
1.ニューラルネットワークを疎にして推論を高速化(2/2)まとめ
・密なバージョンから重みの一部を徐々にゼロにしていく事がスパース化のコツ
・トレーニング時間の増加で品質を低下させることなく深層学習モデルをスパース化可能
・スパースネットワークの品質は時間、学習率、剪定などのハイパーパラメータの影響を受ける
2.スパースニューラルネットワークをトレーニングするコツ
以下、ai.googleblog.comより「Accelerating Neural Networks on Mobile and Web with Sparse Inference」の意訳です。元記事の投稿は2021年3月9日、Artsiom AblavatskiさんとMarat Dukhanさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Robert Anasch on Unsplash
スパースニューラルネットワークをトレーニングするためのガイドライン
本リリースに含まれるスパースニューラルネットワークを作成するためのガイドラインでは、密なバージョンから始めて、トレーニング中にその重みの一部を徐々にゼロに設定することを提案しています。
このプロセスは剪定(pruning)と呼ばれます。剪定に利用できる多くの手法のうち、マグニチュード剪定(magnitude pruning、TF Model Optimization Toolkitで利用可能)または最近紹介されたRigL手法を使用することをお勧めします。
トレーニング時間の適度な増加により、これらは両方とも、品質を低下させることなく深層学習モデルを正常にスパース化できます。結果として得られるスパースモデルは、圧縮形式で効率的に保存でき、高密度のモデルと比較してサイズが2分の1に削減されます。
スパースネットワークの品質は、トレーニング時間、学習率、剪定のスケジュールなど、いくつかのハイパーパラメータの影響を受けます。TF Pruning APIは、これらを選択する方法の優れた例と、そのようなモデルをトレーニングするためのヒントを提供します。ハイパーパラメータ検索を実行して、アプリケーション用に適切な設定値を見つけることをお勧めします。
アプリケーション
分類タスク、密なセグメンテーション(例えば、Google Meetの背景のぼかし)、回帰問題(MediaPipe Hands)をスパース化できることを示します。これにより、ユーザーに具体的なメリットがもたらされます。例えば、Google Meetの場合、スパース化によりモデルの推論時間が30%短縮され、より多くのユーザーがより高品質な通話を利用可能になりました。
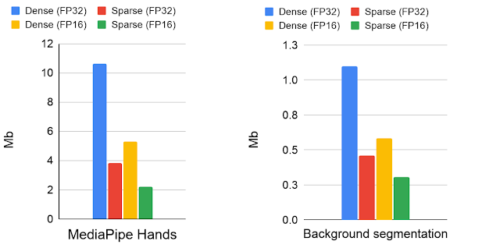
密モデルと疎モデルのモデルサイズのメガバイト単位での比較
モデルは、16ビットおよび32ビットの浮動小数点形式で格納されています。
ここで説明するスパース性へのアプローチは、MobileNetV2、MobileNetV3、EfficientNetLiteなどの反転残余ブロック(inverted residual blocks)に基づくアーキテクチャで最適に機能します。
ネットワークのスパース性の程度は、推論の速度と品質の両方に影響します。固定容量の高密度ネットワークから始めて、30%のスパース性でも適度なパフォーマンスの向上が見られました。スパース性が高くなると、モデルの品質は70%のスパース性に達するまで、比較対象とした密モデルにほぼ近い精度を維持します。それを超えると、精度は更に低下します。
ただし、元となるネットワークのサイズを20%増やすことで、70%のスパース性における精度の低下を補うことができます。これにより、モデルの品質を低下させることなく、推論時間が短縮されます。XNNPACKはスパース推論を認識して自動的に有効にすることができるため、スパース化されたモデルを実行するためにこれ以上の変更は必要ありません。
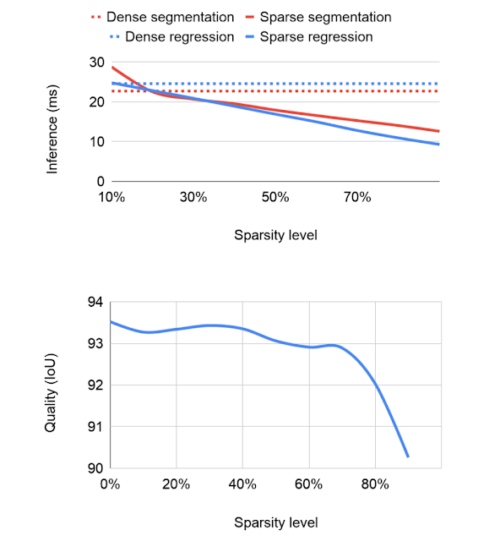
