
1.DALL-E 2がセンシティブな画像を生成しないようにするための工夫(2/3)まとめ
・生成モデルは学習データに似たデータを生成しようとするが元データが偏っている場合がある
・学習データを選別すると元データ内の偏りが増幅してしまったり新規に発生する可能性がある
・フィルタリング前後でデータセット内の分布が変らないように再重み付けを工夫して対処した
2.DALL-E 2の学習データのバイアス
以下、openai.comより「DALL·E 2 Pre-Training Mitigations」の意訳です。元記事は2022年6月28日、Alex Nicholさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Dan Meyers on Unsplash
データフィルタが増幅する偏見の修正
生成モデルは、学習データの分布と一致するようなデータを新規に生成しようとします。しかし、学習データ内に偏りが含まれていることもあります。
そのため、学習データにフィルタをかけると、下流のモデルに新たに偏りが生じたり、偏りが増幅されたりする可能性があります。
一般に、元のデータセット自体が持つ偏りを修正することは、社会技術的に難しい課題であり、私たちも研究を続けていますが、本投稿の範囲外です。
ここで扱う問題は、特にデータフィルタリング自体によって引き起こされるバイアスの増幅です。私達のアプローチでは、フィルタリングされたモデルがフィルタリングされていないモデルよりも偏ることを防ぎ、本質的にデータフィルタリングによって引き起こされる分布シフトを減らすことを目的としています。
フィルタリングによるバイアスの増幅の具体例として「最高経営責任者(a ceo)」というプロンプトを考えてみましょう。
このプロンプトに対して、フィルタリングされていないモデルが画像を生成した場合、女性よりも男性の画像を多く生成する傾向があり、このバイアスのほとんどは現在の学習データ自体が持つ偏りの反映であると思われます。しかし、同じプロンプトをフィルタリングモデルで処理したところ、偏見が増幅されたように見え、生成された画像はほぼ男性のみとなりました。
このような偏見の増幅は、2つの要因から生じていると考えられます。
1つ目は、元のデータセットに女性と男性がほぼ同じ割合で含まれていたとしても、データセットが女性をより性的な文脈で表現するように偏っている可能性です。
2つ目は、データ収集と検証の段階でそのようなことがないように努力したにもかかわらず、実装またはクラス定義が原因で分類器自体が偏っている可能性です。
この2つの影響により、私たちのフィルターは男性よりも女性の画像を多く除去し、モデルが学習中に観察する男女比を変化させる可能性があります。
フィルターによる偏見をより詳細に調査するため、データフィルターが様々な概念への偏見にどの程度影響しているかを測定する方法を探しました。特に、暴力的及び性的コンテンツフィルターは純粋に画像ベースですが、学習元データセットが画像と文章を含むマルチモーダルであるため、これらのフィルターが文章に及ぼす影響を直接測定することができます。
すべての画像には文章による説明文が付いているため、フィルタリングされたデータセットとフィルタリングされていないデータセットで、手動で選択したキーワードの相対頻度を調べ、フィルタリングが任意の概念にどの程度影響を与えたかを推定することができます。
これを実践するために、Apache Sparkを使用して、フィルタリングされたデータセットとフィルタリングされていないデータセットの両方のすべての説明文について、少数のキーワード(例えば、「両親(parent)」、「女性(woman)」、「子供(kid)」)の頻度を計算しました。このデータセットには何億もの文章と画像のペアが含まれていますが、これらのキーワードの頻度の計算は、私達の計算クラスタを使用してわずか数分しかかかりませんでした。
キーワードの頻度を計算した結果、データセットフィルターが特定のキーワードの頻度を他のキーワードよりも歪めていることを確認することができました。例えば、「女性(woman)」の頻度が14%減少したのに対し、「男性(man)」の頻度は6%しか減少していません。これは、両データセットで学習させたGLIDEモデルからサンプリングすることで、すでに経験的に観測されていたことを、大規模に確認したことになります。
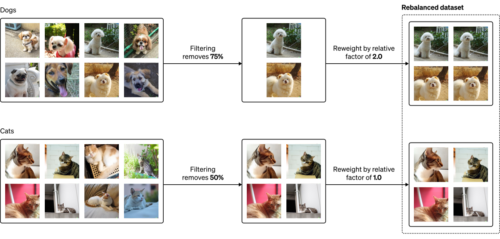
データセットの再重み付けの説明図
