
1.MentorMix:現実世界の誤ラベルがディープラーニングに及ぼす影響を調査(2/3)まとめ
・MentorMixは合成ノイズと現実世界のノイズの両方に対処できる効果的な手法
・MentorMixはMentorNetとMixupに基づいて構築された反復アプローチ
・MentorMixはノイズ入りCIFAR 10/100でもWebVisionでも最高スコアを達成
2.MentorMixとは?
以下、ai.googleblog.comより「Understanding Deep Learning on Controlled Noisy Labels」の意訳です。元記事の投稿は2020年8月19日、Lu JiangさんとWeilong Yangさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Jamie Matociños on Unsplash
MentorMix:シンプルで堅牢な学習方法
私達の目標は、ノイズがどの程度混入しているかわからないデータセットが与えられた際に、クリーンなテストデータで十分に一般化できる堅牢なモデルをトレーニングすることです。Controlled Noisy Web Labelsデータセットを使って開発した、MentorMixと呼ばれる、合成ノイズと現実世界のノイズの両方に対処できるシンプルで効果的な方法を紹介します。
MentorMixは、MentorNetとMixupの2つの既存の技術に基づいて構築された反復アプローチであり、4つのステップ(重み付け、サンプリング、混合、および再重み付け)で構成されています。
最初のステップでは、MentorNetネットワークによってミニバッチの全てのサンプルで重みが計算されます。これは、手元のタスクに合わせて調整でき、重みは分布に正規化されます。
実務的には、正しくラベル付けされたサンプルに高い重みを割り当て、正しくラベル付けされていないサンプルにゼロの重みを割り当てることが目標です。現実にはどれが正しくか、どれが正しくないかはわかりません。そのため、MentorNetの重みは近似に基づいています。ここで説明する例では、MentorNetはStudentNetのトレーニング損失を使用して、分布の重みを決定します。
次に、各サンプルについて、重点サンプリング法(Importance sampling)を使用して、分布に従って同じミニバッチ内の別のサンプルを抽出します。重みが大きいサンプルは正しいラベルが付いている傾向があるため、抽出する際に好まれます。
次に、Mixupを使用して元のサンプルと抽出されたサンプルを混合し、モデルが2つのサンプルを補間して、ノイズの多いトレーニングサンプルに過剰適合する事を回避します。最後に、混合したサンプルの別の重みを計算して、最終的な損失をスケーリングすることができます。この2番目の重み付け戦略の影響は、ノイズレベルが高いほど顕著になります。
概念的には、上記のステップは新しい堅牢な損失(robust loss)、つまり、ノイズの多いトレーニングラベルに対してより弾力性がある損失を実装している事になります。このトピックの詳細については、論文をご覧ください。以下のアニメーションは、MentorMixの4つの主要なステップを示しています。StudentNetが、ノイズの多いラベル付きデータでトレーニングされるモデルです。ここでは各例の重みを計算するために、Jiang等によって説明されているMentorNetの非常に単純なバージョンを採用しています。
