
1.Image GPT:自然言語処理用の人工知能で画像を生成(3/3)まとめ
・iGPTが強力な画像特徴表現を学習可能で教師有り、半教師モデルと匹敵する事が示された
・しかしGPUにV100を使って延べ2500日が必要で画像専用モデルの約35倍の計算が必要
・十分な計算機資源があればsequence transformerが多くの分野で優れた成果を出す可能性有
2.iGPTの性能の検証
以下、openai.comより「Image GPT」の意訳です。元記事の投稿は2020年6月17日、Mark ChenAlecさんとRadfordIlya Sutskeverさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Soragrit Wongsa on Unsplash
次の結果は、生成画像のパフォーマンスと特徴表現品質がリンクしている事を示しています。モデルの規模を拡大することと、より多くの反復をトレーニングすることの両方が、より良い生成パフォーマンスをもたらし、それが直接、より良い特徴表現の品質につながることがわかりました。
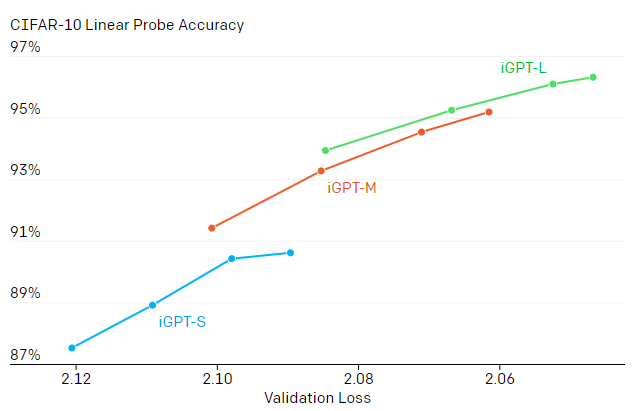
各線は、生成的事前トレーニングを行った各モデルを追跡してます。
4つの点は、ステップ13.1万、26.2万、52.4万、および100万回のチェックポイントを示します。右上向きの勾配は、生成パフォーマンスの向上と特徴表現品質の向上との関連を示唆しています。大きいモデルは、小さいモデルよりも優れた特徴表現を生成します。iGPT-XLは、別のデータセットでトレーニングされているため、本図には含まれていません。
CIFAR-10、CIFAR-100、およびSTL-10で線形探触子(linear probe)を使用して特徴を評価すると、全ての教師有りおよび教師なし転移アルゴリズムの特徴表現よりもパフォーマンスが優れています。 私たちの結果は、微調整を行う完全設定の条件下でも説得力があります。
| EVALUATION | MODEL | ACCURACY | W/O LABELS | W/ LABELS |
| CIFAR-10 | ResNet-152 | 94.0 | ○ | |
| Linear Probe | SimCLR | 95.3 | ○ | |
| iGPT-L 32×32 | 96.3 | ○ | ||
| CIFAR-100 | ResNet-152 | 78.0 | ○ | |
| Linear Probe | SimCLR | 80.2 | ○ | |
| iGPT-L 32×32 | 82.8 | ○ | ||
| STL-10 | AMDIM-L | 94.2 | ○ | |
| Linear Probe | iGPT-L 32×32 | 95.5 | ○ | |
| CIFAR-10 | AutoAugment | 98.5 | ||
| Fine-tune | SimCLR | 98.6 | ○ | |
| GPipe | 99.0 | ○ | ||
| iGPT-L | 99.0 | ○ | ||
| CIFAR-100 | iGPT-L | 88.5 | ○ | |
| Fine-tune | SimCLR | 89.0 | ○ | |
| AutoAugment | 89.3 | |||
| EfficientNet | 91.7 | ○ |
ImageNet転送を利用する教師なしまたは教師ありのトップパフォーマンスモデルと私達のモデルを線形プローブと微調整後精度で比較
CIFARでエンドツーエンドでトレーニングされた最高のパフォーマンスを発揮するモデルであるAutoAugmentも比較対象に含めました。
| METHOD | INPUT RESOLUTION | FEATURES | PARAMETERS | ACCURACY |
