
1.MediaPipe Holistic:オンデバイスで顔、手、ポーズを同時に予測(1/2)まとめ
・MediaPipeはスマホで人間のポーズ、顔、手をリアルタイムで認識するフレームワーク
・従来のMediaPipeシリーズは各モデルで個々の部位を認識しており統合されてはいなかった
・MediaPipe Holisticはポーズに33、手に21、顔に468地点の統合された位置情報を提供
2.MediaPipe Holisticとは?
以下、ai.googleblog.comより「MediaPipe Holistic — Simultaneous Face, Hand and Pose Prediction, on Device」の意訳です。元記事の投稿は2020年12月10日、Ivan GrishchenkoさんとValentin Bazarevskyさんによる投稿です。
本投稿の後半に紹介されているリモートコントロールのデモはジェスチャーのみであらゆる機器を操作できるSF映画に出て来るような未来がもうすぐそこに来ている事を予感させます。
Holisticは「全体的」や「心身一体的」の意味なので、そこから連想したアイキャッチ画像のクレジットはPhoto by Simon Rae on Unsplash
その他のMediaPipeシリーズのまとめ記事はこちら。
スマートフォンなどのモバイルデバイスで人間のポーズ、顔のパーツ、手の動きをリアルタイムで同時に認識し、追跡することで、フィットネスやスポーツの分析、ジェスチャーコントロールや手話認識、拡張現実など、様々なインパクトのあるアプリケーションを実現できます。
MediaPipeは、ハードウェア(GPUやCPUなど)で加速された推論を活用する複雑な知覚パイプライン用に特別に設計されたオープンソースなフレームワークであり、これらのタスクに対して高速でありながら正確な個別のソリューションを既に提供しています。
それら全てをリアルタイムで組み合わせて意味的に一貫し、直接実行できるソリューションにまとめあげる事は、複数のニューラルネットワークに依存する推論を同時に実行する必要がある独自の難しい課題です。
本日、MediaPipe Holisticを発表します。これは、上記課題に対するソリューションであり、新しい使い方を可能にする最先端の人間のポーズ推定機能を提供します。
MediaPipe Holisticは、ポーズ、顔、手に最適化されたコンポーネントを備えた新しいパイプラインで構成され、それぞれがリアルタイムで実行され、推論バックエンド間のメモリ転送は最小限に抑えられます。品質と速度のトレードオフに応じて、3つのコンポーネントは品質優先や速度優先な版に置換可能となっています。
MediaPipe Holisticは、3つのコンポーネントすべてを含めると、画期的な540以上のキーポイント(ポーズに33、手に21、顔に468)に統合された位置情報を提供し、モバイルデバイスでもほぼリアルタイムのパフォーマンスを実現します。
MediaPipe HolisticはMediaPipeの一部としてリリースされており、モバイル(Android、iOS)及びデスクトップのデバイスで利用できます。また、MediaPipeの新しいすぐに使用できる研究用API(Python)とWeb(JavaScript)を導入しており、本テクノロジーへのアクセスは容易にできます。

上:スポーツとダンスにおけるMediaPipe Holisticの位置推定結果
下:「沈黙」と「こんにちは」のジェスチャー認識
私達のソリューションは、常に右手(青色)または左手(オレンジ色)を色分けして識別している事に注目してください。
パイプラインと品質
MediaPipe Holisticパイプラインは、ポーズ、顔、手を扱う個別のモデルを統合します。各モデルはそれぞれが特定の身体領域に最適化されています。しかし、それぞれ専門とする領域が異なるため、1つのコンポーネントへの入力は他のコンポーネントには適していません。
