
1.教師あり学習を使い音声データから個々人の声を聞き分けるまとめ
・音声データから誰が話しているか話し手を区別するダイアリゼ―ションの新手法の発表
・教師あり学習ができるためラベル付きデータを有効活用して教師あり学習で品質を向上できる
・従来のクラスタリングを使った手法より早く正確なダイアリゼ―ションが実現可能
2.RNNを利用したダイアリゼーションとは?
以下、ai.googleblog.comより「Accurate Online Speaker Diarization with Supervised Learning」の意訳です。元記事は2018年11月12日、Chong Wangさんによる投稿です。
話し手のダイアリゼーション(Diarization:いつ誰が話したのかを推定する事)は、複数の人が会話している音声データから各個人の音声を分離するプロセスで、音声認識システムにとって重要な機能です。「誰がどのタイミングで発言したか?」という問題を解決することによって、ダイアリゼーションは、医学の専門用語が使われている難しい会話の理解やビデオ字幕の作成など、多くの重要な場面に応用できます。
しかし、教師あり学習でこれらのシステムを訓練することは困難です。教師あり学習が使われる一般的な分類タスクとは異なり、堅牢なダイアリゼーションモデルは、学習時に使った音声データには含まれていなかった個人の声も着実に聞き分ける能力が求められるためです。
重要なことは、この能力がオンラインでもオフラインでも、両方のシステムで求められる事です。オンラインシステムでは、通常、分析結果をリアルタイムに出力する事が必要となるため、より多くの困難に直面します。
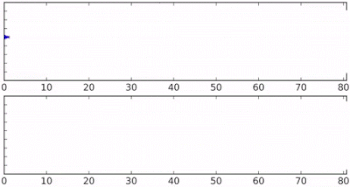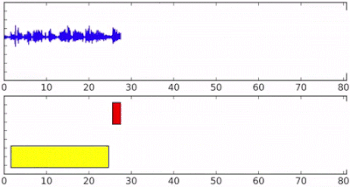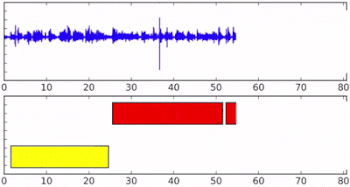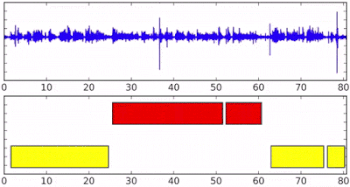
ストリーミングオーディオ入力時のオンラインスピーカーダイアリゼーション。下の軸の異なる色は、異なる話者が識別された事を示しています。
論文「Fully Supervised Speaker Diarization」では、ラベルを付与されたデータを使って教師付き学習でより効果的に学習する新しいモデルについて説明しています。タイトルの「Fully(全て)」とは、話者数の推定を含む、スピーカーダイアリゼーションシステムの全てのコンポーネントが教師付き学習で訓練可能なため、利用可能なラベル付きデータの量を増やせば品質を高めることができるのです。
NIST SRE 2000 CALLHOMEベンチマークでは、従来のクラスタリングベース手法によるダイアリゼーションエラー率(DER)は8.8%、ディープニューラルネットワークとembeddingsを使った手法は9.9%であり、これらと比較して、本件のDER7.6%は低いです。さらに、本手法では、この低いダイアリゼーションエラー率をオンラインデータを扱う際に達成しているため、リアルタイムアプリケーションに適用する事が可能です。私達は、本研究の方向性を加速するため、今回の論文でコアアルゴリズムを公開しました。
クラスタリング対Interleaved-state RNN(インターリーブ ステート リカレントネットワーク)
近代的なダイアリゼーションシステムは、通常、k-mean法またはスペクトルクラスタリングなどのクラスタリングアルゴリズムに基づいています。これらのクラスタリング手法は教師なし学習の手法であるため、ラベル付きデータ、つまり教師あり学習が実行できるデータがあってもそのデータを有効活用することができませんでした。さらに、一般的なクラスタリングアルゴリズムをオンライン、つまりストリーミングオーディオをリアルタイムで解析させる作業に適用すると品質は悪化します。
私達の今回のモデルと一般的なクラスタリングアルゴリズムとの主な違いは、私達の方法では、全ての話者のembeddingsをパラメータを共有させた個別のリカレントニューラルネットワーク(RNN)によってモデル化し、それぞれの話者にそれぞれのRNNを割り当て、話者が変化すると使用するRNNを切り替える(インターリーブ)事です。
