
1.Off-Policy Classification:強化学習モデルを選別する新手法(2/2)まとめ
・OPCはSim-to-Realテクニックによって訓練されたモデルの評価に対しても有効であった
・OPCのスコアと現実世界のタスクの成功率の相関は従来手法より高かった
・今後の研究はよりノイズが混入する状況や「ほぼ成功した」等の部分的な評価を考慮する手法が考えられる
2.Off-Policy Classificationの性能評価
以下、ai.googleblog.comより「Off-Policy Classification – A New Reinforcement Learning Model Selection Method」の意訳です。元記事は2019年6月19日、Alex Irpanさんによる投稿です。
Sim-to-Realのためのポリシー外評価
ロボット工学では、シミュレーションデータと転移学習テクニックを利用することで、ロボットにスキルを習得させる事の複雑さを軽減することが一般的です。これは非常に便利ですが、現実世界で活躍するロボットのためにこれらのSim-to-Realテクニックを調整することは簡単な事ではありません。
ポリシー外強化学習と同様に、トレーニング時に実際のロボットは使用されません。シミュレーションでモデルがトレーニングされるためですが、しかし、そのポリシーの評価には実際のロボットを使用する必要があります。
ここで、ポリシー外評価が再び助けになる可能性があります。シミュレーションでしか訓練されていないポリシーを、過去の実世界のデータを使用して評価し、実際のロボットへ転送して試すべきか性能を測定できます。
私達は、完全ポリシー外強化学習とSim-to-Realの両方でOPCを調査しました。

シミュレートされた経験が実際の経験とどのように異なる可能性があるかの例。ここで、シミュレートされた画像(左図)は、実際の画像(右図)よりも視覚的な複雑さがはるかに少なくなっています。
OPCの性能検証結果
最初に、私達はロボットによる物体拾い上げ作業のシミュレーション環境をセッティングしました。そこでいくつかのモデルを訓練し、評価し、ポリシー外評価をベンチマークする事ができました。これらのモデルは、完全ポリシー外強化学習でトレーニングされ、次にポリシー外評価で評価されました。
私達のロボティックタスクでは、SoftOPCと呼ばれるOPCの変形が最終的な成功率を最も良く予測出来ていました。
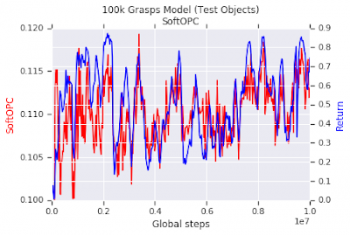
ロボットによる物体拾い上げ作業の実験
赤い曲線は、過去データを使って評価した無次元SoftOPCスコアです。青い曲線はシミュレーションの成功率です。過去データから評価したSoftOPCは、シミュレータ内でのモデルの拾い上げ成功率とよく相関しています。
シミュレーションで成功した後、私たちは現実世界のタスクでSoftOPCを試しました。ここではシミュレーションと現実世界の間のギャップに対してさまざまなレベルの頑強さを持つ15のモデルを使っています。
これらのモデルのうち、7つは純粋にシミュレーション環境で訓練され、残りはシミュレーション環境と実世界のデータの組み合わせで訓練されました。
各モデルについて、ポリシー外の実世界データでSoftOPCを評価し、次に実世界で拾い上げタスクを試行して成功率を計測し、SoftOPCがそのモデルのパフォーマンスをどの程度予測できているかを確認しました。
私達はSoftOPCが現実世界の拾い上げタスク成功率と相関するスコアを生成し、過去の実際の経験を使ってsim-to-real技術をランク付け可能である事を発見しました。

3つの異なるsim-to-realメソッドに対するSoftOPCスコアと現実世界でのパフォーマンス。比較対象となるベースラインシミュレーション、Dynamics randomizationを使ったシミュレーション、RCAN(Randomized-to-Canonical Adaptation Networks)で訓練されたモデル。
3つのモデルすべてが実データなしでトレーニングされ、次に実データの検証セットでポリシー外評価されました。SoftOPCスコアの順序は、実際の拾い上げ成功率の順序と一致しています。
以下は、全15モデルの結果の散布図です。各ポイントは、各モデルのポリシー外評価のスコアと実際の世界での拾い上げの成功を表します。
私達は、2つの異なるスコア付け関数を使って、最終的な拾い上げの成功率に対する相関を比較しました。SoftOPCは現実世界の拾い上げ成功率と完全には相関しません。しかし、そのスコアは時間的差分(temporal-difference error:標準的なQラーニングの損失)のようなベースラインアプローチよりもはるかに信頼性があります。
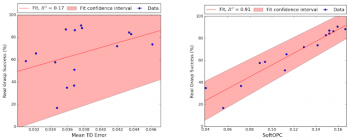
私達の評価実験の結果。左側はベースラインモデルのtemporal-difference errorです。右側は、私達が提案した方法の1つ、SoftOPCです。網掛けの部分は95%信頼区間です。SoftOPCを使用すると相関が大幅に向上します。
今後の研究
今後の研究の1つの有望な方向性は、今回設定した仮定を緩める事が出来るかです。例えば、よりダイナミクスにノイズが混入する状況での予測、または「ほぼ成功した」と言う部分的な評価を活用する手法などが考えられます。
しかしながら、私たちが今回設定した仮定があったままでも、今回の研究結果は多くの実世界のRL問題に適用するのに十分有望であると私たちは考えています。
謝辞
この研究は、Alex Irpan、Kanishka Rao、Konstantinos Bousmalis、Chris Harris、Julian IbarzおよびSergey Levineによって行われました。貴重な議論してくれたRazvan Pascanu、Dale Schuurmans、George Tucker、Paul Wohlhartに感謝します。 論文のプレプリントはarXivにあります。
3.Off-Policy Classification:強化学習モデルを選別する新手法(2/2)関連リンク
1)ai.googleblog.com
Off-Policy Classification – A New Reinforcement Learning Model Selection Method
2)arxiv.org
Off-Policy Evaluation via Off-Policy Classification
3)openai.com
Generalizing from Simulation


コメント