
1.深層強化学習の力でロボットが俊敏で知的な移動を実現(2/3)まとめ
・ロボットにオフィス内を移動させる等の複雑なタスクは速度、方向、高さを複数回調整する必要がある
・従来は複雑なタスクを複数の階層的小タスクに分解することで解決していたがな階層の手動設計は重労働
・新しく提案された階層強化学習ではポリシーレベル間の単純な通信プロトコルのみを定義する事で解決
2.階層強化学習
以下、ai.googleblog.comより「Agile and Intelligent Locomotion via Deep Reinforcement Learning」の意訳です。元記事の投稿は2020年5月6日、Yuxiang YangさんとDeepali Jainさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Sherry Chen on Unsplash
モデル予測コントロール(MPC:Model Predictive Control)では頻繁に実行プランを更新しますが、プランナーは長期的な目標を追跡し、近視眼的な行動を回避するために、長期的視点をアクションに取り組む必要があります。そのために、マルチステップ化した損失関数(multi-step loss function)を使用します。
これは、モデルの損失関数を再公式化(reformulation)したもので、将来の一連のステップにおける損失を予測することにより、時間の経過に伴ってエラーが蓄積していく事を減らすために役立ちます。
安全性は、現実のロボットを使って学習する際のもう1つの懸念事項です。脚付きロボットの場合、足の踏み出しに失敗する等の小さなミスであってもと、ロボットが試験環境から落下する事からモーターが過熱する事まで、致命的な障害に繋がる発生する可能性があります。
安全な探求を確実にするために、適所に安定した踏み出し(in-place stepping gait)を事前に埋め込みます。これは、軌道ジェネレータによって調節され、安定した歩行を事前に行うことで、MPCは安全にアクションスペースを探索できます。
正確な動作モデル(dynamics model)をオンラインの非同期MPCコントローラーと組み合わせることで、ロボットはわずか4.5分のデータ(36エピソード)を使用して歩行を習得しました。
学習した動作モデルは一般化も可能です。MPCの報酬関数を変更するだけで、コントローラーは、再トレーニングすることなく、後方への歩行や方向転換などの様々な動作を最適化できます。
拡張機能として、同様のフレームワークを使用して、より俊敏な動作が可能になります。例えば、シミュレーションでは、ロボットはバク転や後ろ足による二足歩行を学習可能ですが、これらの動作は現実世界のロボットではまだ学習されていません。

ロボットは、わずか4.5分のデータで歩行を学習します。

ロボットは、同じフレームワークを使用して、バク転と後ろ足による二足歩行を学習します。
低レベルのコントローラーと高レベルのプランナーの組み合わせ
モデルベースのRLにより、ロボットは単純な歩行スキルを効率的に学習できましたが、そのようなスキルだけでは、複雑な現実世界のタスクを処理するには不十分です。
例えば、オフィス内を移動するためには、ロボットは、事前に定義された速度制限に従うだけではなく、速度、方向、および高さを複数回調整する必要がある場合があります。
従来、人々はこのような複雑なタスクを、複数の階層的な小タスクして分解することで解決していました。例えば、高レベルの軌道プランナーと低レベルの軌道追跡コントローラーで問題を分割して担当する事などです。
ただし、適切な階層を手動で定義することは、各小タスクについて慎重なエンジニアリングが必要であるため、通常は退屈な作業となります。
私達の2番目の論文では、複雑な強化学習タスクを自動的に分解するようにトレーニングできる階層強化学習(HRL:Hierarchical Reinforcement Learning)フレームワークを紹介します。
私達はポリシー構造を高レベルのポリシーと低レベルのポリシーに分解します。各ポリシーを手動で設計する代わりに、ポリシーレベル間の単純な通信プロトコルのみを定義します。
このフレームワークでは、高レベルポリシー(例えば、軌道プランナー)が潜在的なコマンドを介して低レベルポリシー(モーションコントロールポリシーなど)に指示を出します。また、新しいコマンドを発行する前にそのコマンドを一定期間保持し続ける期間を決定します。次に、低レベルポリシーは、高レベルポリシーからの潜在的なコマンドを解釈し、ロボットにモーターコマンドを与えます。
学習を容易にするために、観測空間も高レベル(ロボットの位置と向きなど)と低レベル(慣性計測装置、モーター位置)に分割し、対応するポリシーに与えます。 このアーキテクチャでは当然、高レベルのポリシーを低レベルのポリシーよりも遅いタイムスケールで動作させることができ、計算リソースを節約可能になり、トレーニングの複雑さを軽減します。
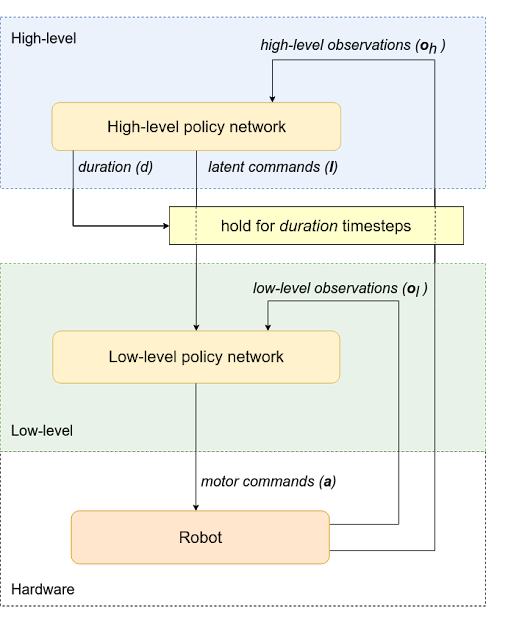
階層型ポリシーを使ったフレームワーク
ポリシーはロボットから観測を取得し、モーターコマンドを送信して目的のアクションを実行します。これは高レベルと低レベルに分かれています。高レベルポリシーは、低レベルポリシーに潜在的なコマンドを提供し、低レベルが実行される期間も決定します。
3.深層強化学習の力でロボットが俊敏で知的な移動を実現(2/3)関連リンク
1)ai.googleblog.com
Agile and Intelligent Locomotion via Deep Reinforcement Learning
2)arxiv.org
Data Efficient Reinforcement Learning for Legged Robots
Hierarchical Reinforcement Learning for Quadruped Locomotion