| Rotation | original | 8192 | 86M | 55.4 |
| iGPT-L | 32×32 | 1536 | 1362M | 60.3 |
| BigBiGAN | original | 16384 | 86M | 61.3 |
| iGPT-L | 48×48 | 1536 | 1362M | 65.2 |
| AMDIM | original | 8192 | 626M | 68.1 |
| MoCo | original | 8192 | 375M | 68.6 |
| iGPT-XL | 64×64 | 3072 | 6801M | 68.7 |
| SimCLR | original | 2048 | 24M | 69.3 |
| CPC v2 | original | 4096 | 303M | 71.5 |
| iGPT-XL | 64×64 | 3072 x 5 | 6801M | 72 |
| SimCLR | original | 8192 | 375M | 76.5 |
私達のモデルと最先端の自己教師モデルの間の線形プローブ精度の比較
私達の手法はより多くのパラメーターと計算を必要とし、入力画像の解像度もはるかに低いのですが、競争力のあるパフォーマンスを達成しました。
BERTのようなマスク言語モデルは、ほとんどの言語タスクで生成モデルを上回っているため、BERTの画像に対するパフォーマンスも評価しました。先行するすべての画素を指定して次の画素を予測するようにモデルをトレーニングする代わりに、画素の15%をマスクし、マスクされていない残りの画素を使って予測するようにモデルをトレーニングしました。BERTモデルの線形プローブのパフォーマンスは大幅に低下しますが、微調整時にこれを取り戻す事がわかりました。
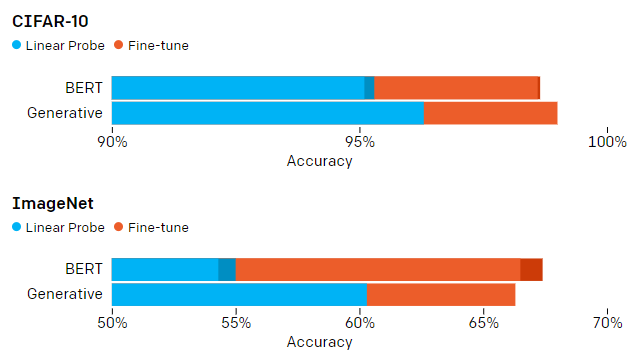
322 × 3の入力解像度でiGPT-Lを使用した生成的事前トレーニングとBERTを使用した事前トレーニングの比較。濃い色の部分は、BERTマスクをアンサンブルすることによるパフォーマンスの向上を示しています。生成モデルは、事前トレーニング後にBERTモデルよりもはるかに優れた特徴表現を生成することがわかりますが、BERTモデルは微調整後に追いつきます。
教師なし学習は、人間がラベル付けしたデータを必要とせずに優れた機能を約束しますが、限られた量の人間がラベル付けしたデータを使用する事が出来る半教師あり学習のより寛容なフレームワークの下で、最近大きな進歩が見られました。
成功する半教師有り学習法は、一貫性の正則化(consistency regularization)、データの水増し(data augmentation)、疑似ラベル付け(pseudo-labeling)などの巧妙な手法に依存することが多く、純粋な生成ベースのアプローチは何年も競争力がありませんでした。
しかし、このサブフィールドの競合ベンチマークでiGPT-Lを評価すると、水増しを行っていない画像から学習した特徴表現に対する単純な線形プローブは、FixMatchを下回っていますが、Mean TeacherおよびMixMatchを上回っています。
| MODEL | 40 LABELS | 250 LABELS | 4000 LABELS |
| Improved GAN | — | — | 81.4 ± 2.3 |
| Mean Teacher | — | 67.7 ± 2.3 | 90.8 ± 0.2 |
| MixMatch | 52.5 ± 11.5 | 89.0 ± 0.9 | 93.6 ± 0.1 |
| iGPT-L | 73.2 ± 1.5 | 87.6 ± 0.6 | 94.3 ± 0.1 |
| UDA | 71.0 ± 5.9 | 91.2 ± 1.1 | 95.1 ± 0.2 |
| FixMatch RA | 86.2 ± 3.4 | 94.9 ± 0.7 | 95.7 ± 0.1 |