これがどのように作用するのかを理解するために4人の話者がいる以下の図をみてください。青、黄、ピンク、緑がそれぞれの話者の表します。(話者の数は任意です。実際にはもっと多く人がいるかもしれません。私達のモデルは、任意の話者に対応するため「中華料理店過程(Chinese restaurant process:大量の円卓が無限に並べられた中華料理店に顧客が無限にやってきてどの円卓に座るかを考える問題。顧客は既に人が座っている円卓を選ぶかもしれないし、誰も座っていない円卓を選ぶかもしれない)」と言う離散確率過程の一種を使っています。)
各話者は、独自のRNNインスタンス(初期パラメーターは全ての話者で共有されています)が割り当てられており、ある話者からの新しいembeddingsは全て割り当てられたRNNに入力されます。下の例では、黄色の別の話者が話し出すまで、青い話者がRNNの状態を更新し続けます。
青色の話者が後で再び話し出した場合は、青に割り当てたRNNの更新を再開します。これは、下の図のy7=1のケースですが、誰が発言するかはわからないので可能性の1つに過ぎません。もし、y7=4で新しい話者である緑が発言をしだすと、新しい緑用のRNNインスタンスが開始されます。
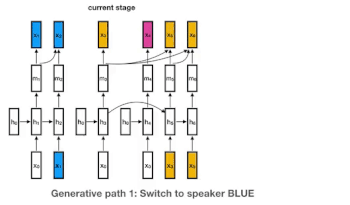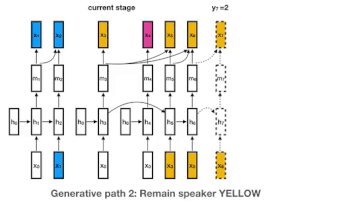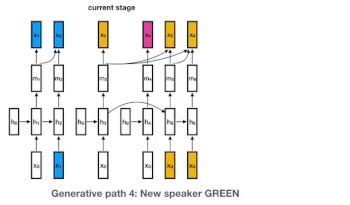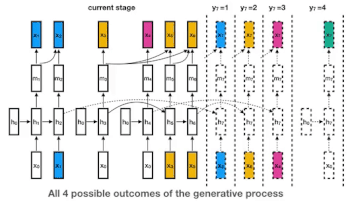
我々のモデルの生成過程。色は話者が異なる事を示しています。
各話者を各RNNの状態として表現することにより、RNNを使用して、異なる話者と発言にまたがって共有された高度な知識を学習することができ、ラベル付きデータをより有効活用できます。対照的に、一般的なクラスタリングアルゴリズムは、ほとんどの場合、各発声ごとに独立して動作するため、大量のラベルデータの恩恵を受けることは困難です。
この手法であれば、音声データに「誰がいつ話したか?」を知る事ができるラベルが付与されていた時、標準的な確率的勾配降下アルゴリズムでモデルを訓練することができるのです。学習済モデルは、学習時に聞いた事のない話者に対するダイアリゼーションに使用できます。さらに、シビアな応答速度を求められるアプリケーションの要求にも応える事ができます。
今後の研究
このシステムは既に優れたダイアリゼーション性能を達成していますが、現在検討中の多くのエキサイティングな可能性があります。まず、モデルを改良し、文脈情報を簡単に統合できるようにし、オフラインでの実行を可能にします。これにより、ダイアリゼーションエラー率がさらに低下する可能性があります。また、これは、遅延に敏感でないアプリケーションにとってはより有用です。次に、dベクトルを使用する代わりに、音響特性を直接モデリングしたいと考えています。このようにすれば、スピーカダイアリゼーションシステム全体をエンドツーエンドで訓練することができます。
この研究の詳細については、私達の論文を参照してください。このシステムのコアアルゴリズムをダウンロードするには、Githubの該当ページをご覧ください。
謝辞
この作業は、Google AIとスピーチ&アシスタントチームの緊密な連携として行われました。貢献者には、Aonan Zhang(インターン)、Quan Wang、Zhengyao Zhu、Chong Wangが含まれます。
3.教師あり学習を使い音声データから個々人の声を聞き分けるまとめ
1)ai.googleblog.com
Accurate Online Speaker Diarization with Supervised Learning
2)arxiv.org
Fully Supervised Speaker Diarization
3)github.com
Unbounded Interleaved-State Recurrent Neural Network (UIS-RNN) algorithm


コメント