推論時間(小さいほど優れている)および予測されたセグメンテーションマスクのIntersection over Union(IoU)によって測定された品質に関するさまざまなスパース性レベルのアブレーション研究
蒸留手法を自動化する疎な手法
Google Meetの背景のぼかしは、アテンションブロックを備えた変更されたMobileNetV3バックボーンに基づくセグメンテーションモデルを使用します。
前景マスクの品質を維持しながら、70%のスパース化を適用することで、モデルを30%高速化する事ができました。17の地理的サブリージョンからの画像で疎モデルと密モデルの予測を調べたところ、有意差は見られませんでした。関連するモデルカードで詳細を公開します。
同様に、MediaPipe Handsは、EfficientNetLiteバックボーンに基づくモデルを使用して、モバイルおよびWeb上でリアルタイムで手のひらの特徴を予測します。
このバックボーンモデルは、計算コストの高い反復プロセスである大規模な高密度モデルから手動で抽出されました。蒸留手法は適用されたものの代わりに密なモデルの疎なバージョンを使用して、同じ推論速度を維持することができました。その際、密なモデルを蒸留するという労働集約的なプロセスはありませんでした。
密なモデルと比較して、疎なモデルは推論を2倍改善し、蒸留されたモデルと同じ品質を達成しました。ある意味で、スパース化は、非構造化モデルを蒸留する手法を自動化するアプローチと考えることができます。これにより、手作業をあまり行わなくてもモデルのパフォーマンスを向上させることができます。地理的に多様なデータセットでスパースモデルを評価し、モデルカードを公開しました。

同じ品質の密(左、dencs)、蒸留(中央、distilled)、および疎(右、sparse)モデルの実行時間の比較。密モデルの処理時間は、疎モデルまたは蒸留モデルの2倍です。蒸留されたモデルは、MediPipeの公式ページから取得されました。密で疎なWebデモはmediapipe.devで公開されています。
今後の作業
スパース化は、ニューラルネットワークのCPU推論を改善するためのシンプルでありながら強力な手法であることがわかりました。スパース推論により、エンジニアはパフォーマンスやサイズに大きなオーバーヘッドを発生させることなく、より大きなモデルを実行できるため、有望な新しい研究の方向性となります。XNNPACKは、CHWレイアウトでの操作をより幅広くサポートするように拡張を続けており、量子化などの他の最適化手法とどのように組み合わせることができるかを模索しています。このテクノロジーで何を構築できるかを楽しみにしています。
謝辞
このプロジェクトに携わったすべての人に感謝します。
Karthik Raveendran, Erich Elsen, Tingbo Hou, Trevor Gale, Siargey Pisarchyk, Yury Kartynnik, Yunlu Li, Utku Evci, Matsvei Zhdanovich, Sebastian Jansson, Stéphane Hulaud, Michael Hays, Juhyun Lee, Fan Zhang, Chuo-Ling Chang, Gregory Karpiak, Tyler Mullen, Jiuqiang Tang, Ming Guang Yong, Igor Kibalchich, 及び Matthias Grundmann.
3.ニューラルネットワークを疎にして推論を高速化(2/2)関連リンク
1)ai.googleblog.com
Accelerating Neural Networks on Mobile and Web with Sparse Inference
2)arxiv.org
On-Device Neural Net Inference with Mobile GPUs
Fast Sparse ConvNets
3)github.com
google / XNNPACK
