
1.強化学習を使って量子計算を改善(2/2)まとめ
・次のステップとして量子制御コスト関数をオンポリシーRLを使って最適化した
・オンポリシーRLとオフポリシーRLの違いは制御ポリシーが制御コストとは独立して表されること
・新しいフレームワークの下では従来のアプローチに比べて量子ゲートエラーが100倍減少した
2.オンポリシー深層強化学習
以下、ai.googleblog.comより「Improving Quantum Computation with Classical Machine Learning」の意訳です。元記事は2019年10月3日、Murphy Yuezhen NiuさんとSergio Boixoさんによる投稿です。
新しい量子制御コスト関数が用意できたので、次のステップは効率的な最適化ツールを使って最小化することです。既存の最適化方法は、高い忠実度を持ち且つ変動を堅牢に制御するソリューションを見つけるためには不十分な事がわかりました。
代わりに、オンポリシー深層強化学習(RL)メソッドである高信頼領域RL(trusted-region RL)を適用しました。
この手法は、全てのベンチマーク問題で良好なパフォーマンスを示し、本質的にサンプルノイズに対して耐久性を持ち、数億の制御パラメーターを扱う困難な制御問題を最適化する性能を備えています。
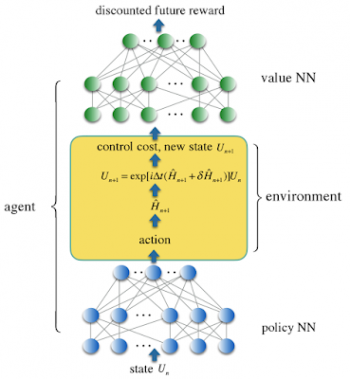
このオンポリシーRLと以前に研究されていたオフポリシーRLの顕著な違いは、制御ポリシーが制御コストとは独立して表されることです。
QラーニングなどのオフポリシーRLは、単一のニューラルネットワーク(NN)を使用して、制御軌跡(control trajectory)と関連する報酬の両方を表します。制御軌跡は、異なる時間ステップで量子ビットに結合される制御信号を指定します。そして、関連する報酬は、量子制御の現在のステップがどれだけ良いかを評価します。
オンポリシーRLは、制御軌跡で非局所的特徴を活用する機能でよく知られています。これは、制御状況(control landscape)が高次元であり、多数の非グローバルソリューションが詰め込まれている場合に重要になります。(これは量子システムではよくある状況です)
私達は制御軌跡を3層の完全接続されたポリシーニューラルネットワーク(policy NN)にエンコードしました。そして、制御コスト関数を2番目のバリューニューラルネットワーク(value NN)にエンコードしました。value NNは報酬を将来価値で割り引いてエンコードします。
堅牢な制御ソリューションは、強化学習エージェントによって得られました。強化学習エージェントは、現実的なノイズの多い制御動作を模倣する確率的環境で両方のNNをトレーニングします。
私達は量子化学アプリケーションに重要な、連続的にパラメーター化された2量子ビット量子ゲート(two-qubit quantum gates)のセット用の制御ソリューションを提供できました。ただし、従来のユニバーサルゲートセット用に実装するにはコストがかかります。
この新しいフレームワークの下では、数値シミュレーションにより、ユニバーサルゲートセットを使用した従来のアプローチに比べて、量子ゲートエラーが100倍減少する事が示されています。更に連続的にパラメータ化されたシミュレーションゲートファミリのゲート時間も平均で1桁削減しています。
本研究は、研究は、新しい機械学習技術と短期の量子アルゴリズムを併用することの重要性を強調しています。これにより、汎用的な量子制御方式に柔軟性と追加の計算能力を活用できます。
この研究で開発されたような機械学習技術を実用的な量子計算手順に統合して、機械学習により計算能力を完全に向上させるには、さらに実験が必要です。
3.強化学習を使って量子計算を改善(2/2)関連リンク
1)ai.googleblog.com
Improving Quantum Computation with Classical Machine Learning
2)www.nature.com
Universal quantum control through deep reinforcement learning(PDF)
3)arxiv.org
High-Dimensional Continuous Control Using Generalized Advantage Estimation
