1.MediaPipe BlazePose:リアルタイムにオンデバイスでポーズを追跡(1/2)まとめ
・動画内の人間のポーズを推定する技術はARやフィットネス向けのアプリなどで重要
・BlazePoseは人体のポーズを知覚する新しい手法で既存技術より詳細なポーズ特定が可能
・detector-tracker MLパイプラインと頭部に関する仮定を行う事で高速に実行可能
2.MediaPipe BlazePoseとは?
以下、ai.googleblog.comより「On-device, Real-time Body Pose Tracking with MediaPipe BlazePose」の意訳です。元記事の投稿は2020年8月13日、Valentin BazarevskyさんとIvan Grishchenkoさんによる投稿です。
今回、トポロジー(Topology)の単語が良く出て来るのですが、人体のポーズに関する文脈で使われているので「形状」の意味ですね。ネットワークトポロジーなんて使われ方をする場合も「形状」の意味で良いですが、たまに数学的な文脈で使われると「位相~」になるのですが、これも物事の繋がり具合や位置関係的な概念なのでざっくりと形状のイメージで捉えておけば良いのかなと思います。
それにしても最新のAI技術がレオナルド・ダ・ビンチの有名なスケッチをヒントに設計されたというお話は大変面白いです。って事でウィトルウィウス的人体図にレオナルドの他の発明を加えたアイキャッチ画像のクレジットはPhoto by Вера Мошегова on Pixabay
2020年12月追記)その他のMediaPipeシリーズのまとめ記事はこちら。
動画内の人間のポーズを推定する事は、拡張現実(現実世界の上にデジタルコンテンツや情報を重ね合わせる手法)、手話認識、全身を使ったジェスチャーで制御可能な機器の開発や、ヨガ、ダンス、フィットネス向けのアプリケーションでトレーニングを行った回数を数値化する事もできます。
フィットネス用アプリケーションのポーズ推定は、多様なポーズ(例えば、数百種のヨガのアーサナ(ヨガの座法・体位))が可能である事、多様な自由度、オクルージョン(occlusion:カメラの視点が人体や他の物体に遮られて体全体が見えなくなってしまう事)、および様々な外観または服装があり得るため、特に困難です。


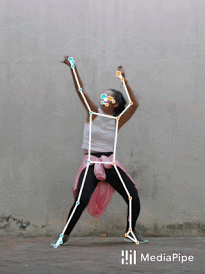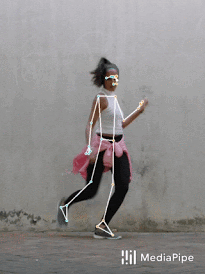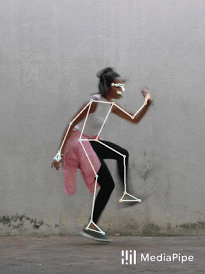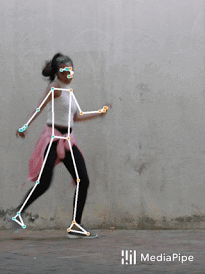
BlazePoseをフィットネスやダンスで使った結果
本日、CVPR 2020のCV4ARVRワークショップで発表した、人体のポーズを知覚する新しい手法であるBlazePoseのリリースを発表します。
私達のアプローチは、機械学習(ML:Machine Learning)を使用して、個々のフレーム内の人体に33か所のキーポイントを推測することにより、人間のポーズのトラッキングを行います。
標準的なCOCOトポロジーデータセット(COCO topology)に基づく現行のポーズモデルとは対照的に、BlazePoseはより多くのキーポイントを正確に位置特定できるため、フィットネスアプリケーションに非常に適しています。
更に、現在の最先端のアプローチは主に強力な計算能力を持つデスクトップPC環境に依存して推論を行っていますが、BlazePoseでは、スマートフォン上の比較的貧弱なCPU推論を使用してもリアルタイムで実行する事ができます。より強力なGPUを使って推論を行うと、BlazePoseはスーパーリアルタイムなパフォーマンスを実現し、顔面や手のひらなどを追跡する後続のMLモデルを実行できるようになります。
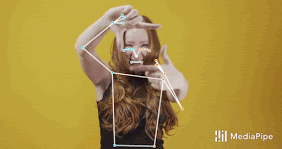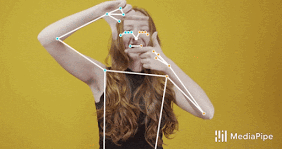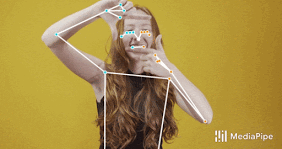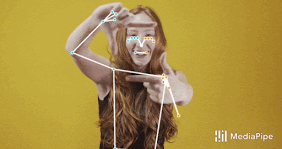

MediaPipeのUpper-body BlazePose(上半身BlazePose)モデル
トポロジー
人体のポーズを表現する際に使われるキーポイントの現在の事実上の標準はCOCOトポロジーデータセットです。COCOトポロジーでは、胴体、腕、脚、顔全体に17のキーポイントを持ちます。