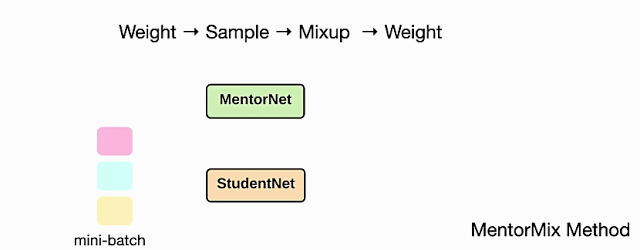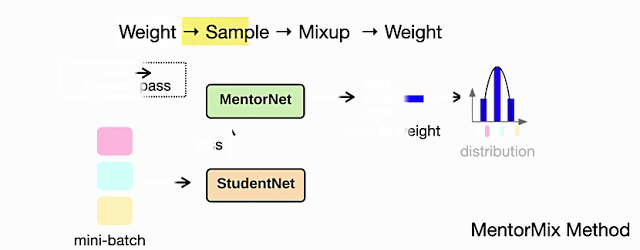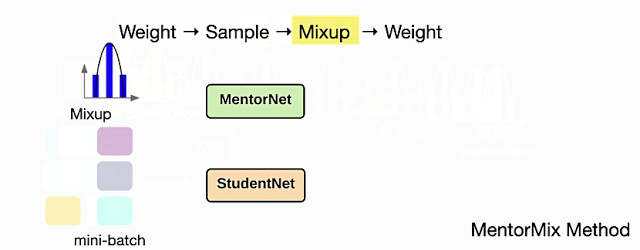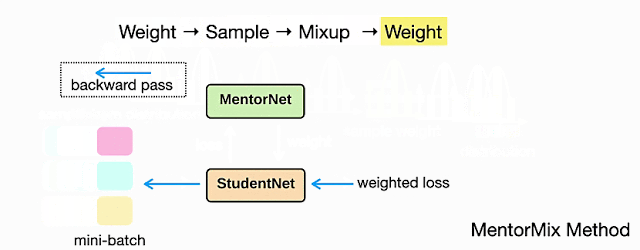
MentorMixメソッドの4つのステップの図:重み付け、サンプリング、混合、および再重み付け
評価
私達はMentorMixを5つのデータセットで評価しました。CIFAR 10/100とそれぞれに合成ラベルノイズを含めたもの、および現実世界のノイズの多いラベルが含まれる220万画像の大規模なデータセットであるWebVision 1.0です。
MentorMixは、CIFAR 10/100データセットでスコアを一貫して改善し、WebVisionデータセットでも公表結果の中で最高のスコアを達成しましました。
ImageNet ILSVRC12検証セットのtop 1分類精度に関して、以前の最良のスコアを約3%改善しました。
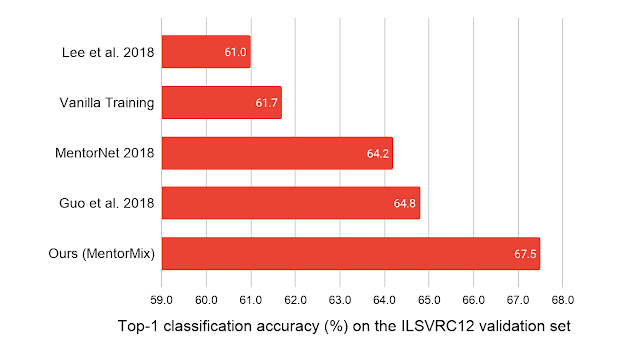
私達のモデルは、WebVisionの220万のノイズの多いトレーニングでーたでのみトレーニングされ、ImageNet ILSVRC12検証セットでテストされます。比較対象は、Lee等による2018年の「CleanNet: Transfer Learning for Scalable Image Classifier Training with Label Noise」、Lu Jiang等による2018年の「MentorNet: Learning Data-Driven Curriculum for Very Deep Neural Networks on Corrupted Labels」、およびGuo等による2018年の「CurriculumNet: Weakly Supervised Learning from Large-Scale Web Images」です。
3.MentorMix:現実世界の誤ラベルがディープラーニングに及ぼす影響を調査(2/3)関連リンク
1)ai.googleblog.com
Understanding Deep Learning on Controlled Noisy Labels
2)arxiv.org
A Closer Look at Memorization in Deep Networks
Do Better ImageNet Models Transfer Better?
Beyond Synthetic Noise: Deep Learning on Controlled Noisy Labels
CleanNet: Transfer Learning for Scalable Image Classifier Training with Label Noise
MentorNet: Learning Data-Driven Curriculum for Very Deep Neural Networks on Corrupted Labels
CurriculumNet: Weakly Supervised Learning from Large-Scale Web Images
3)github.com
google-research/mentormix/
4)google.github.io
Controlled Noisy Web Labels

コメント