
1.Seq2act:機械学習でスマホ操作を人間の代わりに実行する(2/2)まとめ
・モデルをトレーニング、および評価するための3つの新しいデータセットを構築して公開
・「アクションフレーズの抽出」と「言語の割り当て」に分解してモデルパフォーマンスを向上させた
・今回の研究対象はAndroidのUIを使ったが他のユーザーインターフェイスにも応用は可能
2.Seq2actの概要
以下、ai.googleblog.comより「Grounding Natural Language Instructions to Mobile UI Actions」の意訳です。元記事の投稿は2020年7月10日、Yang Liさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Velizar Ivanov on Unsplash
アクションフレーズ抽出ステップでは、Transformerモデルを使用し、多段階にわたる命令から「操作内容の説明」、「操作対象オブジェクトの説明」、および「操作時の引数の説明」を識別します。
識別時は、Area Attentionを使います。これにより、モデルが隣接する単語のグループに注意を払いつつ、説明をデコードできます。
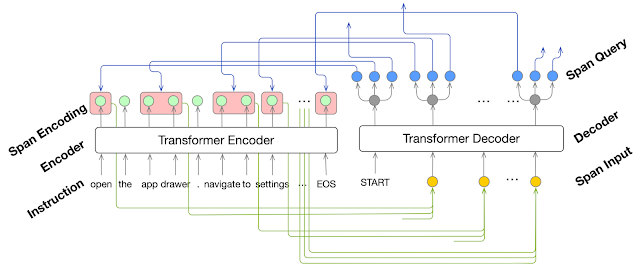
アクションフレーズ抽出モデルは、自然言語による指示を単語の並びとして受け取り、それを区切って(赤い箱で表現)出力します。区切る期間(スパン)は、各操作の説明、オブジェクトの説明、各操作時に与える引数です。
次に、割り当て(グラウンディング)ステップは、抽出された操作とオブジェクトの種類を画面上のユーザインタフェースオブジェクトと照合します。
この場合も、Transformerモデルを使用しますが、特徴表現はユーザインタフェースオブジェクトと割り当て先のオブジェクトの種類に基づく事になります。
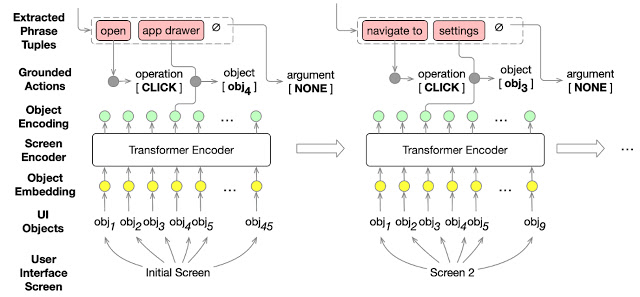
割り当て(grounding :グラウンディング)タスクは、抽出された期間を入力として受け取り、実行可能なアクションにそれらを割り当てます。ユーザインタフェース画面が与えられた場合、割り当て対象は、実行中の各ステップでアクションの対象となるオブジェクトも含みます。
結果
このタスクの実行可能性とアプローチの有効性を調査するために、モデルをトレーニング、および評価する3つの新しいデータセットを構築しました。
最初のデータセットは、エンドツーエンドで自然言語を操作に割り当てる知識をテストするために使用されます。これは、順番に沿ってPixelスマートフォンの画面を操作する187ステップの英語による指示を理解するタスクのパフォーマンス評価を可能にします。
「アクションフレーズ抽出」のトレーニングと評価のために、インターネットから豊富に入手できる英語の「ハウツー」指示を取得し、各アクションを説明するフレーズに注釈を付けました。
「グラウンディングモデル」、すなわち「言語を具体的なコマンドに割り当てる接地モデル」をトレーニングするために、ユーザインタフェース操作に295,000のシングルステップコマンドを合成して生成しました。このコマンド群は公開されているAndroid ユーザインタフェースデータから2,500の操作画面を抜き出し、全体で178,000の異なる操作対象をカバーしています。
Area AttentionベースのTransformerは、真のラベルと完全に一致するスパンシーケンスを85.56%の精度で予測します。フレーズ抽出モデルと割り当てモデルを組み合わせると、自然言語による指示を実行可能な操作にエンドツーエンドでマッピングするというより困難なタスクで正解ラベルに一致する操作手順を部分精度で89.21%、完全精度で70.59%が得る事ができます。
また、「ユーザインタフェースオブジェクトの特徴表現」や「モデル」について代替手段を評価したところ、グラフ畳み込みネットワーク(GCN)やフィードフォワードネットワークの使用など、画面内で状況に応じてオブジェクトを表現できるものが、割り当て精度を向上させる事がわかりました。
新たなデータセット、モデル、および結果は、自然言語の命令をモバイルUIアクションに割り当てるという困難な問題への重要な最初のステップを提供します。
結論
本研究、および言語接地に関する研究は、多数の段階にわたる指示をGUI(グラフィカルユーザーインターフェイス)操作に変換するための重要なステップです。
グラフィカルなユーザ操作が自動化出来るようになると、アクセシビリティが大幅に向上する可能性があります。言語による操作指示は、視覚障害者が視覚に基づく操作指示を実行する際に役立つ場合があります。これは、手元が塞がってデバイスに簡単にアクセスできない状況にも応用できるため重要です。
問題を「アクションフレーズの抽出」と「言語の割り当て」に分解することで、どちらかを上手く進めれば、タスクパフォーマンスを向上させることができます。これにより、大規模に収集することが難しい言語とアクションのペアのデータセットを用意する必要がなくなります。
例えば、アクションスパンの抽出は、「意味的役割のラベル付け(semantic role labeling)」と「テキストからの複数の事実の抽出」の2タスクに関連しており、スパン識別とマルチタスク学習の2分野における革新の恩恵を受けることができます。
以前の研究で活用された強化学習は、ユーザインタフェースにおける分類外データの予測を改善する事が出来るので、内部特徴表現を直接改善するのに役立ちます。
私達のデータセットはAndroidのユーザインタフェースに基づいていますが、私達のアプローチは他のユーザーインターフェイスプラットフォームでも一般的な命令の理解に適用できます。最後に、私達の研究は、言語ベースの人間とコンピューターの相互作用におけるユーザーエクスペリエンスを調査するための技術的基盤を提供します。
謝辞
共同執筆者のJiacong He, Xin Zhou, Yuan Zhang および Jason Baldridgeに、Google Researchでの本研究について感謝します。また、オープンソースのデータセットを作成するための寛大な支援を提供してくれたGang Liと、注釈に関する支援をしてくれたAshwin Kakarla, Muqthar Mohammad 及び Mohd Majeedにも感謝します。
3.Seq2act:機械学習でスマホ操作を人間の代わりに実行する(2/2)関連リンク
1)ai.googleblog.com
Grounding Natural Language Instructions to Mobile UI Actions
2)arxiv.org
Mapping Natural Language Instructions to Mobile UI Action Sequences
3)github.com
google-research/seq2act/


コメント