
1.Model Search:最適なMLモデルを見つけるためのオープンソースプラットフォーム(2/2)まとめ
・Model Searchは自分で選択したアーキテクチャで構築された新しい探索スペースも利用可能
・Model Searchに実装されている探索アルゴリズムは強化学習よりも速く収束する
・特定の研究領域に関する知識に基づいてモデル探索ができるので効率的なモデル探索が可能
2.Model Searchの性能
以下、ai.googleblog.comより「Introducing Model Search: An Open Source Platform for Finding Optimal ML Models」の意訳です。元記事の投稿は2021年2月19日、Hanna MazzawiさんとXavi Gonzalvoさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Fred Moon on Unsplash
Model SearchフレームワークはTensorflowに基づいて構築されているため、各ブロックはテンソルを入力として受け取る任意の関数を実装できます。
例えば、自分で選択したマイクロアーキテクチャで構築された新しい探索スペースを使いたいとします。フレームワークは、新しく定義されたブロックを取得して探索プロセスに組み込み、アルゴリズムが提供されたコンポーネントから可能な限り最高のニューラルネットワークを構築できるようにします。提供されるブロックは、対象の問題に対して機能することがすでに知られている完全に定義されたニューラルネットワークにすることもできます。その場合、モデル検索は、強力なアンサンブルマシンとして機能するように構成できます。
Model Searchに実装されている探索アルゴリズムは、適応性があり、貪欲でインクリメンタルであるため、RLアルゴリズムよりも速く収束します。
ただし、RLアルゴリズムの「探索と活用(explore & exploit)」の性質を模倣しています。「良い候補の検索(探索ステップ)」と「発見された良い候補をアンサンブルして精度を高める(活用ステップ)」事を分離してこれを行います。メインの探索アルゴリズムは、アーキテクチャまたはトレーニング手法にランダムな変更(例えば、アーキテクチャをより深くする)を適用した後、実行中の上位k個の実験(kはユーザーが指定できます)の1つを適応的に変更します。

多くの実験を行ってネットワークが進化する例
各色は、異なるタイプのアーキテクチャブロックを表します。最終的なネットワークは、パフォーマンスの高い候補ネットワークの突然変異によって形成されます。この場合、深さが増します。
効率と精度をさらに向上させるために、様々な内部実験間で転移が有効になっています。Model Searchは、知識の蒸留(Knowledge distillation)または重みの共有という2つの方法でこれを行います。
知識の蒸留により、真実のラベルに加えて、パフォーマンスの高いモデルの予測に一致する損失項を追加する事で、候補者の精度を向上させることができます。
一方、重みの共有は、以前にトレーニングされたモデルから適切な重みをコピーし、残りのモデルをランダムに初期化することにより、以前にトレーニングされた候補からネットワーク内のパラメーターの一部を(突然変異を適用した後)強化します。これにより、より高速なトレーニングが可能になり、より多くの(そしてより良い)アーキテクチャを発見する機会が得られます。
実験結果
Model Searchは、最小限の反復で本番モデルを改善します。 最近の論文では、キーワードスポッティング(訳注:重要なキーワードのみを取り出す音声認識手法)と言語識別のモデルを発見することにより、音声ドメインでのモデル検索の機能を実証しました。200回未満の反復で、結果のモデルは、約130K少ないパラメーター(315Kパラメーターと比較して184K)を使用してトレーニング可能でした。これは精度の専門家によって設計された内部の最先端の製品モデルをわずかに改善しています。
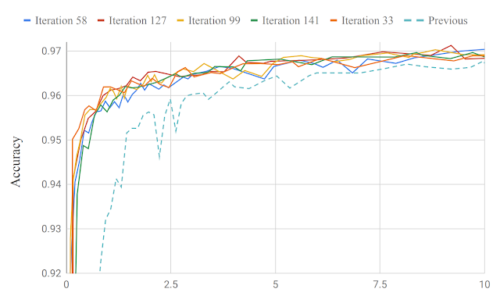
キーワードスポッティングの以前の製品モデルと比較した、システムで反復を行って得たモデルの精度。論文で言語識別について同様のグラフを見つけることができます。
また、Model Searchを適用して、徹底的に調査されたCIFAR-10画像データセットの画像分類に適したアーキテクチャを見つけました。畳み込み、resnetブロック(つまり、2つの畳み込みとスキップ接続)、NAS-Aセル、完全接続レイヤーなどを含む一連の既知の畳み込みブロックを使用して、91.83のベンチマーク精度にすばやく到達できることを確認しました。209回の試行(つまり、209個のモデルのみを調査)です。比較すると、以前のトップパフォーマーは、NasNetアルゴリズム(RL)では5807回の試行で、PNAS(RL +プログレッシブ)では1160回の試行で同じしきい値精度に達しました。
結論
Model Searchのコードが、MLモデル発見のための柔軟で研究領域にとらわれないフレームワークを研究者に提供することを願っています。特定の研究領域に関する従来の知識に基づいて構築することにより、このフレームワークは、標準のビルディングブロックで構成される探索スペースが提供された場合に、十分に研究された問題に対する最先端のパフォーマンスを備えたモデルを構築するのに十分強力であると考えています。
謝辞
オープンソースと論文へのすべてのコード貢献者に特に感謝します。
Eugen Ehotaj, Scotty Yak, Malaika Handa, James Preiss, Pai Zhu, Aleks Kracun, Prashant Sridhar, Niranjan Subrahmanya, Ignacio Lopez Moreno, Hyun Jin Park, and Patrick Violette。
3.Model Search:最適なMLモデルを見つけるためのオープンソースプラットフォーム(2/2)関連リンク
1)ai.googleblog.com
Introducing Model Search: An Open Source Platform for Finding Optimal ML Models
2)github.com
google / model_search

