
1.Jukebox:歌声を含む生のオーディオを生成可能なニューラルネット(2/2)まとめ
・Jukeboxは局所的には一貫性のある音楽を作成できるが曲全体で見るとまだ構造把握が甘い
・ダウンサンプリングとアップサンプリングを行っているためノイズが発生してしまう
・ミュージシャンにヒアリングしたがJukeboxはまだすぐに使えるツールと見なされなかった
2.Jukeboxの制限と今後の方向性
以下、openai.comより「Jukebox」の意訳です。元記事の投稿は2020年4月30日、Prafulla Dhariwalさん, Heewoo Junさん, Christine McLeavey Payneさん, Jong Wook Kimさん, Alec Radfordさん, Ilya Sutskeverさん, Ashley Pilipiszynさん, Justin Jay Wangさん, Brooke Chanさん, Ben Barryさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Tom Grove on Unsplash
アーティストとジャンルの調整
トップレベルのtransformer は、圧縮されたオーディオトークンを予測するタスクについてのトレーニングを受けています。これにより、各曲のアーティストやジャンルなどの追加情報を提供でき、2つの利点があります。1つは、オーディオ予測のエントロピーが減少するため、モデルは特定のスタイルでより良い品質を実現できることです。次に、生成時に、モデルを操作して、選択したスタイルで生成することができます。
以下のt-SNEによるグラフは、モデルが教師なしで、類似のアーティストやジャンルを分類分けする方法を学習し、ジェニファー・ロペスがドリー・パートンに非常に近いなどの驚くべき関連性を発見した事を示しています。

歌詞の条件付け
アーティストとジャンルの条件付けに加えて、歌詞のモデルを条件付けすることで、トレーニング時に楽曲のイメージを固める事ができます。
重要な課題は、適切に調整されたデータセットがないことです。
歌詞データは曲単位でしか存在せず、パート単位での整合性がないため、特定のパートについて、歌詞のどの部分が該当するのかは正確にはわかりません。
また、歌詞データと一致しないカバー曲が存在する場合もあります。特定の曲が複数の異なるアーティストによってわずかに異なる方法で演奏された場合などにこれが発生する可能性があります。更に、歌手は頻繁にフレーズを繰り返したり、歌詞を変えたりしますが、書かれた歌詞に常にそれらが含まれているとは限りません。
オーディオ部分と歌詞を一致させるために、単純な経験則的な手法から始めました。この手法では、歌詞の個々の文字を各曲の全長に直線的にまたがるように配置し、トレーニング中に現在のセグメントを中心とした固定サイズの文字ウィンドウを渡します。
線形配置のこの単純な戦略は驚くほどうまく機能しましたが、ヒップホップなどの速い歌詞の特定のジャンルでは失敗することがわかりました。これに対処するために、Spleeterを使用して各曲から歌声を抽出し、抽出された歌声に対してNUS AutoLyricsAlignを実行して、歌詞の正確な単語レベルの配置を取得しました。実際の歌詞がウィンドウ内にある可能性が高くなるように、十分な大きさのウィンドウを選択しました。
歌詞にattentionを向けるために、エンコーダーを追加して歌詞の特徴表現を作成します。その後、音楽デコーダーからのクエリを使用して歌詞エンコーダーからキーと値に対応するattentionレイヤーを追加しました。トレーニング後、モデルはより正確な整列を学習するようになりました。
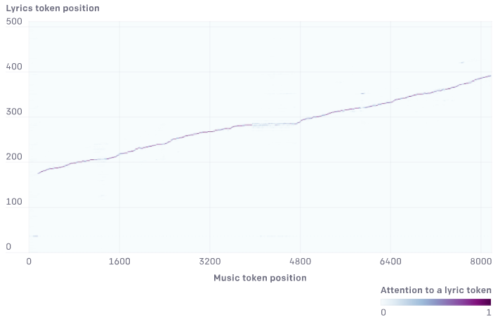
encoder–decoder attentionレイヤーによって学習された歌詞-音楽の整列
音楽が進むにつれて、ある歌詞トークンから次の歌詞トークンへとattentionが進みますが、少し不確実です。
制限事項
Jukebox は、音楽の品質、一貫性、オーディオサンプルの長さ、アーティスト、ジャンル、歌詞を条件付ける能力が一歩前進した事を表していますが、この新しい世代のAIでも人間が作成した音楽との間にまだ大きなギャップがあります。
例えば、生成された曲は局所的には一貫性のある音楽になり、伝統的なコードパターンに従い印象的なソロパートを生み出す事もできますが、曲全体で見るとコーラスの繰り返しなどの馴染みのある音楽構造にはなりません。
また、ダウンサンプリングとアップサンプリングを行っているため、聞き取り可能なノイズが発生してしまいます。コードがより多くの音楽情報を捕捉するようにVQ-VAEを改善すると、これを減らすのに役立ちます。
更にサンプリングの自己回帰性質のため、モデルのサンプリング速度は遅くなります。モデルを介して1分間のオーディオを完全にレンダリングするには約9時間かかるため、対話的なアプリケーションではまだ使用できません。モデルを並列サンプラーに抽出する手法を使用すると、サンプリング速度を大幅に高速化する事ができます。
最後に、現在は英語の歌詞と主に西洋の音楽でトレーニングを行っていますが、将来的には他の言語や西洋以外からの楽曲も一部含める予定です。
今後の方向性
OpenAIのオーディオチームは、様々な種類のpriming informationを条件としたオーディオサンプルの生成に引き続き取り組んでいます。特に、MIDIファイル(訳注:様々なメーカーの電子楽器や音楽ソフトが対応しているファイル形式)とstemファイル(訳注:1ファイルに最大4つの音源を含める事が出来るファイル形式)の条件付けが早期に成功するのを見てきました。
MIDIトークンを条件付けに使って作成した生オーディオサンプルの事例も「Generated from MIDI Conditioning」にあります。これを使う事により、サンプルの音楽性が向上し(歌詞を使った条件付けによって歌唱力が向上するように)、ミュージシャンが楽曲生成をより細かく制御できるようになることを願っています。人間とモデルのコラボレーションは、ますますエキサイティングなクリエイティブスペースになると期待しています。もし、あなたが私たちと一緒にこれらの問題に取り組むことに興奮しているなら、私たちは採用活動を行っています。
様々な領域にわたる生成モデリング手法が進歩し続けるにつれて、バイアスや知的財産権などに関する問題の研究も行っており、ツール開発に関わる領域で働いている人々とも関わりを持っています。音楽コミュニティへの将来の影響をよりよく理解するために、Jukeboxをさまざまなジャンルの10人のミュージシャンと共有して、この研究に関するフィードバックについて話し合いました。
Jukeboxは興味深い研究結果ですが、現在の制限のいくつかを考えると、今回ヒアリングを行ったミュージシャンはそれが彼らの創造的なプロセスにすぐに適用できるとは思いませんでした。テキスト、画像、音声の生成作業は今後も改善されると考えているため、私たちはより幅広いクリエイティブコミュニティとつながりを持っています。これらの領域で便利なツールや新しい芸術作品を作成するためのクリエイティブな共同作業に興味がある場合は、お知らせください。
3.Jukebox:歌声を含む生のオーディオを生成可能なニューラルネット(2/2)関連リンク
1)openai.com
Jukebox
2)jukebox.openai.com
Jukebox Sample Explorer
3)arxiv.org
Jukebox: A Generative Model for Music
4)github.com
openai / jukebox

