
1.Pr-VIPE:異なる視点から撮影した画像間で人間の姿勢の類似性を認識(1/2)まとめ
・人間の姿勢を画像や動画などで2次元として撮影するとカメラの視点によって見え方が異なる
・二次元情報のみを使用して三次元ポーズの類似性を認識できると様々な応用ができる
・Pr-VIPEは人間のポーズを知覚する新しいアルゴリズムで二次元でも姿勢類似性を検出可
2.Pr-VIPEとは?
以下、ai.googleblog.comより「Recognizing Pose Similarity in Images and Videos」の意訳です。元記事の投稿は2021年1月14日、Jennifer J. SunさんとTing Liuさんによる投稿です。
動画内で繰り返されるポーズを認識する技術としてはTCCがありましたがPr-VIPEは異なった視点から撮影されたポーズを推定できると言う事です。
アイキャッチ画像のクレジットはPhoto by Andrey Zvyagintsev on Unsplash
ジョギングする事、本を読む事、水を注ぐ事、スポーツをする事、これらの日常の行動は、人の体の位置と向きからなる一連のポーズと見なすことができます。
画像やビデオからポーズを理解することは、拡張現実ディスプレイ、全身のジェスチャーを使った制御装置、運動量を数値として数える事など、様々なアプリケーションを実現するための重要なステップです。ただし、画像や動画で2次元として撮影した3次元のポーズは、カメラの視点によって異なって見えます。2D情報のみを使用して3Dポーズの類似性を認識する機能があれば、視覚システムが世界をよりよく理解するのに役立ちます。
ECCV 2020のスポットライトペーパーである論文「View-Invariant Probabilistic Embedding for Human Pose(Pr-VIPE)」では、人間のポーズを知覚するための新しいアルゴリズムを提示します。
Pr-VIPEは、二次元画像内の人体にキーポイントを設定し、それを視点不変のembedding空間の座標に変換する事により、様々なカメラ視点間での人体の姿勢の類似性を認識します。この機能により、ポーズの取得、アクションの認識、アクションのビデオ同期などのタスクが可能になります。
同様に二次元ポーズのキーポイントを三次元ポーズのキーポイントに直接割り当てるる既存のモデルと比較すると、Pr-VIPEEmbeddingスペースは以下の特徴があります。
(1)視点不変です。
(2)二次元入力のあいまいさを捕捉するために確率論的アプローチを用います
(3)トレーニングまたは推論中にカメラの視点方向などの追加パラメータを必要としません
研究施設内の設定データでトレーニングされたモデルは、適切で優れた2Dポーズ推定器(PersonLabやBlazePoseなど)があれば、難しい設定などをせずにすぐに現実世界の画像で動作させる事ができます。モデルはシンプルで、コンパクトなembeddingを使用しており、15個のCPUを使用して(1日以内で)トレーニングできます。GitHubリポジトリでコードを公開しています。

Pr-VIPEを直接適用して、様々な視点から撮影した同じポーズのビデオを整列させることができます。
Pr-VIPE
Pr-VIPEへの入力は、最低13の人体上のキーポイントを生成する任意の二次元ポーズ推定器が出力する二次元キーポイントであり、出力はポーズembeddingの平均と分散です。二次元ポーズのembedding空間内の距離は、完全な三次元ポーズ空間内でポーズの類似性と相関しています。私たちのアプローチは、以下の2つの観察に基づいています。
・同じ三次元ポーズは、視点が変わると二次元では大きく異なるように見える場合があります。
・同じ二次元ポーズを異なった三次元ポーズから投影できます。
最初の観察は、視点不変性の必要性を動機付けます。これを実現するために、一致確率、つまり、異なる二次元ポーズが同じまたは類似した三次元ポーズから投影された可能性を定義します。同じポーズ同士のペアを一致させるためには、異なったペア同士よりもPr-VIPEによって予測される一致確率を高くする必要があります。
2番目の観察に対処するために、Pr-VIPEは確率的なembeddingを利用します。何故なら、多くの三次元ポーズは、同じまたは類似した2Dポーズに投影できてしまうため、embedding空間で点と点を対応させるような割り当てを行うと、捕捉するのが難しい固有のあいまいさがモデルの入力に示されます。
従って、確率的マッピングを介して二次元ポーズをembedding分布に割り当てし、その分散を使用して入力二次元ポーズの不確実性を表します。例として、下の図では、左側の三次元ポーズの3番目の二次元視点は、右側の別の三次元ポーズの最初の二次元視点に似ています。そのため、両者はembedding空間内の近い場所に大きな分散で割り当てられます。
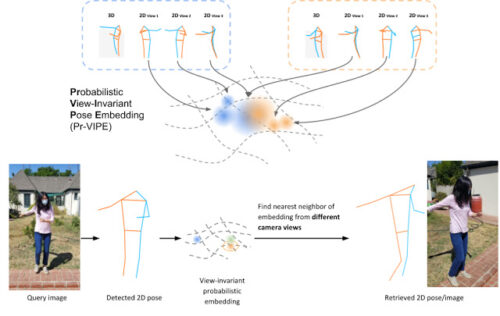
Pr-VIPEを使用すると、視覚システムは視点全体で二次元ポーズを認識できます。Pr-VIPEを使用して二次元ポーズをembedding化し、embeddingが(1)視点不変(類似した三次元ポーズの二次元投影がembedding空間内で互いに近接した場所に埋め込まれる)および(2)確率的であるようにします。Pr-VIPEは、検出された二次元ポーズをembedding化する事で、様々な視点からポーズ画像を直接取得できるほか、行動認識やビデオの整列にも適用できます。
3.Pr-VIPE:異なる視点から撮影した画像間で人間の姿勢の類似性を認識(1/2)関連リンク
1)ai.googleblog.com
Recognizing Pose Similarity in Images and Videos
2)arxiv.org
View-Invariant Probabilistic Embedding for Human Pose
3)github.com
POEM: Human POse EMbedding

