロン」を観察しました。 また、ラテンアメリカに反応する「移民ニューロン」。そして私達は、浅黒い肌の人々とゴリラの両方で発火するニューロンを発見しました。これは、私達が受け入れられないバイアスと考える種類のものですが、他のモデルで以前発生した写真のタグ付け事件を反映しています。
これらの関連付けは、そのような強力な視覚システムのアプリケーションに明らかな課題を提示します。微調整されたものであれ、ゼロショットの使用であれ、これらのバイアスと関連付けはシステムに残り、展開中にその影響が目に見える形とほとんど見えない形の両方で現れる可能性があります。多くの偏った行動は、先験的に予測することが困難であり、それらの測定と修正を困難にする可能性があります。これらの解釈可能性のツールは、これらの関連性や曖昧さのいくつかを事前に発見することにより、機械学習の実践者が潜在的な問題を先取りする能力を支援する可能性があると信じています。
CLIPに対する私たち自身の理解はまだ発展途上であり、CLIPの大規模バージョンをリリースするかどうかの判断とリリースするとしたらどのようにリリースするかの決定に繋がります。リリースされたバージョンと本日発表するツールのコミュニティでのさらなる調査が、マルチモーダルシステムの一般的な理解を深め、私たち自身の意思決定に役立つことを願っています。
結論
論文「Multimodal Neurons in Artificial Neural Networks」の発行に加えて、CLIPを理解するために使用したツールのいくつかもリリースしています。
OpenAI Microscopeカタログは、すべてのニューロンの特徴の視覚化、データセットの事例、CLIPRN50x4のテキスト特徴の視覚化が追加更新されています。また、このような研究にさらに対応するために、CLIPRN50x4およびRN101の重みもリリースしています。これらのCLIPの調査は、CLIPの動作を理解する上で表面的なものに過ぎないと考えており、CLIPとそのようなモデルの理解を深めるために研究コミュニティに参加することをお勧めします。
3.文字情報と画像情報を同じ概念として認識できる人工知能の出現(2/2)関連リンク
1)openai.com
Multimodal Neurons in Artificial Neural Networks
2)distill.pub
Multimodal Neurons in Artificial Neural Networks
3)microscope.openai.com
OpenAI Microscope
4)github.com
openai / CLIP-featurevis

