
1.シネマティック フォトの背後にある技術(1/2)まとめ
・昨年12月Googleフォトの新機能としてシネマティック フォトが公開された
・人物を背景から切り離して動かす事で写真を撮った当時の没入感を再現
・Google フォトの上部に出る「思い出」に選ばれた写真に適用可能
2.シネマティック フォトとは?
以下、ai.googleblog.comより「The Technology Behind Cinematic Photos」の意訳です。元記事の投稿は2021年2月23日、Per KarlssonさんとLucy Yuさんによる投稿です。
没入感を感じられたので選んだアイキャッチ画像のクレジットはPhoto by Jan Kopřiva on Unsplash
過去の写真を見る事は、人々が最も大切な瞬間を思い出すのに役立ちます。
昨年12月、Googleフォトの新機能としてシネマティック フォト(Cinematic photos)をリリースしました。これは、写真を撮った瞬間の没入感を取り戻すことを目的としており、画像の3D表現を推測することでカメラの動きと視差をシミュレートします。本投稿では、このプロセスの背後にあるテクノロジーを見て、Cinematic photosが過去の1枚の2D写真をより没入感のある3Dアニメーションに変える方法を示します。
カメラの3Dモデル。Rick Reitanoの厚意による掲載
奥行の推定
ポートレートモードや拡張現実(AR:Augmented Reality)などの最近の多くの計算写真機能と同様に、Cinematic photosでは、風景の3D構造に関する奥行情報を提供するために深度マップが必要です。
スマートフォンで深度を計算するための一般的な手法は、マルチビューステレオに依存しています。これは、カメラ間の距離がわかっている様々な視点で複数の写真を同時に撮影することにより、三角測量の原理で風景内の物体の深度を解決する幾何学的手法です。Pixelスマートフォンでは、視点は2台のカメラまたはデュアルピクセルセンサーから取得されます。
マルチビューステレオで撮影されなかった既存の写真でCinematic photosを有効にするために、エンコーダーデコーダーアーキテクチャを使用して畳み込みニューラルネットワークをトレーニングし、単一のRGB画像から深度マップを予測しました。モデルは、1つの視点のみを使用して、物体の相対サイズ、線形遠近法、焦点ぼけなどの単眼キュー(Monocular cues)を使用して深度を推定することを学習しました。
単眼深度推定データセットは通常、AR、ロボット工学、自動運転などの研究領域向けに設計されています。そのため、人、ペット、物体など、カジュアルな写真で一般的な特徴を持つ写真ではなく、構図やフレーミングが異なるストリートシーンや室内のシーンを強調する傾向があります。
そこで、5つのカメラを使ったカスタム撮影システムで撮影した写真とPixel 4で撮影したポートレート写真の別のデータセットを使用して、単眼深度モデルをトレーニングするための独自のデータセットを作成しました。両方のデータセットには、マルチビューステレオから撮影した真の深度情報が含まれています。これはモデルのトレーニングに不可欠です。
このように複数のデータセットを混合すると、モデルが様々な風景やカメラハードウェアにさらされ、実世界の写真を使った際のの予測が向上します。
ただし、異なるデータセットからの真実の奥行情報は、未知のスケーリング係数とシフトによって互いに異なる可能性があるため、新しい課題も発生します。幸い、Cinematic photosエフェクトには、風景内の物体の相対的な深さのみが必要であり、絶対的な深さは必要ありません。従って、トレーニング中にスケールとシフト不変の損失を使用してデータセットを結合し、推論時にモデルの出力を正規化できます。
Cinematic photosエフェクトは、人物の境界での深度マップの精度に特に敏感です。深度マップにエラーがあると、最終的にレンダリングされたエフェクトに不快な人工的効果が生じる可能性があります。これを軽減するために、中央値フィルタリングを適用してエッジを改善し、Open ImagesデータセットでトレーニングされたDeepLabセグメンテーションモデルを使用して、写真内の人物のセグメンテーションマスクを推測します。マスクは、バックグラウンドにあると誤って予測された深度マップの画素を前方に引き戻すために使用されます。
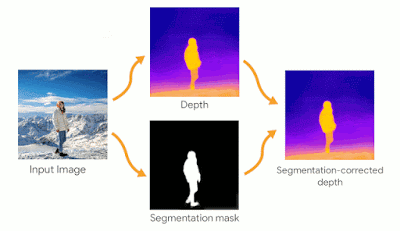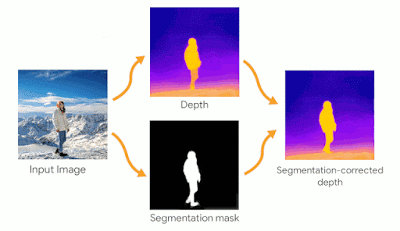
カメラの軌跡
3Dシーンでカメラをアニメーション化する場合、多くの自由度があります。仮想カメラの設定は、映画のような動きを作成するためにプロが使用するビデオカメラシステムに触発されています。その一環として、被写体に目を向けて最良の結果を得るために、仮想カメラの回転に最適なピボットポイントを特定します。

3.シネマティック フォトの背後にある技術(1/2)関連リンク
1)ai.googleblog.com
The Technology Behind Cinematic Photos

