
1.Menger:大規模な分散型強化学習(2/3)まとめ
・キャッシュにより行為者から受け取る多数のリクエストと学習者の作業のバランスを取った
・キャッシュは更新要求処理する学習者の負荷だけでなく行為者の平均読み取り遅延も軽減
・高スループット入力実現のために強化学習用に設計されたストレージシステムReverbを使用
2.大規模な分散型強化学習の課題
以下、ai.googleblog.comより「Massively Large-Scale Distributed Reinforcement Learning with Menger」の意訳です。元記事の投稿は2020年10月2日、Amir YazdanbakhshさんとJunchaeo Chenさんによる投稿です。
アイキャッチ画像のクレジットはwikipediaよりNiabot
効率的なモデル検索
最初の課題に対処するために、学習者(learner)と行為者(actor)の間に透過的で分散型のキャッシュコンポーネントを導入します。これはDota2用モデルと同じ手法で、TensorFlowで最適化され、Reverbに支えられています。
キャッシングコンポーネントの主な責任は、行為者から受け取る多数のリクエストと学習者の作業のバランスを取ることです。
これらのキャッシングコンポーネントを追加すると、学習者にかかる読み取り要求処理の圧力を大幅に軽減できるだけでなく、複数のBorgセルに行為者が更に分散する事が出来ます。Borgセル間の通信のオーバーヘッドがわずかです。
私たちの調査では、512の行為者を備えた16 MBモデルの場合、導入されたキャッシュコンポーネントにより、平均読み取りレイテンシが約4.0倍短縮され、特にPPOなどのオンポリシーアルゴリズムのトレーニングの反復が高速化されることが示されています。
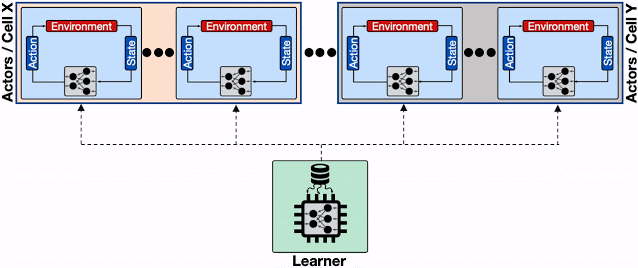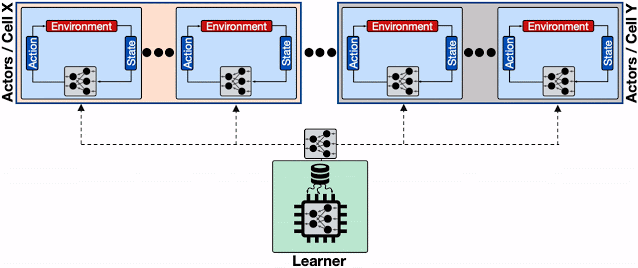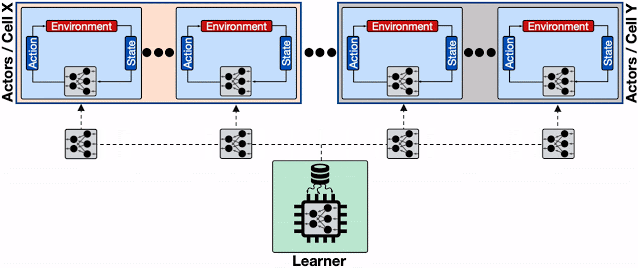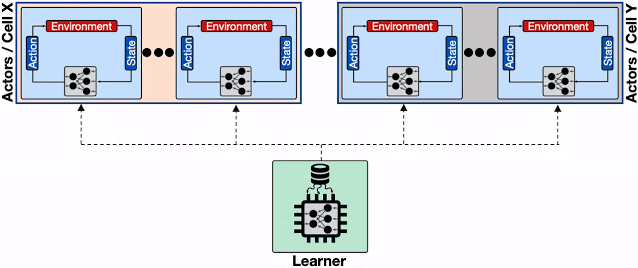
複数の行為者が異なるBorgセルに配置された分散RLシステムの概要
さまざまなBorgセルにまたがる膨大な数の行為者から来る頻繁なモデル更新要求に対応するように学習者が締め上げられ、学習者と行為者間の通信ネットワークが抑制され、全体的な収束時間が大幅に増加します。破線は、異なるマシン間のgRPC通信を表しています。
導入された透過的分散キャッシングサービスを使用して、複数の行為者が異なるBorgセルに配置された分散RLシステムの概要
学習者は、更新されたモデルを分散キャッシングサービスにのみ送信します。各キャッシングサービスは、近くの行為者(つまり、同じBorgセルに配置された行為者)とキャッシングサービスからのモデルリクエストの更新を処理します。キャッシングサービスは、モデルの更新要求を処理するための学習者の負荷を軽減するだけでなく、行為者による平均読み取り遅延も軽減します。
高スループット入力パイプライン
Mengerは、高スループットの入力データパイプラインを提供するために、機械学習アプリケーション向けに設計され、最近オープンソース化されたデータストレージシステムであるReverbを使用しています。Reverbは、様々なオンポリシー/オフポリシーアルゴリズムで経験のリプレイを実装するための効率的で柔軟なプラットフォームを提供します。
ただし現状、単一のReverbを使ってリプレイバッファサービスを使用すると、数千の行為者を含む分散RL設定では適切に拡張できず、行為者からの書き込みスループットの点で非効率的になります。
単一のリプレイバッファを備えた分散RLシステム
行為者からの大量の書き込み要求を処理すると、リプレイバッファが抑制され、全体的なスループットが低下します。更に学習者を複数のコンピューティングエンジン(TPUポッドなど)の設定に規模拡大すると、単一のリプレイバッファーサービスからこれらのエンジンにデータを供給することが非効率になり、全体的な収束時間に悪影響を及ぼします。
3.Menger:大規模な分散型強化学習(2/3)関連リンク
1)ai.googleblog.com
Massively Large-Scale Distributed Reinforcement Learning with Menger
2)github.com
deepmind / reverb
