
1.LEAF:人間の聴覚用の設定を学習システムに置き換えてオーディオ分類の性能を向上(1/2)まとめ
・音声分類用のモデルは生音声ではなく前処理されたデータを扱う事が多い
・メルフィルターバンクは人間の聴覚反応を再現するように設計されたフィルタ
・人間の耳を模倣することが重要ではない領域では悪影響を与える可能性があった
2.LEAFとは?
以下、ai.googleblog.comより「LEAF: A Learnable Frontend for Audio Classification」の意訳です。元記事の投稿は2021年3月12日、Neil Zeghidourさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Jason Strull on Unsplash
音声を理解するための機械学習(ML:Machine Learning)モデルの開発は、過去数年間で大きな進歩を遂げました。データからパラメータを学習する機能を活用して、この分野は、従来の複合的に人間が手動で設計したシステムから、音声の認識、音楽の理解、鳥の鳴き声などの動物の鳴き声の分類に使用される今日のディープラーニングを使った分類器に徐々に移行しています。
ただし、生の画素から学習できるコンピュータービジョンモデルとは異なり、音声分類用のディープニューラルネットワークが生の音声波形からトレーニングされることはめったにありません。代わりに、メルフィルターバンク(mel filterbanks)の形式で前処理されたデータに依存しています。これは、人間の聴覚反応のいくつかの側面を再現するように設計された、手作りのメルスケールのスペクトログラム(mel-scaled spectrograms)です。
MLタスク用のメルフィルターバンクのモデリングは歴史的に成功していますが、一部を固定化している事に起因するバイアスによって制限されています。固定したメル尺度と対数圧縮を使用することは一般にうまく機能しますが、それらが目的とするタスクに最適な特徴表現を提供するという保証はありません。
具体的には、人間の知覚を一致させることは、音声認識や音楽の理解など、一部のアプリケーション領域に優れた誘導バイアスを提供します。しかし、これらのバイアスは、人間の耳を模倣することが重要ではない領域、例えばクジラの歌の認識などに悪影響を与える可能性があります。
従って、最適なパフォーマンスを実現するには、メルフィルターバンクを目的のタスクに合わせて調整する必要があります。これは、専門家が専門領域の知識に基づいて反復的な作業を行う事を必要とする面倒なプロセスです。
結果として、標準のメルフィルターバンクは、最適ではありませんが、実際にはほとんどのオーディオ分類タスクに使用されます。更に、研究者はこれらの問題に対処するためにTime-Domain Filterbanks、SincNet、WavegramなどのMLシステムを提案していますが、従来のメルフィルターバンクのパフォーマンスにはまだ匹敵していません。
ICLR 2021で受理された論文「LEAF, A Fully Learnable Frontend for Audio Classification」では音声理解タスク用の学習可能なスペクトログラムを作成するための代替方法を紹介します。
LEAF(LEarnable Audio Frontend)は、メルフィルターバンクを近似するように初期化でき、その後、モデル全体に少数のパラメーターを追加するだけで、目前のタスクに適応するように任意のオーディオ分類器と共同でトレーニングできるニューラルネットワークです。
LEAFスペクトログラムは、音声、音楽、鳥の鳴き声など、幅広いオーディオ信号と分類タスクで、固定メルフィルターバンクや以前に提案された学習可能なシステムよりも分類パフォーマンスが向上することを示しています。TensorFlow 2でコードを実装し、GitHubリポジトリを通じてコミュニティにリリースしました。
Mel Filterbanks:音声に関する人間の知覚を模倣する
メルフィルターバンクを作成するための従来のアプローチの最初のステップは、ウィンドウ処理によって音の時間変動を捕捉することです。つまり、信号を固定期間の短い断片に分割します。次に、ウィンドウ化された各断片を固定周波数フィルターのバンクに通すことによってフィルタリングを実行し、音程に対する人間の対数感度を複製します。
私達は高周波数よりも低周波数の変動に敏感であるため、メルフィルターバンクは低周波数範囲の音をより重要視します。最後に、音声信号は、ラウドネスに対する耳の対数感度を模倣するように圧縮されます。人が3デシベルの増加を知覚するには、音のパワーを2倍にする必要があります。
LEAFは、メルフィルターバンク生成に対するこの従来のアプローチに大まかに従いますが、固定化した操作(つまり、フィルターレイヤー、ウィンドウレイヤー、および圧縮関数)のそれぞれを学習済みの対応物に置き換えます。LEAFの出力は、メルフィルターバンクに似た時間周波数表現(スペクトログラム)ですが、完全に学習可能です。
従って、例えば、メルフィルターバンクは音程に固定スケールを使用しますが、LEAFは対象のタスクに最適なスケールを学習します。入力特徴表現としてメルフィルターバンクを使用してトレーニングできるモデルは全て、LEAFスペクトログラムでトレーニングすることもできます。
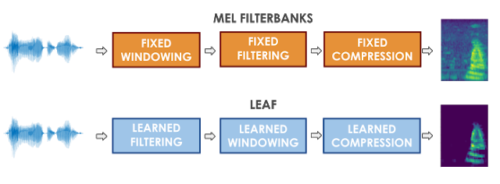
LEAFスペクトログラムと比較したメルフィルターバンクの概要図
3.LEAF:人間の聴覚用の設定を学習システムに置き換えてオーディオ分類の性能を向上(1/2)関連リンク
1)ai.googleblog.com
LEAF: A Learnable Frontend for Audio Classification
2)arxiv.org
LEAF: A Learnable Frontend for Audio Classification
3)github.com
google-research / leaf-audio

