
1.DeepVariant 1.0によるゲノム解析精度の向上(1/4)まとめ
・ゲノム解読はハードウェアによる読み取りとソフトウェアによる識別で可能になった
・DeepVariantは様々なハードウェアに対応可能なCNNを使った識別用ソフトウェア
・DeepVariant v1.0は、PrecisionFDA v2 Truth コンテストの提出版を更に改良した版
2.DeepVariant v1.0とは?
以下、ai.googleblog.comより「Improving the Accuracy of Genomic Analysis with DeepVariant 1.0」の意訳です。元記事の投稿は2020年9月18日、Andrew CarrollさんとPi-Chuan Changさんによる投稿です。
DNAの2重螺旋構造を意識して選んだアイキャッチ画像のクレジットはPhoto by Nicolas Hoizey on Unsplash
ゲノム解読(genome sequencing、生物のゲノムの完全なDNA配列を調べる作業)には、約60億組の核酸塩基(すなわち、アデニン(Adenine)、チミン(Thymine)、グアニン(Guanine)、およびシトシン(Cytosine))からDNAの短い断片を抽出する事が含まれます。私達はゲノムを両親から継承しています。
ゲノム解読は、2つの主要なテクノロジーによって可能になりました
・DNA sequencers(ハードウェア)
比較的小さなDNAの断片を読み取ります。
・Variant callers(ソフトウェア)
読み取った断片を整列して個人のゲノムが参照元ゲノム(Human Genome Projectで作成されたものなど)とどこでどのように異なるか(variants)を識別します。
そのようなvariantsを特定する事は、乳がん、肺動脈高血圧症、または神経発達障害のリスク上昇などの遺伝的障害の手掛かりとなる可能性があります。
2017年に、畳み込みニューラルネットワーク(CNN)を使用してDNA配列中のvariantsを識別するオープンソースツールであるDeepVariantをリリースしました。
ゲノム解読プロセスは、最終的な目標に応じて異なりますが、いずれかの機器によって物理サンプルを読み取ることから始まります。
次に、読み取ったゲノムの各断片(部分的な重複を含む)から生データを生成し、参照元ゲノムにマッピングします。
DeepVariantはこれらのマッピングを分析して、variantsの場所を特定し、読み取りエラーと区別します。
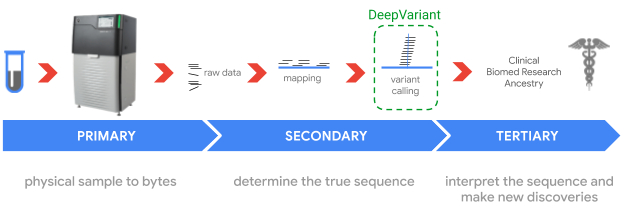
2018年に最初に公開された後、DeepVariantは、全エクソームシーケンスとポリメラーゼ連鎖反応(PCR)シーケンスの精度を向上させるための重要な変更を含む、多くの更新と改善を受けました。
現在、DeepVariant v1.0をリリースしています。これには、全ての配列データに対する多数の改善が組み込まれています。
DeepVariant v1.0は、PrecisionFDA v2 Truth コンテストに提出したバージョンを更に改良したバージョンであり、4つの器具カテゴリのうち3つで最高の総合精度を達成しました。
従来の最新モデルと比較して、DeepVariant v1.0は、IlluminaやPacific Biosciencesなど、広く使用されている配列データタイプのエラーを大幅に削減します。
更に、UCSC Genomics Instituteとのコラボレーションを通じて、DeepVariantとUCSCのPEPPERを組み合わせたモデルをリリースしました。このモデルはOxford Nanopore dataを初めてカバーします。

3.DeepVariant 1.0によるゲノム解析精度の向上(1/4)関連リンク
1)ai.googleblog.com
Improving the Accuracy of Genomic Analysis with DeepVariant 1.0
2)www.nature.com
A universal SNP and small-indel variant caller using deep neural networks
3)github.com
google / deepvariant
kishwarshafin / pepper
4)www.nist.gov
Genome in a Bottle

