
1.集積カプセルオートエンコーダー(2/6)まとめ
・カプセルネットワークは、画像からパーツとパーツのポーズを推測する
・次にパーツとポーズを使用してオブジェクトについて推論する事が出来る
・カプセルネットワークの手法は人間の知覚と似ている部分がある
2.カプセルと人間の知覚の類似性
以下、akosiorek.github.ioより「Stacked Capsule Autoencoders」の意訳です。元記事の投稿は2019年6月23日、Adam Kosiorekさんによる投稿です。
カプセルは等価性を持つオブジェクト特徴表現を学習します
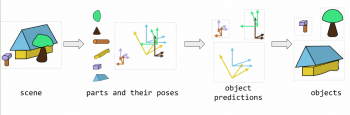
図2:カプセルネットワークは、画像からパーツとパーツのポーズを推測します。次にパーツとポーズを使用してオブジェクトについて推論することによって機能します。
各アフィン変換に対応するモデルを構築する代わりに、風景内には多くの複雑なオブジェクトが含まれていることが多いという事実に頼ることができます。オブジェクトは複雑ではあっても、より単純なパーツから構成されています。
定義上、パーツは完全なオブジェクトよりも外観や形状があまり変化しないため、生画像の画素から習得するほうが簡単です。
図2に示したように、パーツがどのように集まって様々なオブジェクトを形成しているかを学習する事ができれば、オブジェクトはパーツとそのポーズから認識できます。
ここで注意しなければならないのは、パーツ検出器を学習させる必要があり、パーツの姿勢(移動、回転、拡大縮小)も予測する必要があるということです。私達は、同様の機能を持つエンドツーエンドのオブジェクト検出器を学習させるよりもはるかに簡単なはずであるという仮説を立てました。
風景内に存在する任意の概念の姿勢は、観察者の位置(またはむしろ選択された座標系)と共に変化します。逆に言えば、パーツの姿勢を正しく識別することができる検出器は視点の変化の影響を受けません。つまり、「視点等価性を持つパーツの特徴表現」を生成しています。
オブジェクトとパーツの関係は特定の視点に依存しないので、それらは「視点不変性」を持ちます。2つのプロパティを組み合わせると、「視点等価性を持つオブジェクトの特徴表現」になります。
上記の問題は、パーツとオブジェクトを対応させる推論プロセスにあります。すなわち、発見したパーツを使用してオブジェクトを推論するためには、1つのオブジェクトに属するように全てのパーツを割り当てねばならず、これが非常に困難であるということです。
以前のバージョンのカプセルネットワークでは、オブジェクトへのパーツの割り当てを繰り返して改良していく事でこれを解決しました(ルーティングとも呼ばれています)。これは、計算とメモリの両面で非効率的であることが証明され、より大きな画像に規模を拡大する事は不可能になりました。 (以前のバージョンのカプセルネットワークについては「Understanding Hinton’s Capsule Networks. Part I: Intuition」を参照してください)
任意のニューラルネットはカプセルのような特徴表現を学ぶことができるのでしょうか?
オリジナルのカプセルネットワークは特定の構造を持つフィードフォワードニューラルネットワークの一種であり、分類(classification)のために訓練されています。
ちなみに、私たちは、分類が推論(inference)に対応していることを知っています。それは生成の逆のプロセスであり、それ自体はより困難です。これを理解するためには、ベイズの法則について考えてみてください。事後確率がしばしば事前確率や尤度よりはるかに複雑な理由です。
その代わりに、カプセルによって導入された原則を使用して生成モデル(デコーダー)および対応する推論ネットワーク(エンコーダー)を構築できます。
生成モデルは簡単です。任意のオブジェクトに任意の数のパーツを生成させることができるので、推論時に遭遇する制約を処理する必要がないためです。
それから複雑な推論ネットワークはあなたの好みのニューラルネットワークに任せる事ができます、そしてそれは適切な潜在的特徴表現を学びます。
デコーダはカプセルのメカニズムを採用しているので、設計上、視点等価性を持ちます。その結果、エンコーダは、少なくとも近似的には視点等価性を持つ特徴表現を学習する必要があります。
潜在的に不利な点は、潜在コードが(オブジェクト座標を明示的にエンコードするという意味で)視点等価性である可能性があるとしても、エンコーダ自体は視点等価性を持つ必要がないと言う事です。
これは、モデルがそれまでとはまったく異なる視点からオブジェクトを見ている場合、そのオブジェクトを認識できない可能性があることを意味します。
興味深いことに、これは人間の知覚と一致しているように思われます。最近Geoff HintonがTuring Awardの講演で実演したように、彼はこれを説明するために思考実験を行っています。あなたが興味を持っているなら、あなたは以下のビデオの36:08~を見ることができます。
以下は、ビデオの実演を簡略化したものです。以下の図3を参照してください。正方形を想像し、それを45度傾けて見て、もう一度見てください。
四角形が見えますか? それともこの形状はひし形に似ていますか?
人間は自分が見るオブジェクトに座標軸を課す傾向があります。座標軸はオブジェクトを認識する際の特徴の1つです。座標軸が通常のものと非常に異なる場合、正しい形状を認識する事が困難になる可能性があります。

図3:これは四角形でしょうか?ひし形でしょうか?
3.集積カプセルオートエンコーダー(2/6)関連リンク
1)akosiorek.github.io
Stacked Capsule Autoencoders
2)openreview.net
Matrix capsules with EM routing
3)arxiv.org
Group Equivariant Convolutional Networks
Spatial Transformer Networks
4)medium.com
Understanding Hinton’s Capsule Networks. Part I: Intuition.

コメント