
1.TCC:繰り返し動作に着目して動画を理解する学習手法(2/2)まとめ
・TCCを使うとポーズ、照明、ボディ、オブジェクトの種類などの差異に関わらず同じ動作を特定できる
・そのため、ラベル付き画像が少数しかない状態でアクションの分類や様々なアプリケーションに応用可
・教師無し学習で多数のビデオから同じ動作を切り出す事や特定のフレームを含む動画を検索する事も可能
2.TCCを利用したアプリケーション
以下、ai.googleblog.comより「Video Understanding Using Temporal Cycle-Consistency Learning」の意訳です。元記事は2019年8月8日、Debidatta Dwibediさんによる投稿です。
TCCは何を学習するのでしょうか?
下図は、スクワット動作を行っている人々の動画に対してTCCを使用して学習させたモデルを示しています。(ペンシルベニア大学がPenn Action Datasetとして公開している動画データセットを使用しています)
左側の円の各ポイントはフレームのembeddingsに対応し、ハイライトされた箇所が現在のビデオフレームを表現するembeddingsです。
右側の各動画はポーズ、照明、ボディ、オブジェクトの種類に多くの違いがあるにもかかわらず、ハイライトされたembeddingsがどのように集団的に移動するかに注目してください。
TCCによるembeddingsは、各フレームに明示的なラベルが提供されていなくとも、スクワットの様々なフェーズをエンコードできています。

右:スクワット運動を行う人々のビデオ一覧。左上のビデオが参照されている動画です。その他のビデオは、スクワットをしている他の人々の動画の(TCCのembeddings空間内で)最近傍フレームを示しています。左:スクワットが実行されると共に、対応する各フレームのembeddingsが移動しています。
TCCを利用したアプリケーション
学習したフレームごとのembeddingsにより、さまざまな興味深いアプリケーションが可能になります。
1)ラベル付き画像が少数しかない状態でアクションの分類
トレーニング用のラベル付きビデオがほとんどない場合でも、TCCは非常にうまく機能します。
実際、TCCはわずか1つのラベル付きビデオで様々なアクションを分類できます。次の図では、他の教師あり学習および自己教師付き学習アプローチと比較しています。教師あり学習では、各フレームに一つずつラベルを付けた約50本のビデオでようやく、完全にラベル付けされた一本のビデオから自己教師付き学習(TCL:Time-Contrastive Networks)が達成したのと同じ精度を達成しました。
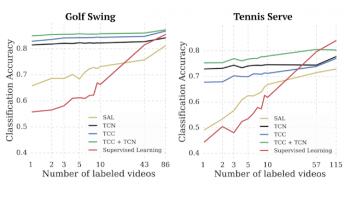
利用できる教師用データが少ない状況で自己教師あり学習と教師あり学習のアクション分類精度の比較。
2)教師無し学習でビデオを切り出す
ビデオの数が増えると、ビデオを手動で整列または同期させることは非常に難しくなります。
TCCを使用すると、下図に示すように、追加のラベルを必要とせずに、参照ビデオの各フレームに最も近い隣接フレームを選択することにより、多くのビデオを整列できます。

TCC空間のフレーム間の距離を使用して野球のピッチングを行う人々のビデオを教師なしで切り出した結果。位置合わせに使用される参照ビデオは、左上のパネルに表示されています。
3)ビデオ間でラベルや音声などの情報を転送
TCCがembeddings空間で最近傍検索を使用して似ている画像フレームを検出するように、あるビデオのフレームに関連付けられたメタデータを別のビデオの一致するフレームに転送する事ができます。このメタデータは、ラベルまたはサウンドやテキストなどの時間と共に変化するデータを含む事ができます。次のビデオでは、カップに注がれる液体の音をあるビデオから別のビデオに転送した2つの例を示します。
4)フレームを指定して同じ動作を含む動画を検索
TCCを使用すると、学習したembeddings空間内の最近傍を検索することで、類似したフレームを検索する機能を実現できます。embeddingsは、ボウリングボールのリリースの直前または直後のフレームなど、よく似たフレームを区別するのに十分強力です。

フレーム単位でビデオから検索を実行できます。つまり、任意の画像を使用して、大規模なビデオコレクションから類似のフレームを検索する事ができるのです。取得された最近傍は、モデルがシーンの細かな違いをキャプチャ出来ている事を示しています。
リリース
私達はソースコードをリリースしています。これには、TCCを含む、最先端の自己教師型学習メソッドの実装が含まれています。このコードベースは、ビデオ理解に取り組んでいる研究者や、機械学習を使用してビデオを調整して、人、動物、および同期して移動するオブジェクトのモザイクを作成しようとしているアーティストに役立ちます。
謝辞
これは、Yusuf Aytar, Jonathan Tompson, Pierre Sermanet, そして Andrew Zissermanとの共同研究です。著者等は、Alexandre Passos, Allen Lavoie, Anelia Angelova, Bryan Seybold, Priya Gupta, Relja Arandjelovi?, Sergio Guadarrama, Sourish Chaudhuri, そしてVincent Vanhouckeにこのプロジェクトに協力してくれたことに感謝します。このプロジェクトで使用されるビデオは、PennActionデータセットから取得されました。 PennActionの作成者に、このような興味深いデータセットをまとめ上げてくれた事に感謝します。
3.TCC:繰り返し動作に着目して動画を理解する学習手法(2/2)まとめ
1)ai.googleblog.com
Video Understanding Using Temporal Cycle-Consistency Learning
2)sites.google.com
Temporal Cycle-Consistency Learning
3)github.com
google-research/tcc/
4)dreamdragon.github.io
Penn Action
5)arxiv.org
Time-Contrastive Networks: Self-Supervised Learning from Video


コメント