
1.DADS:教師なしで有用なスキルを発見する強化学習(2/2)まとめ
・DADSは環境にとらわれないため、ロボット移動タスクにも操作タスクにも適用可能
・スキルに追加のトレーニングが必要ないため、サンプル効率が非常に高く追加トレーニングが不要
・オフポリシー学習化したoff-DADSにより現実世界のロボットに歩行スキルを学習させる事が出来た
2.off-DADSとは?
以下、ai.googleblog.comより「DADS: Unsupervised Reinforcement Learning for Skill Discovery」の意訳です。元記事の投稿は2020年5月29日、Archit Sharmaさんによる投稿です。
アイキャッチ画像はのクレジットはPhoto by Andrea Lightfoot on Unsplash
このアルゴリズムにより、報酬が発生しない環境で純粋に試行錯誤を行うだけで予測可能なスキルを様々なエージェントが発見できるようになります。
DADSは、従来の研究とは異なり、ヒューマノイドなどの二足歩行ロボットをシミュレートする高度な連続制御環境に規模を拡大できます。
また、DADSは環境にとらわれないため、移動(locomotion)と操作(manipulation)の両方の環境に適用できます。以下に、様々なエージェントが発見した継続的な制御スキルの一部を示します。

蟻型ロボットはギャロッピング(左上)とスキップ(左下)を発見し、ヒューマノイドは様々な歩行(中央、2倍速)を発見し、ROBELのD’Claw(右)はオブジェクトを回転させる様々な方法を発見しました。全てDADSを使用しています。その他のサンプル動画はsites.google.comから入手できます。
(訳注:ROBELはGoogleが開発した3Dプリンタで自作可能な安価なロボットシリーズ)
スキルダイナミクスを使用したモデルベースの制御
DADSは予測可能で潜在的に有用なスキルの発見を可能にするだけでなく、学習したスキルを下流タスクに適用する効率的なアプローチを可能にします。
まず、スキルを予測するスキルダイナミクスネットワークを利用して、各スキルの状態遷移を予測します。次に、予測された状態遷移を連鎖させていけば、環境内で実際に実行せずとも、学習したスキルが辿る完全な軌跡をシミュレートできます。これにより、様々なスキルの軌跡をシミュレーションし、特定のタスクに対して最高の報酬を得る事ができるスキルを選択する事ができます。
ここで説明しているモデルベースの計画アプローチは、スキルに追加のトレーニングが必要ないため、サンプル効率が非常に高くなります。これは、学習したスキルを組み合わせるために実行環境内で追加のトレーニングを必要とする従来のアプローチからの飛躍に繋がる重要なステップです。
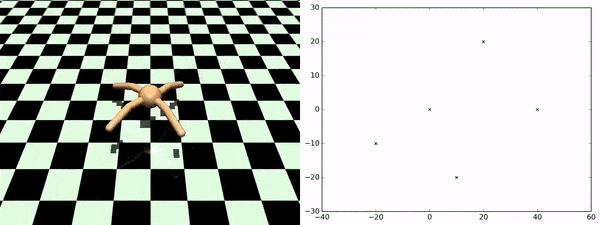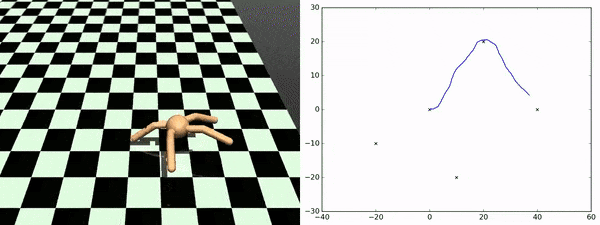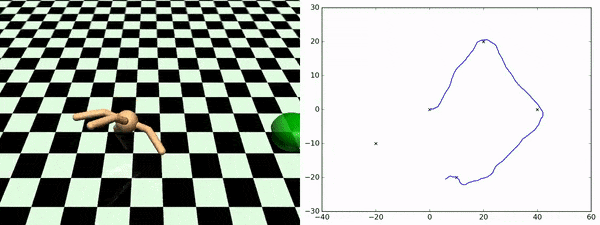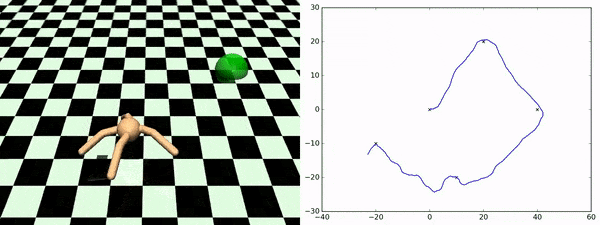
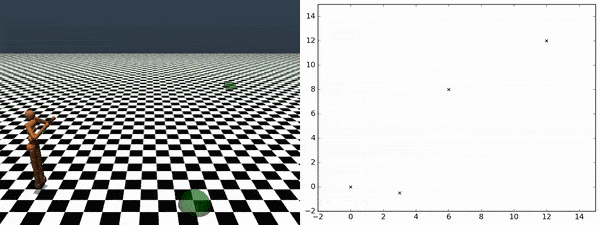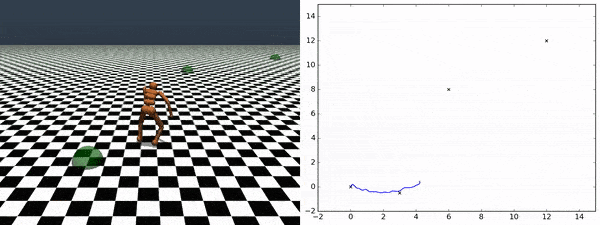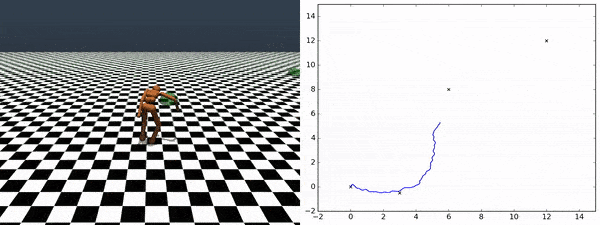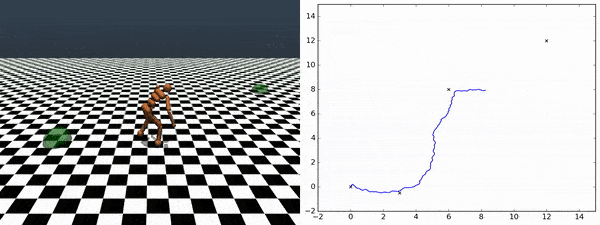
