
1.より少ないデータから表形式データを推論することを学習(2/2)まとめ
・パフォーマンスを向上させるために反事実条件と合成の2つの新しい事前トレーニングを導入
・経験則を用いてデータの一部分のみを使って計算効率を最適化出来ないかを調査
・トークン数を半分にする事で精度の低下抑えつつ2倍高速化、1/4にする事で4倍高速化を実現
2.反事実条件タスクと合成タスク
以下、ai.googleblog.comより「Learning to Reason Over Tables from Less Data」の意訳です。元記事の投稿は2021年1月29日、Julian Eisenschlosさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Jose Losada on Unsplash
表形式データに対するモデルのパフォーマンスを向上させるために、反事実条件(counterfactual)と合成(synthetic)と呼ばれる2つの新しい事前トレーニング二項分類タスクを導入します。これらは事前トレーニングの第2段階(intermediate pre-training、中間事前トレーニングと呼ばれることが多い)として適用できます。
反事実的タスクでは、ウィキペディアから、特定のテーブルに表示される実体(人、場所、または物)に言及する関連文を収集します。次に、50%の確率で、実体を何か別のものに交換することで関連文を変更します。
置換後の関連文が現実的な文章に見えるようにするために、表内の同じ列にある実体中から置換候補を選択します。
モデルは、関連文が変更されたかどうかを認識するようにトレーニングされます。この事前トレーニングタスクには、そのような事例が何百万も含まれており、これらについて推論する事は複雑なタスクではありませんが、文章そのものは自然に見えます。
合成タスクでは、単純な文法規則のセットを使用して関連文を生成するセマンティック解析と同様の手法を使います。
モデルは合計や平均などの基本的な数学演算を理解する(例:「収益の合計」など)、または、何らかの条件(「国はオーストラリア」など)を使用してテーブル内の要素をフィルタリングする方法を理解する必要があります。
これらの関連文は人為的なものですが、モデルの数値的および論理的推論スキルの向上に役立ちます。

2つの新しい事前トレーニングタスクの実例
反事実的(Counterfactual)タスクの事例では、入力テーブルに付随する関連文内で言及されている実体を、もっともらしい代替語と交換します。合成(Synthetic)タスクでは、文法規則を使用して、テーブルの情報を複雑な方法で組み合わせる必要がある新しい文を作成します。
結果
TAPASモデルを基準とし、テキスト含意領域で成功を示した2つの従来モデル、LogicalFactChecker(LFC)とStructure Aware Transformer(SAT)を比較することにより、TabFactデータセットでの反事実的および合成の事前トレーニング目標の成果を評価しました。
TAPASモデルは、LFCおよびSATと比較してパフォーマンスが向上していますが、事前トレーニング済みモデル(TAPAS + CS)のパフォーマンスは大幅に向上しており、新しい最先端の性能を実現しています。
また、TAPAS + CSをSQAデータセットの質問回答タスクに適用しました。このタスクでは、モデルは質問を受けて表データ内から回答を見つける必要があります。CSを学習目標に含めると、従来の最高パフォーマンスが4ポイント以上向上できます。これは、このアプローチがテキスト含意だけでなくパフォーマンスも一般化することを示しています。
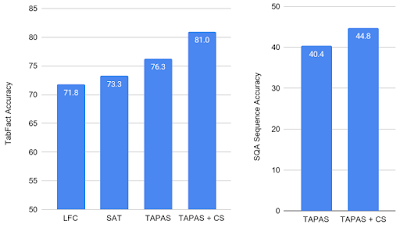
TabFact(左)とSQA(右)の結果
合成データセットと反事実データセットを使用して、両方のタスクで新たに大幅に更新した最先端の結果を達成します。
データと計算効率
反事実タスクおよび合成タスクで事前トレーニングする事のもう1つの側面は、モデルがすでに二項分類用に調整されているため、TabFactに微調整することなく適用できることです。
データの一部のみ(またはデータなし)でトレーニングした場合に、各モデルがどの程度の性能を出せるのかを調べてみました。データなしでもTAPAS + CSモデルは、強力な比較対象モデルであるTable-Bertと競合する性能を発揮し、データの10%のみを使った場合でも、従来の最先端技術に匹敵する性能でした。
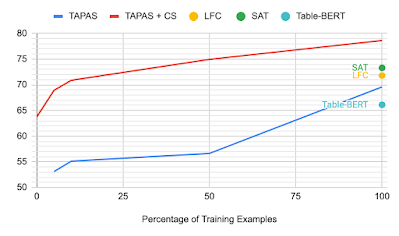
学習データの使用割合とTabFactの精度のグラフ
このような大きなモデルを使用してテーブルを操作しようとする際の一般的な懸念は、計算要件が高いため、非常に大きなテーブルを解析する事が困難になることです。
