
1.人間による評価を使って要約を学ぶ(1/4)まとめ
・人間による評価を強化学習に取り込んで優れた要約文を書き上げる言語モデルを開発
・人間による評価モデルは巨大な教師ありモデルや人間が作成した要約よりも優れていた
・本研究は長期的にはAIを人間の真似ではなく好みに合わせる事に繋げていく事が目標
2.AIシステムを人間の真似ではなく好みに合わせる研究
以下、openai.comより「Learning to Summarize with Human Feedback」の意訳です。元記事の投稿は2020年9月4日、Jeffrey Wuさん、Ryan Loweさん、Long Ouyangさん、Nisan Stiennonさん、Paul Christianoさん、Daniel Zieglerさん、Chelsea Vossさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Aaron Burden on Unsplash
人間による評価を強化学習に取り込んで、優れた要約文を書き上げる言語モデルを開発しました。私達のモデルは、教師あり学習のみを使ってトレーニングされた10倍大きい規模を持つモデルが書き上げた要約文よりも優れた要約文を生成します。
Reddit TL;DRデータセットでモデルをトレーニングした後、微調整することなくCNN/DailyMailのニュース記事から適切な要約を生成するように同モデルを転移できました。
私達の手法は要約タスクに固有のものではありません。長期的には、私達の目標はAIシステムを人間の好みに合わせる事であり、これを多くの領域でAI研究と製品展開の中心的な構成要素とする事です。
人間からフィードバックを受けたモデルは、「TL;DRを使ったはるかに大きな教師ありモデルが作成した要約」及び「人間が作成した要約」よりも優れた要約を書き上げます。
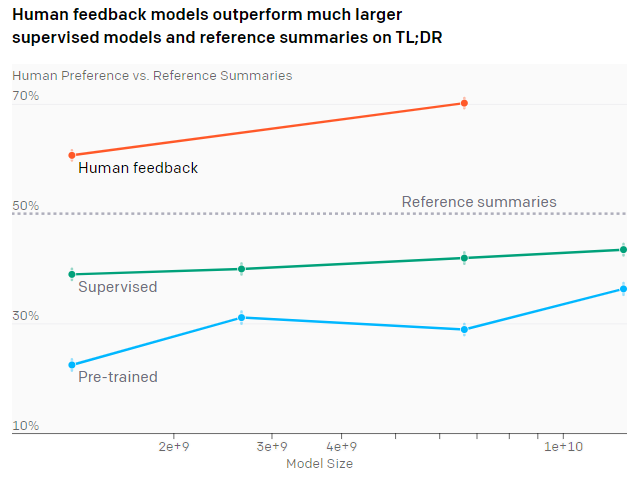
図1.様々なモデルサイズで様々なトレーニング手法のパフォーマンスを比較
モデルのパフォーマンスは、そのモデルの作成した要約文が人間が作成した参照要約(Reference summaries)よりも好まれた頻度によって測定されます。事前トレーニング済みモデル(Pre-trained)はGPT-3の初期バージョンです。教師ありモデル(Supervised)は117,000の人間が作成したTL;DRを予測するように微調整されています。また、人間のフィードバックモデル(human feedback)は、約65,000の要約比較データセットで更に微調整されています。
大規模な言語モデルは、NLPタスクでますます有能になっています。
これらのモデルは通常、人間が書いた文章内に出現する次の単語を予測する事を目的とさせてトレーニングされます。しかし、この目的は私たちが望むものを正確に捉えているわけではありません。
通常、私達はモデルに人間を模倣して欲しくはありません。より高品質な回答を提供してもらいたいのです。
このニーズの不一致は、モデルが人間が書いた低品質なテキストを模倣するようにトレーニングされている場合は明らかですが、より微妙な形で現れる可能性もあります。
例えば、人間の発言を予測するように訓練されたモデルは、確信がない場合であっても「事実」として書き上げてしまう可能性があります。または、有害な社会的偏見を反映した文章を生成してしまうかもしれません。どちらの失敗も、文章としては良く書けた文章になります。
人工知能の安全性に関する取り組みの一環として、モデルの目的を私達が本当に気にかけている最終的な行動に合わせる技術を開発したいと考えています。
私達のモデルがより強力になるにつれて、モデルを私達の目標に合わせる事が、人工知能が人類にとって有益であることを確実にするために非常に重要になると信じています。
短期的には、人間によるフィードバックを与える手法が、人類にとって有用なタスクでモデルのパフォーマンスを向上する事に役立つかどうかをテストしたいと考えました。
私達は英文の要約に焦点を当てました。これは、何が「良い要約」を作るのかという概念を、人間の介入なしに捕捉するのが困難であるからです。
