
1.World Models Library:強化学習で将来の画像を予測する事に意味はあるのか?(2/2)まとめ
・エージェントが予測する画像の画素数が増えるとパフォーマンスは一般的に向上
・報酬予測の精度とエージェントのパフォーマンスの間の相関はそれほど強くなかった
・オフライン設定とオンライン設定でパフォーマンスを発揮するモデルが異なる事もわかった
2.World Models Libraryとは?
以下、ai.googleblog.comより「Evaluating Design Trade-offs in Visual Model-Based Reinforcement Learning」の意訳です。元記事の投稿は2021年2月3日、Mohammad BabaeizadehさんとDumitru Erhanさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Antonella Vilardo on Unsplash
ライブラリには、プラットフォームに依存しない視覚的なMBRLシミュレーションループとAPIを導入して新しいワールドモデル、プランナー、タスクをシームレスに定義したり、エージェント(PlaNetなど)やビデオモデル(SV2Pなど)、およびCEMやMPPIなどの様々なDeepMind Controlタスクとプランナーが含まれます。
開発者は、ライブラリを使用して、モデル設計や特徴表現空間など、MBRLの様々な要素が一連のタスク内でエージェントのパフォーマンスに与える影響を調べることができます。ライブラリは、エージェントのゼロからのトレーニング、または事前に収集された一連の軌道でのトレーニング、および特定のタスクでの事前トレーニングされたエージェントの評価をサポートします。モデル、計画アルゴリズム、およびタスクは、簡単に組み合わせて、任意の組み合わせに一致させることができます。
ユーザーに最大の柔軟性を提供するために、ライブラリはNumPyインターフェースを使用して構築されています。これにより、TensorFlow、Pytorch、またはJAXのいずれかにさまざまなコンポーネントを実装できます。簡単な紹介については、このgithubで公開されているcolabをご覧ください。
画像予測の影響
World Models Libraryを使用して、様々なレベルの画像予測で複数の世界モデルをトレーニングしました。これらのモデルはすべて、同じ入力(以前に観測された画像)を元に将来の画像と報酬を予測しますが、予測する画像の割合が異なります。
エージェントによって予測される画像の画素数が増えると、真の報酬によって測定されるエージェントのパフォーマンスは一般に向上します。
モデルへの入力は固定(以前に観測された画像)されていますが、予測される画像の割合は異なります。右のグラフに示されているように、予測される画素の数を増やすと、モデルのパフォーマンスが大幅に向上します。
興味深いことに、報酬予測の精度とエージェントのパフォーマンスの間の相関はそれほど強くなく、場合によっては、より正確な報酬予測によってエージェントのパフォーマンスが低下することさえあります。同時に、画像再構成エラーとエージェントのパフォーマンスの間には強い相関関係があります。
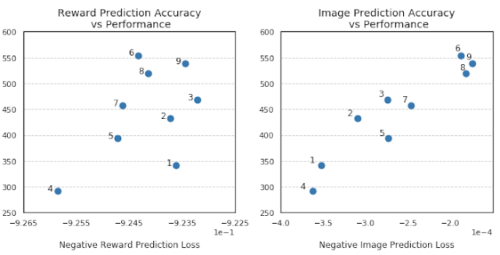
画像/報酬予測の精度(x軸)とタスクのパフォーマンス(y軸)の間の相関
このグラフは、画像予測の精度とタスクのパフォーマンスの間に強い相関関係があることを明確に示しています。
この現象は、探索時の行動に直接関係しています。つまり、エージェントが環境内の未知の選択肢に関するより多くの情報を収集するために、よりリスクが高く、報酬が少ない可能性のあるアクションを試みていると言う事です。
これは、オフライン強化学習(つまり、環境と対話することでポリシーを学習するオンライン強化学習とは対照的に、事前に収集されたデータセットからポリシーを学習)でモデルをテストおよび比較することで示すことができます。
オフライン設定では、探索は行われず、全てのモデルは同じデータを使ってトレーニングされます。私達はデータに良く適合出来るモデルはオフライン設定でパフォーマンスが向上する事を観察しました。驚くべきことに、これらは、ゼロから学習して探索する設定で最高のパフォーマンスを発揮するモデルとは異なる場合があります。
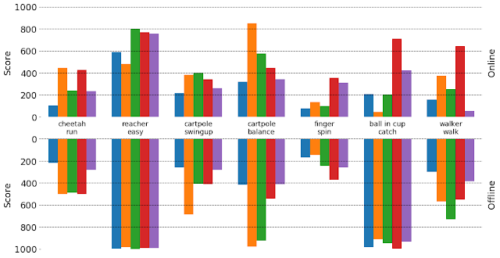
様々なタスクにわたってさまざまなビジュアルMBRLモデルによって達成されたスコア
グラフの上半分と下半分は、各タスクのオンライン設定とオフライン設定でそれぞれトレーニングしたときに達成されたスコアを視覚化します。各色は異なるモデルです。オンライン設定でパフォーマンスの低いモデルが、事前に収集されたデータ(オフライン設定)でトレーニングされたときに高スコアを達成することは一般的であり、その逆も同様です。
結論
画像を予測することで、期待される報酬のみを予測するモデルよりもタスクのパフォーマンスを大幅に向上できることを経験則的に示しました。 また、画像予測の精度は、これらのモデルの最終的なタスクのパフォーマンスと強く相関することも示しました。これらの調査結果は、より良いモデル設計に使用でき、入力空間が高次元でデータの収集に費用がかかる状況で特に役立ちます。
独自のモデルや実験を開発したい場合は、リポジトリとコラボにアクセスしてください。本研究を再現し、World Models Libraryを使用または拡張する方法について説明しています。
謝辞
Google Brainチームの複数の研究者と、この論文の共著者であるに特別な功績に感謝します。Mohammad Taghi Saffar, Danijar Hafner, Harini Kannan, Chelsea Finn, Sergey Levine。
3.World Models Library:強化学習で将来の画像を予測する事に意味はあるのか?(2/2)関連リンク
1)ai.googleblog.com
Evaluating Design Trade-offs in Visual Model-Based Reinforcement Learning
2)arxiv.org
Models, Pixels, and Rewards: Evaluating Design Trade-offs in Visual Model-Based Reinforcement Learning
3)github.com
google-research / world_models