これに対処するために、経験則を用いて入力の一部分を選択してモデルが処理するデータのサイズを減らし、計算効率を最適化する事が出来るかを調査しました。
入力をフィルタリングするための様々なアプローチを体系的に調査し、「列全体」と「表の名称に関する文」の間の単語の重複を高めるように選択する単純な方法が最良の結果をもたらすことを発見しました。どのトークンを入力に含めるかを動的に選択することで、使用するリソースを減らしたり、同じコストでより大きな入力を処理したりできます。課題は、重要な情報を失ったり、精度を損なう事なくこれを実現する事です。
例えば、前述のモデルはすべて512トークンのシーケンスを使用します。これは、transformer モデルの通常の制限に近いものです。(ただし、ReformerやPerformerなどの最近の効率化手法は入力サイズの規模を拡大するために効果的であることが証明されています)
本稿で提案する列選択方法は、TabFactで高精度を達成しながら、より高速なトレーニングを可能にします。
256個の入力トークンの場合、精度の低下はごくわずかですが、モデルを事前にトレーニング、微調整して、予測を最大2倍高速化できるようになりました。
128トークンを使用すると、モデルは精度で以前の最先端モデルを依然として上回っていますが、更に大幅なスピードアップを実現し、全体で4倍高速になります。
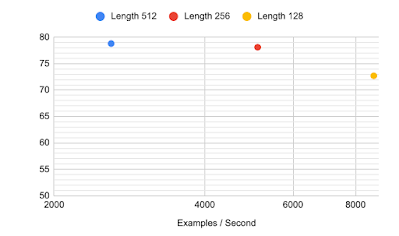
列選択方法で入力を短縮する事で実現した、様々なシーケンス長を使用したTabFactの精度
今回提案した列選択方法と新しい事前トレーニングタスクの両方を使用して、より良い結果を得るために必要なデータと計算能力が少ないテーブル解析モデルを作成できます。
GitHubリポジトリで新しいモデルと事前トレーニング手法を利用できるようにしています。tiny.ccでは、colabを使って実際に試すことができます。本手法をより利用しやすくするために、様々なサイズのモデルを「小さなモデル」まで共有しました。これらの結果が、より広範な研究コミュニティの間でテーブル推論の開発に拍車をかけるのに役立つことを願っています。
謝辞
この作業は、チューリッヒの言語チームのJulian Martin Eisenschlos, Syrine Krichene and Thomas Müllerrによって実施されました。Jordan Boyd-Graber, Yasemin Altun, Emily Pitler, Benjamin Boerschinger, Srini Narayanan, Slav Petrov, William Cohen and Jonathan Herzigの有益なコメントと提案に感謝します。
3.より少ないデータから表形式データを推論することを学習(2/2)関連リンク
1)ai.googleblog.com
Learning to Reason Over Tables from Less Data
2)www.aclweb.org
Understanding tables with intermediate pre-training
3)github.com
google-research/tapas
4)tiny.cc
tapas-tabfact-colab
5)twitter.com
@kdpsinghlab


余談なのですが、少し前にツイッターで以下のようなジョークを見かけたのです。
データサイエンティスト:統計学を使った事がありますか?
機械学習研究者:いいえ、使った事はないですね。
データサイエンティスト:論文を読むときはどうですか?
機械学習研究者:いいえ、全く使わないですね。
データサイエンティスト:わかりました。では、多くのモデルを比較する機械学習関連の論文を読んだ時、どのモデルがベストなのかをどのようにして知ることができるのですか?
機械学習研究者:太字で書かれている奴ですね。
最初はジョークとして笑ってしまったのですが、これって実は弱い教師アプローチの応用であり、このくらいの割り切りが必要なケースもあるのかな、と本稿を読んで考えを改めました。全てを完全に理解してから前に進むのが理想ですが、時間的制約が存在する中では、必ずしも実行可能な選択肢には成り得ません。
「単語の重複を高めるように選択する単純な方法が最良の結果」とは完全に経験則ですが、良い結果を出せているのであれば、こういった弱い教師信号を手がかりにしていくと言う選択肢を自分の中で持っておいた方が良い気がしてきています。
どちらが良い悪いではなく、時と場合によるとは思うのですが、一旦そこで立ち止まるのか、まだ自分には早いと諦めてしまうのか、わずかな灯りを手がかりに不格好でも前に歩み続けるのか?進む事によって見当違いな袋小路で無駄に時間をかける事になったり泥沼にハマってしまう事もあるかもしれません。しかし、進むにつれて灯りが増してくる可能性もあります。