
1.TCC:繰り返し動作に着目して動画を理解する学習手法(1/2)まとめ
・特定の順序で行われる動作はキーとなる動作が常に存在し、他の条件が異なっても共通である
・例えばワインでもお茶でも水でも注ぐと言う動作には入れ物を手で掴む動作が必ず存在する
・このような時間的に一貫性を持つサイクルを学習し、動画をきめ細かく理解可能にするのがTCC
2.Temporal Cycle-Consistencyとは?
以下、ai.googleblog.comより「Video Understanding Using Temporal Cycle-Consistency Learning」の意訳です。元記事は2019年8月8日、Debidatta Dwibediさんによる投稿です。
2020年7月追記)後続研究としてRepNetが発表されました。
ここ数年、AIによる動画理解の研究は大きな進歩を遂げました。例えば、教師あり学習と強力なディープラーニングモデルを使用して、ビデオ内で考えられる多くのアクションを分類し、動画全体を要約する単一のラベル付けをする事などができるようになっています。
ただし、動画全体に複数のラベルが必要になる多くのケースが存在します。例えば、ロボットがカップに水を注ぐ時、「液体を注いでいる」という状況をカメラ動画から認識するだけでは「水が溢れそう」という状況を予測する事はできません。そのためには、カップに水が注がれているときに、カップ内の水の量をフレームごとに追跡する必要があります。
同様に、ピッチャーの投球を比較している野球のコーチは、ボールがピッチャーの手から離れる瞬間からキャッチャーのミットに収まる瞬間までの動画を正確に切り出したい場合があります。このようなアプリケーションを実現するためには、ビデオの各フレームを理解するモデルが必要です。
ただし、教師あり学習でこれを解決しようとすると非常にコストが高くなってしまいます。ビデオの個々のフレームをモデルに理解させるために、ビデオの各フレームにラベル付けをする必要が出てくるためです。これは、ラベル付け作業者が、膨大なビデオの全てのフレームに、関心のあるアクションについて、粒度が細かく曖昧でない明確なラベルを手動で追加する必要がある事を意味します。
このラベル付けを実行したとしても、このラベルは特定事例の単一アクションでのみ、モデルをトレーニングするために使用できます。新しいアクションのトレーニングをするためには、コストの高いラベル付けプロセスを繰り返す必要があります。
ロボット工学からスポーツアナリティクスに至るまでの、様々な用途に必要なきめ細かなラベリングに対する需要の高まりに伴い、退屈なラベリングプロセスなしで動画を理解できるスケーラブルな学習アルゴリズムの必要性が高まっています。
この度、私達は、時間的サイクル一貫性学習(TCCL:Temporal Cycle-Consistency Learning)と呼ばれる自己教師付き学習法を使用した潜在的な解決策を提案します。
この斬新なアプローチは、繰り返される連続動作の類似性を利用して「ビデオを詳細に時間軸で理解する」ために特に適した特徴表現を学習します。
また、エンドユーザーが自己教師型学習アルゴリズムを新しいアプリケーションに適用できるようにするために、TCCのコードを公開しています。
TCCを使用した視覚的特徴表現学習
苗木から木に成長する植物。 起きて、仕事に行って、家に帰るという毎日のルーチン。または自分のコップに一杯の水を注ぐ事は、すべて特定の順序で発生するイベントの一例です。このような順序的プロセスを録画するビデオは、同じプロセスであれば、内容が異なっていても、時間的な類似性を提供しています。
例えば、飲み物を注ぐ時は、ティーポット、ワインのボトル、またはガラスのコップなどに人は手を伸ばします。
「飲み物を注ぐ動画」には全て「キーとなる重要な瞬間」があるのです。例えば、「飲み物が入っている入れ物に触れる」「入れ物を地面から持ち上げる」など。これの瞬間は、他の多くの様々な要因、視点の変化、動画の倍率、入れ物の形状、注ぐ動作の速度、などに関係なく常に存在します。
TCCは、サイクルの一貫性の原則を活用することで、同じアクションのビデオ全てでこのような対応を見つけようとします。これは、コンピュータビジョンの多くの問題にうまく適用されており、ビデオを調整することにより有用な視覚的特徴表現を学習します。
このトレーニングアルゴリズムの目的は、ResNetなどの画像を処理するネットワークアーキテクチャを利用して、フレームエンコーダーを学習することです。
これを実現するめには、ビデオの全てのフレームをエンコーダーに通して、対応するembeddingsを作成します。
次に、ビデオ1(参照用ビデオ)とビデオ2の2つのビデオをTCC学習用に選びます。
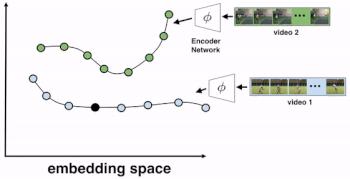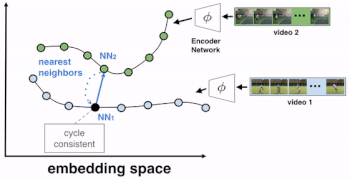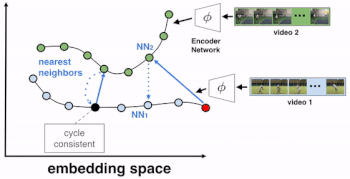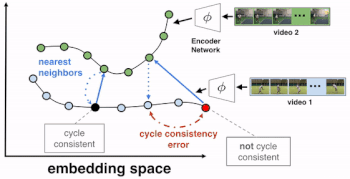
ビデオ1から参照フレームが選択され、ビデオ2から最も近い隣接フレームNN2(nearest neighbor frame)が選択されます。NN2は、embedding空間(ピクセル空間ではありません)に存在します。
次に、ビデオ1でNN2の最近傍を見つけ、これをNN1とします。もし、特徴表現のサイクルが一貫している場合、NN1の最も近い隣接フレームは、最初の参照フレームとなるはずです。
最初の参照フレームとNN1の間の距離をトレーニング信号として使用して、embedding作成器をトレーニングします。トレーニングが進むにつれて、各ビデオフレームで実行されているアクションが何であるかが意味ある単位で把握されていき、embeddingは改善され、サイクルの一貫性損失は低減していきます。

TCCを使用して、関連するビデオを時間的に整列させる事により、アクションを時間的にきめ細かく理解したembeddingsを作る事ができます。
3.TCC:繰り返し動作に着目して動画を理解する学習手法(1/2)関連リンク
1)ai.googleblog.com
Video Understanding Using Temporal Cycle-Consistency Learning
2)sites.google.com
Temporal Cycle-Consistency Learning
3)github.com
google-research/tcc/
4)dreamdragon.github.io
Penn Action
5)arxiv.org
Time-Contrastive Networks: Self-Supervised Learning from Video

コメント