
1.BLEURT:人工知能が生成した文章の品質を評価(3/3)まとめ
・BLEURTは、何百万もの合成文章ペアを使用してモデルを「ウォームアップ」して品質を向上した
・既存の評価手法と比較するとBLEURTは最も良く人間による品質評価と相関している事がわかった
・将来的な研究の方向性には、多言語化対応と多様な入力データを扱えるようにする事などを予定
2.BLEURTの評価
以下、ai.googleblog.comより「Evaluating Natural Language Generation with BLEURT」の意訳です。元記事の投稿は2020年5月26日、Thibault SellamさんとAnkur P. Parikhさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Hrvoje_Photography ?? on Unsplash。
BLEURTの成功は、人間による評価を微調整する前に、何百万もの文章を合成して作り出した文章ペアを使用してモデルを「ウォームアップ」することに依存しています。
ウィキペディアの文章にランダムに摂動(微妙に変更する事)を加えてトレーニングデータを生成しました。人間の評価を収集する代わりに、既存の研究(BLEUを含む)から取得した評価基準と評価モデルを使用します。これにより、非常に低コストでトレーニング例の数を増やすことができます。

BLEURTのデータ生成プロセスは、「ランダムな摂動」と「既存の評価基準と評価モデル」を組み合わせます。
実験により、特にテストデータが分類外データ(out-of-distribution)である場合、事前トレーニングによりBLEURTの精度が大幅に向上することが明らかになりました。
BLEURTは2回事前トレーニングを行います。最初に言語モデリング(元のBERTの論文で説明されています)を目的として、次にNLG評価を目的としたデータを使用して行います。次に、WMT Metrics dataset、ユーザーから提供された一連の評価、またはその両方の組み合わせでモデルを微調整します。次の図は、BLEURTのトレーニング手順をエンドツーエンドで示しています。
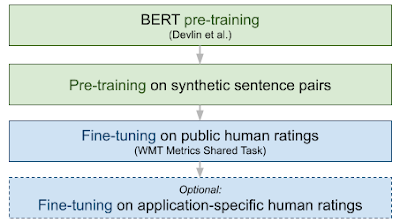
結果
私達は他の評価手法とBLEURTを比較し、BLEURTが優れたパフォーマンスを出す事を示しました。WMT Metrics Shared Task(機械翻訳タスク)とWebNLG Challenge(data-to-textタスク)では、BLEURTは最も良く人間の評価と相関しています。
例えば、BLEURTは、2019年のWMT Metrics Shared Task ではBLEUよりも約48%正確です。また、事前トレーニングがBLEURTの品質漂流(quality drift)への対処に役立つ事も示しています。

WMT’19の共有タスクで測定した各評価基準と人間による評価の相関
結論
自然言語生成(NLG:Natural Language Generation)モデルは長い年月をかけて改善されてきたため、評価指標はこの分野の研究にとって重大なボトルネックになっています。
従来の単語重複率をベースとする品質評価手法が非常に人気があるのは、十分な理由があります。それは、 シンプルで一貫性があり、トレーニングデータを必要としません。評価の際に複数の文を参照できるケースでは、非常に正確な評価をする場合があります。
それらは評価基盤として重要な役割を果たしますが、非常に保守的であり、NLGシステムのパフォーマンスの不完全な全体像しか提供しません。私達の見解では、機械学習エンジニアは、評価ツールキットをより柔軟で文章の意味まで捕捉した評価指標に強化する必要があります。
BLEURTは、表面的な単語重複による評価を超えてNLGの品質を捕捉するための私たちの試みです。BERTの特徴表現と新しい事前トレーニング手法のおかげで、私達の指標は2つの学術的ベンチマークで最先端のパフォーマンスを達成しました。現在、BLEURTを使ってGoogleサービスをどのように改善できるかを調査しています。将来的な研究の方向性には、多言語化対応と多様な入力データを扱えるようにする事(multimodality)などが予定されています。
謝辞
このプロジェクトはDipanjan Dasによって共同助言(co-advised)されました。Slav Petrov, Eunsol Choi, Nicholas FitzGerald, Jacob Devlin, Madhavan Kidambi, Ming-Wei Chang、およびGoogle Research Languageチームの全メンバーに感謝します。
3.BLEURT:人工知能が生成した文章の品質を評価(3/3)関連リンク
1)ai.googleblog.com
Evaluating Natural Language Generation with BLEURT
2)arxiv.org
BLEURT: Learning Robust Metrics for Text Generation
3)github.com
google-research/bleurt
4)www.statmt.org
ACL 2019 FOURTH CONFERENCE ON MACHINE TRANSLATION (WMT19)


コメント