バランスのとれたデータセットから始めます(左)。あるカテゴリーに他のカテゴリーよりもフィルターが影響を与えると、偏ったデータセットになることがあります(中央)。再重み付け(reweighting)を使うことで、あるデータを他のデータよりも効果的に「繰り返し」、フィルターによる偏りを再調整することができます(右)。
フィルターによるバイアスを測定するための代替手法ができたので、それを軽減する方法が必要になりました。この問題に取り組むため、フィルタリングされたデータセットの分布がフィルタリングされていない画像の分布とよりよく一致するように、再重み付けすることを目的としました。
例えば、猫が50%、犬が50%で構成される画像データセットに対して、75%の犬を除去し、50%の猫だけを除去するとします。最終的なデータセットは2/3が猫と1/3が犬となり、このデータセットで学習した尤度ベースの生成モデルは、犬よりも猫の画像を多く生成すると思われます。
このアンバランスを解消するには、すべての犬の画像に対して学習損失を2倍する必要があります。これは、すべての犬の画像を2回繰り返す効果をエミュレートしています。
このアプローチは、実際のデータセットやモデルに対して、ほぼ自動で拡張できることがわかりました。つまり、重み付けする特徴を手動で選択する必要はないのです。
Choiら(2019)が用いたアプローチと同様に、特別な分類器から得た確率を用いて、フィルタリングされたデータセット内の画像に対する重みを計算します。この分類器を訓練するために、両方のデータセットから画像を一様にサンプリングし、画像がどちらのデータセットから来たかを予測します。
具体的には、このモデルは、事前確率(unfiltered)=0.5を与えて、P(unfiltered|image)を予測します。しかし、実際には、このモデルはあまり強力であって欲しくありません。さもなければ、モデルはフィルターに実装されている関数を正確に学習してしまうかもしれません。
その代わりに、私達はモデルが私達のオリジナルデータフィルターよりも滑らかで、フィルターによって影響を受ける大まかなカテゴリーを捕らえつつ、特定の画像がフィルターにかけられるかどうかわからないようにしたいです。この目的のために、私達は小さなCLIPモデルの上に線形プローブを学習させました。
ある画像がフィルタリングされていないデータセットからのものである確率を予測する分類器を手に入れたら、この予測を画像の重みに変換する必要があります。例えば、P(unfiltered|image) = 0.8とします。これは、サンプルはフィルタリングされたデータよりもフィルタリングされていないデータで見つかる可能性が4倍高いことを意味し、4の重みについてアンバランスを修正する必要があります。より汎用的には、重み P(unfiltered|image)/P(filtered|image) を用いることができます。
この再重み付けスキームは、増幅された偏見を実際にどの程度緩和することができるのでしょうか?
フィルタリングされたモデルを新しい重み付けスキームで微調整したところ、微調整されたモデルの挙動は、以前発見した偏ったサンプルでフィルタリングされていないモデルにかなり近くなりました。この結果を受けて、私たちは、キーワードベースの偏見に関する経験則を用いて、この緩和策をより詳細に評価したいと考えました。
新しい重み付け方式を考慮しながらキーワードの頻度を測定するには、フィルタリングデータセット内のキーワードの各実体に、それを含むサンプルの重み付けをするだけです。こうすることで、フィルタリングデータセットのサンプルの重みを反映した新しいキーワード頻度のセットを得ることができます。
ほとんどのキーワードで、フィルタリングによる頻度変化が軽減されていることが確認できました。例えば、「男性」「女性」については、フィルタリング前の値がそれぞれ14%、6%であったのに対し、相対的な減少率が1%、-1%になりました。この指標はあくまでフィルタリングの偏りの代替指標ですが、画像による再重み付けを行うことで、テキストによる指標を大幅に改善できたことは心強いことです。
DALL-E 2では、モデルの挙動をより詳細に評価し、フィルタリングが偏見と能力の開発にどのように影響するかを調査することで、残りの偏見を引き続き調査しています。
3.DALL-E 2がセンシティブな画像を生成しないようにするための工夫(2/3)関連リンク
1)openai.com
DALL·E 2 Pre-Training Mitigations