| FixMatch CTA | 88.6 ± 3.4 | 94.9 ± 0.3 | 95.7 ± 0.2 |
データが比較的少ないCIFAR-10でのパフォーマンスの比較
ラベルがない多くのImageNet画像を活用することで、iGPT-Lは、Mean TeacherやMixMatchなどの手法を上回りますが、それでも最先端の手法は下回ります。私達の半教師あり学習手法は非常に単純です。データの水増しや微調整を行わずに、ロジスティック回帰をiGPT-Lの特徴表現に適用するだけです。これは、特別に設計された半教師あり手法とは大きく異なります。
制限事項
iGPTが強力な画像特徴表現を学習できる事を示しましたが、私達のアプローチには依然として重大な制限があります。自然言語でGPT-2に使用された汎用sequence transformerを使用するため、今回の手法では大量の計算が必要でした。iGPT-LはGPUにV100を使って延べ2500日間(2500 V100-days)トレーニングされましたが、同様なパフォーマンスを出せるMoCo24モデルは70 V100-daysのトレーニングで済みます。
関連して、今回のtransformerを使用した手法では低解像度画像を入力としましたが、ほとんどの自己教師型モデルは、高解像度画像を入力として簡単に取り扱う事ができる畳み込みベースのエンコーダーを使用します。
transformerモデルを更に拡張するためには、分野に依存しないマルチスケールtransformerなどの新しいアーキテクチャが必要になる可能性があります。
これらの制限を考えると、私達の今回の研究は主に、特定領域に固有の知識を必要とせずに、新しい領域で優れた教師なし表現を学習できる大規模なtransformerベースの言語モデルの能力の概念実証として成功したと言えます。
しかしながら、これらのモデルをトレーニングするための膨大な計算コストと、最近の畳み込みニューラルネットワークベースの手法の精度の向上により、これらの特徴表現を現実の視覚関連のアプリケーションに採用するのは不可能でしょう。
最後に、生成モデルは、トレーニングに使ったデータが内包する偏り(bias)を示す可能性があります。これらの偏りの多くは便利に利用する事はできます。例えば、茶色と緑色の画素の組み合わせが葉で覆われた枝を表現する事を想定し、偏り傾向を使用して画像を補完する事などが出来ます。
しかし、公平性と象徴性のレンズを通して考えると、これらの偏りのいくつかは有害です。例えば、モデルが科学者の視覚的概念を男性に偏って覚えてしまった場合、科学者の画像を補完する際には、常に性別を偏らせて、男性のみを補完して完成させる可能性があります。
人工知能の開発者は、システムに与えるデータにますます注意を払い、それがトレーニング済みモデルの偏りとどのように関連しているかをよりよく理解する必要があると予想されます。
結論
2次元データに関する見識と計算量をトレードオフし、ネットワークの中央部から予測した特徴表現を選択することにより、sequence transformerは最上位の教師なし画像分類畳み込みネットワークと競合できる事を示しました。
特筆すべき事は、GPT-2言語モデルを画像生成に直接適用することでこの結果を達成した事です。
私達の結果は、その単純さと一般性のために、十分な計算機資源が与えられたsequence transformerが最終的に多くの分野で優れた特徴表現を学習する効果的な手法となる可能性を示唆しています。
この分野の研究に興奮し、私達と一緒に研究したいと思ってくれたのなら、私達は採用活動をしていますよ!
3.Image GPT:自然言語処理用の人工知能で画像を生成(3/3)関連リンク
1)openai.com
Image GPT
Generative Pretraining from Pixels V2(PDF)
2)github.com
openai / image-gpt
