
1.MediaPipeを利用してオンデバイスでリアルタイムに手の動きを知覚(2/2)まとめ
・手の形状を認識するランドマークモデルは手動でラベル付けされたデータに加えて合成画像も使用
・純粋な合成画像では一般化性能が低下するため混合トレーニングスキーマを使用している
・ハンドトラッキング用のMediaPipeは手のひら検出器を必要な時だけ呼び出す事で省力化している
2.MediaPipeを介した具体的な実装
以下、ai.googleblog.comより「On-Device, Real-Time Hand Tracking with MediaPipe」の意訳です。元記事は2019年8月19日、Valentin BazarevskyさんとFan Zhangさんによる投稿です。
手のランドマークモデル
画像全体で手のひらを検出した後、後続の手のランドマークモデルは、回帰予測、つまり直接座標予測を行います。検出された手が写っている領域内で、21点の3Dハンドナックル座標の正確なキーポイントを予測します。
モデルは手のポーズに対して、一貫した内部特徴表現を学習しているため、部分的にしか見えない手や握った状態の手であっても堅牢に検出できます。
本当の手のポジションデータを取得するために、下図に示すように、現実世界の約30,000の画像に3D座標で21点の座標を手動で付けました。(対応する座標が存在する場合、画像深度マップからZ値も取得します)。
取り得る手のポーズをよりよくカバーし、手が取りうるポジションの性質をより多くの教師データとするため、様々な背景と手のモデルを高品質に合成レンダリングし、対応する3D座標にマップしました。

上:人間が付与した真のラベルを使用してポジションデータをマッピングし、次にトラッキングネットワークに渡されます。下:人間が付与した真のラベルを付きの手の画像に背景を合成した画像
ただし、完全な合成データは、実世界の領域に適用する際の一般化性能が不十分になります。この問題を克服するために、混合トレーニングスキーマ(Mixed training schema)を利用します。 高レベルのモデルトレーニング図を次の図に示します。
![]()
ハンドトラッキングネットワーク為の混合トレーニングスキーマ。切り取られた実世界の写真とレンダリングされた合成画像は、21の3Dキーポイントを予測するための入力として使用されます。
次の表は、トレーニングデータの性質毎に回帰精度をまとめたものです。合成データと実世界のデータの両方を使用すると、パフォーマンスが大幅に向上します。
| Dataset | Mean regression error normalized by palm size |
| Only real-world | 16.10% |
| Only rendered synthetic | 25.70% |
| Mixed real-world + synthetic | 13.40% |
予測された手のスケルトンの上に、簡単なアルゴリズムを適用してジェスチャーを導き出します。まず、各指の状態、例えば、曲げられているか直線であるかは、関節の角度によって決まります。次に、指の状態のセットを定義済みのジェスチャのセットにマッピングします。この簡単で効果的な手法により、基本的な静的ジェスチャーを妥当な品質で推定できます。
既存のパイプラインは、複数の文化からのジェスチャーのカウントをサポートしています。アメリカ、ヨーロッパ、および中国、および「サムアップ(親指を立てるジェスチャー)」、「閉じた拳」、「OK」、「ロック」、そして「スパイダーマン(スパイダーマンが手から糸を出す時のポーズ)」を含むさまざまな手のサインがサポートされています。


MediaPipeを介した実装
MediaPipeを使用すると、この知覚パイプラインは、演算機(Calculators)と呼ばれるモジュールコンポーネントで有向グラフとして構築できます。Mediapipeには、モデルの推論、メディア処理アルゴリズム、様々なデバイスやプラットフォームにわたるデータ変換などのタスクを解決するための拡張可能な演算機セットが付属しています。
トリミング、レンダリング、ニューラルネットワーク計算などの個々の演算機は、GPUでのみ実行できます。 たとえば、最新の携帯電話ではTFLite GPU推論を採用しています。
ハンドトラッキング用のMediaPipeグラフを以下に示します。グラフは2つのサブグラフで構成されます。1つは手の検出用、もう1つは手のキーポイント(つまり、ランドマーク)計算用です。
MediaPipeが提供する重要な最適化の一つは、手のひら検出器が必要な場合にのみ(ごく稀に)実行され、計算時間を大幅に節約できることです。これは、最初のフレームで計算された手のキーポイントから後続のビデオフレーム内の手の位置を推測することで達成されています。これにより、各フレームで手のひら検出器を実行する必要がなくなります。
堅牢性を向上するために、ハンドトラッカーモデルは、切り抜きデータ内に手が存在しているか否かの信頼度を表す追加のスカラー値を出力しています。信頼度が定めた閾値を下回った場合にのみ、手のひら検出器モデルがフレーム全体に再適用されます。
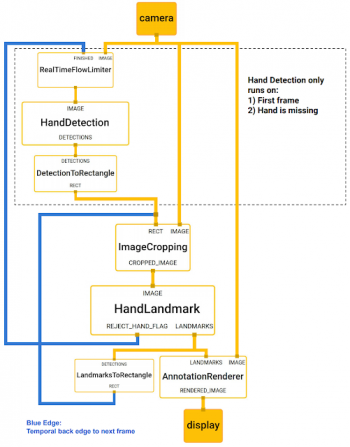
手のランドマークモデルの出力(REJECT_HAND_FLAG)は、手のひら検出モデルが起動されるタイミングを制御します。この動作は、MediaPipeの強力な同期実現機構によって実現され、MLパイプラインの高いパフォーマンスと最適なスループットを実現します。
リアルタイムで、様々な異なるプラットフォームと形式で実行される非常に効率的なMLソリューションには、上記の簡略化された説明できたものよりもかなり複雑なものが含まれます。
理解を促進するために、MediaPipeフレームワークで上記のハンドトラッキングおよびジェスチャ認識パイプラインを公開し、関連するエンドツーエンドの使用シナリオとソースコードをgithubで公開します。これにより、研究者と開発者は、モデルに基づいた新しいアイデアの実験とプロトタイピングのための完全な仕組みを利用できます。
今後の方向性
このテクノロジーをより堅牢で安定した追跡で拡張し、確実に検出できるジェスチャーの量を増やし、時間内に展開する動的なジェスチャーをサポートする予定です。 このテクノロジーの公開は、研究および開発者コミュニティ全体のメンバーによる新しい創造的なアイデアやアプリケーションに刺激を与えることができると考えています。 あなたがそれを使って何を構築するのか見るのを楽しみにしています!
![]()
謝辞
この技術の開発に携わってくれたチームメンバー全員に感謝します。Andrey Vakunov, Andrei Tkachenka, Yury Kartynnik, Artsiom Ablavatski, Ivan Grishchenko, Kanstantsin Sokal, Mogan Shieh, Ming Guang Yong, Anastasia Tkach, Jonathan Taylor, Sean Fanello, Sofien Bouaziz, Juhyun Lee, Chris McClanahan, Jiuqiang Tang, Esha Uboweja, Hadon Nash, Camillo Lugaresi, Michael Hays, Chuo-Ling Chang, Matsvei Zhdanovich, そしてMatthias Grundmann。
3.MediaPipeを利用してオンデバイスでリアルタイムに手の動きを知覚(2/2)関連リンク
1)ai.googleblog.com
On-Device, Real-Time Hand Tracking with MediaPipe
2)arxiv.org
BlazeFace: Sub-millisecond Neural Face Detection on Mobile GPUs
3)github.com
google/mediapipe
4)sites.google.com
Face Mesh