エージェントが発見したスキルを使用して、追加にトレーニングする事なしに任意のチェックポイント間を横断する事ができます。右図は、あるチェックポイントから別のチェックポイントへエージェントが移動していく様を示しています。
現実世界での結果
現実世界のロボットを使った教師なし学習のデモンストレーションはかなり制限が多いため、実験結果はシミュレーション環境内に限定されています。
論文「Emergent Real-World Robotic Skills via Unsupervised Off-Policy Reinforcement Learning」では、オフポリシー学習をアルゴリズム的および体系的に改善する事で、従来のアルゴリズムのサンプル効率を向上したoff-DADSと呼ばれるバージョンを開発しています。
オフポリシー学習では、様々なポリシーが収集したデータを使用して、現在のポリシーを改善できます。特に、以前に収集したデータを再利用して学習に使うと、強化学習アルゴリズムのサンプル効率が大幅に向上します。
オフポリシー学習による改善を活用して、D’Kitty(ROBELの4足歩行ロボット)を現実世界の環境でトレーニングしました。ポリシーはランダムに初期化され、環境からの報酬も手動で設計した探索戦略からの報酬もありません。
DADSによって定義された固有の報酬を最適化することにより、多様な歩行と方向を持つ複雑な行動が出現する事が観察されました。


off-DADSを使用して、ROBELのD’Kittyをトレーニングし、多様な歩行動作を習得しました。これを使用して、モデルベースの制御で目標地点に到達させる事ができます。
今後の研究
私達は、実世界で実行可能で実現可能性が高い、新しい教師なしスキル発見アルゴリズムで貢献しました。この研究は、最小限の人間の労力でロボットが幅広いタスクを解決できるようになる未来に向けての基盤となります。
1つの方向性は、「状態の特徴表現(state-representation)」と「DADSによって検出されたスキル」との関係を調査する事です。これにより、分布がわかっている下流タスクで、スキルの発見に繋がるような「状態の特徴表現」を学習する事が出来るかもしれません。
研究のもう1つの興味深い方向は、スキルダイナミクスを定式化する事により「高レベルの計画」と「低レベルの制御」を分離する事です。これにより、様々な強化学習問題全般への適用可能性を探ります。
謝辞
共著者のMichael Ahn, Sergey Levine, Vikash Kumar, Shixiang Gu 及び Karol Hausmanに感謝します。また、Google Brain teamの様々なメンバーやRobotics at Google teamからのサポートとフィードバックにも感謝いたします。
3.DADS:教師なしで有用なスキルを発見する強化学習(2/2)関連リンク
1)ai.googleblog.com
DADS: Unsupervised Reinforcement Learning for Skill Discovery
2)arxiv.org
Dynamics-Aware Unsupervised Discovery of Skills
Emergent Real-World Robotic Skills via Unsupervised Off-Policy Reinforcement Learning
3)sites.google.com
Dynamics-Aware Discovery of Skills