例えば、ポーズ推定モデルは、入力としてより低い固定解像度のビデオフレーム(256×256)を取ります。しかし、その画像から手と顔の領域を切り取ってそれぞれのモデルに渡すと、画像の解像度が低くすぎて正確に認識できなくなります。そのため、MediaPipe Holisticを多段パイプラインとして設計しました。このパイプラインは、領域に適した画像解像度を使用してさまざまな領域を処理します。
まず、MediaPipe Holisticは、BlazePoseのポーズ検出器とそれに続くキーポイントモデルを使用して人間の姿勢を推定します。次に、推測された姿勢のキーポイントを使用して、各手(両手分)と顔の3つの関心領域(ROI:Regions Of Interest)の切り抜き部分を導き出し、再切り抜きモデルを使用してROIを改善します。(詳細は以下を参照)。
次に、パイプラインはフル解像度の入力フレームからこれらのROIにトリミングし、タスク固有の顔検出用モデルと手検出用モデルを適用して、対応するキーポイントを推定します。最後に、すべてのキーポイントがポーズモデルのキーポイントと併合ジされ、540以上のキーポイントがすべて生成されます。
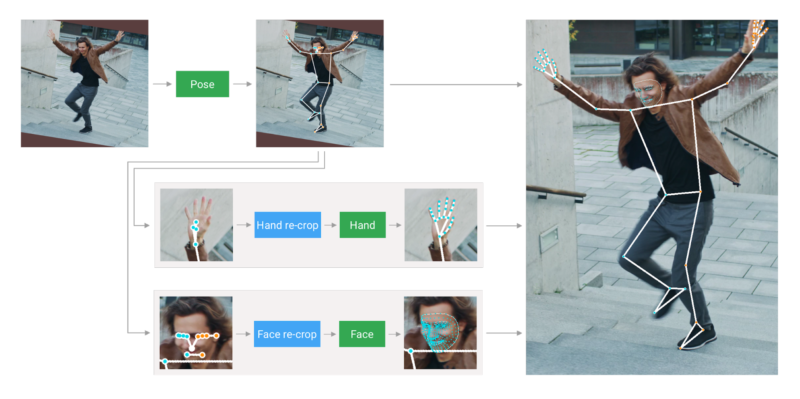
MediaPipe Holisticパイプラインの概要
ROIの識別をスリム化するために、スタンドアロンの顔と手のパイプラインに使用されているものと同じ追跡アプローチが利用しています。このアプローチは、前のフレームで行った関心領域の推定を現在のフレームの関心領域へのガイドとして使用します。そのため、物体がフレーム間で大幅に移動しないことを前提としています。
MediaPipe Holisticは速い動きに反応するとき、パイプラインの応答時間を短縮する前に、追加のROIとして(全てのフレームで)ポーズ予測を使用します。これにより、フレーム内に存在する人の左手と右手または体のパーツを他の人のパーツと混同する事を防げるようになり、モデルが体全体と各パーツで意味的な一貫性を維持することができます。
更に、ポーズモデルへの入力フレームの解像度が低いため、顔と手のROIが不正確になり、これらの領域を再トリミングする際にガイドできません。軽量性を維持するには、正確な入力のトリミングが必要です。この精度のギャップを埋めるために、軽量のフェースモデルとハンドリクロップモデルを使用します。これはpatial transformersの役割を果たし、モデルが必要とする推論時間の約10%しか使用しません。
| MEH | FLE | |
| Tracking pipeline (baseline) | 9.8% | 3.1% |
| Pipeline without re-crops | 11.8% | 3.5% |
| Pipeline with re-crops | 9.7% | 3.1% |
予測品質:一つの手を予測する際の平均誤差(MEH:Mean Error Per Hand)は、手の大きさで正規化されます。顔の目印のエラー(FLE:Face Landmarks Error)は、瞳孔間の距離によって正規化されます。
3.MediaPipe Holistic:オンデバイスで顔、手、ポーズを同時に予測(1/2)関連リンク
1)ai.googleblog.com
MediaPipe Holistic — Simultaneous Face, Hand and Pose Prediction, on Device
2)google.github.io
MediaPipe Holistic
MediaPipe on Google Colab
MediaPipe on CodePen
3)mediapipe.dev
holistic_remote