今回の手法では、私達は主に、ソーシャルネットワークRedditに投稿された書き込みを集めた既存のデータセットに、人間の元の投稿者が書いた短い要約である「TL;DR(訳注:Too Long, Didn’t Read:元々は長文すぎて読めませんの略なのですが、転じて「長文を読みたくな人向けの要約文」の意味で使われる事があります)」と一緒にこの方法を適用します。
まず、教師あり学習を介して報酬モデルをトレーニングし、人間が好む要約を予測します。
次に、強化学習(RL)を使用して言語モデルを微調整し、その報酬モデルに従って高得点の要約を作成します。これにより、微調整に使用されるデータセットとは非常に異なるデータセットであっても、要約品質(人間による評価)が大幅に向上することがわかりました。
私達のアプローチは、人間のフィードバックから学ぶという以前の研究を継続したものです。しかし、要約モデルをトレーニングするために人間のフィードバックを使用する他の研究もあります。
より大きなモデルにスケーリングし、より多くのフィードバックデータを収集し、研究者とラベル付与作業者の合意を綿密に監視し、ラベル付け作業者に頻繁にフィードバックを提供することで、この手法をさらに推進します。
人間のフィードバックは、対話、セマンティック解析、翻訳、ストーリーとレビュー生成、証拠抽出(evidence extraction)、従来のRLタスクなど、他のいくつかの分野でモデルをトレーニングする際にも使用されています。
結果
「21歳の女性です。GameStopでの就職の面接、質問について答える事ができる他の勤務者はいますか?」私はGameStopで就職面接を予定していますが、この面接のためにどれだけドレスアップすべきか誰かに教えてもらえないと思っています。軽装すぎるのも着飾りすぎるのも嫌です。また、私は履歴書を持っていくべきですか?応募して面接を受けましたが、就職したいです。他の小売店でアシスタントマネージャーを3年間務めた経験があります。
その後、諸手続きなどは全て完了した上で就学のために州を出ました。私は本当にこの仕事をしたいです。 アドバイスをいただければ幸いです。
GameStopでの就職の面接で、服装や持ち物についてのアドバイスを求めています。(つまり、履歴書、その他の事務手続き)
21歳の女性、GameStopでの就職の面接、質問に答えることができる他の雇用者はいますか? 私は以前に小売業の経験があり、この仕事に就きたいと思っています。 アドバイスをいただければ幸いです。
GameStopで就職の面接がありますが、質問に答えられる他の雇用者はいますか?
また、これは私が履歴書を持っていくべきものですか?
私はGameStopで就職面接の予定があります。この面接のためにどれだけドレスアップすべきか誰かに教えてもらえないかと思っています。軽装すぎるのも着飾りすぎるのも嫌です。また、この面接に私が何かを持っていくべきものはありますか?
いくつかの異なる要約モデルを評価しました。
・インターネットから取得したテキスト(幅広い分布)で事前トレーニングされたモデル
・TL;DRを予測するために教師あり学習によって微調整されたモデル
・人間のフィードバックを使用して微調整されたモデル
各モデルを評価するために、検証セット内の投稿を要約させ、完成した要約を人間が作成した参照要約と比較するように人間に依頼しました。
結果は上部の図1に示しています。
3.人間による評価を使って要約を学ぶ(1/4)まとめ
1)openai.com
Learning to Summarize with Human Feedback
2)arxiv.org
Learning to summarize from human feedback
3)github.com
openai / summarize-from-feedback
4)openaipublic.blob.core.windows.net
models trained in the “Learning to Summarize from Human Feedback” paper.