ただし、COCOが使用しているキーポイントでは足首と手首のみを位置特定しており、手足の長さや向きの情報が不足しているため、フィットネスやダンスなどの実用的なアプリケーションには不向きです。より多くのキーポイントを含めることは、腕、顔面、脚などの領域で固有のポーズ推定を後処理で適用するためにも重要です。
BlazePoseでは、COCO、BlazeFace、BlazePalmトポロジのスーパーセットである33の人体キーポイントを用いた新しいトポロジを提示します。これにより、顔面や手のひら用のモデルとも一致するポーズ推定モデルが実現され、ポーズ推定のみを使ってボディランゲージなどの身体を使った表現も特定できます。
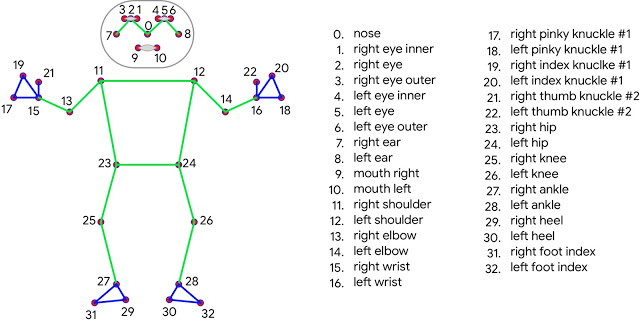
COCO(緑色)のスーパーセットとなるBlazePoseの33か所のキーポイント
ポーズ追跡用のMLパイプラインの概要
ポーズ推定には、手のひら追跡などで実績のある2ステップのdetector-tracker MLパイプラインを使用します。detectorを使用して、このパイプラインは最初にフレーム内のポーズの関心領域(ROI:Region Of Interest)を特定します。その後、trackerは、このROIから33全てのキーポイントを予測します。動画の場合は、ROI detectorは最初のフレームでのみ実行されることに注意してください。後続のフレームでは、以下で説明するように、前のフレームのポーズのキーポイントからROIを導出します。
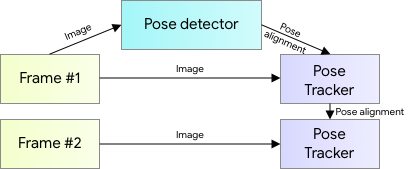
人体ポーズ推定パイプラインの概要
BlazeFaceの拡張によるポーズ検出
ポーズdetectorモデルとtrackerモデルで構成される完全なMLパイプラインでリアルタイムパフォーマンスを達成するために、各コンポーネントは非常に高速でなければならず、フレームあたり数ミリ秒しか使用できません。これを実現するために、私達は「胴体の位置」に関する最も強い信号をニューラルネットワークに対して発する場所は、人の顔である事に気付きました。(陰影がはっきりした特徴を持ち、見た目のばらつきが比較的小さいため)。
従って、私達は個々の画像内には頭部が写っているはずであるという強い仮定(多くのモバイルおよびWebアプリケーションで有効です)を行うことで、高速で軽量のポーズdetectorを実現しました。
その結果、ミリ秒未満で実行出来るBlazeFaceモデル開発時の顔検出器を、ポーズdetectorの代替としてトレーニングしました。このモデルはフレーム内の人物の位置を検出するだけであり、個人を識別する用途には使用できないことに注意してください。
予測されたキーポイントからROIを導出するFaceMeshやMediaPipe Handトラッキングパイプラインとは対照的に、人体のポーズトラッキングでは、2つの追加の仮想キーポイントを明示的に予測します。これは、人体の中心点と、回転と大きさを表現する円です。
レオナルド・ダ・ヴィンチが描いたウィトルウィウス的人体図(Leonardo’s Vitruvian man)から発想を得て、人の腰の中心点、人体全体に外接する円の半径、肩と腰の中点を結ぶ線の傾斜角度を予測します。これにより、一部のヨガポーズのような非常に複雑なポーズでも一貫した追跡が可能になります。以下の図は、このアプローチを示しています。
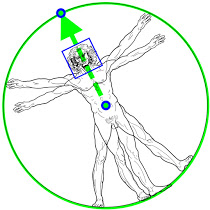
顔の境界ボックスに加えて、BlazePose検出器によって予測された2つの仮想キーポイントを介して位置合わせされたウィトルウィウス的人体図
3.MediaPipe BlazePose:リアルタイムにオンデバイスでポーズを追跡(1/2)関連リンク
1)ai.googleblog.com
On-device, Real-time Body Pose Tracking with MediaPipe BlazePose
2)arxiv.org
BlazePose: On-device Real-time Body Pose tracking
3)google.github.io
MediaPipe BlazePose
MediaPipe Face Detection
MediaPipe Hands
4)openaccess.thecvf.com
Exploiting Offset-guided Network for Pose Estimation and Tracking(PDF)
5)viz.mediapipe.dev
demo/pose_tracking

