
1.Federated Reconstruction:部分的に端末内で連合学習を行い連合学習の規模を拡大(1/2)まとめ
・連合学習はユーザーがクラウドに生データを送ることなくモデルを学習することが可能
・各ユーザーで傾向が異なっていても全ユーザーに対応する単一のグローバルモデルとなる
・一部のモデルパラメータをサーバに集約しない部分的端末内連合学習でこれを解決した
2.部分的端末内連合学習とは?
以下、ai.googleblog.comより「A Scalable Approach for Partially Local Federated Learning」の意訳です。元記事の投稿は2021年12月16日、Karan Singhalさんによる投稿です。
連合学習では、多数の端末から集めた匿名化されたデータで一つの大きなモデルを学習させる事が出来ますが、これでは個々のユーザの嗜好が反映できないので、一部分だけローカル環境で(つまり、端末の内部で)訓練する事でこの問題を解決できました!、という事なので、部分的端末内連合学習(Partially Local Federated Learning)というかなりの意訳を当てましたが、とても悩みました。
部分的端末内連合学習をするとユーザによってかなり好みが異なる絵文字なども適切に推薦できるようになりますよって事から選んだアイキャッチ画像のクレジットはPhoto by Kelvin Yan on Unsplash
連合学習(Federated learning)は、ユーザーが中央サーバーに生データを送ることなくモデルを学習することを可能にします。その結果、プライバシーに影響する敏感なデータの収集を避けることができます。
この学習は多くの場合、各ユーザーデータの傾向が異なっていても、全ユーザーに対応する単一のグローバルモデルを学習することによって行われます。
例えば、モバイルキーボードアプリケーションのユーザーは、次の単語を提案するモデルを学習するために協力し合う事ができるかもしれませんが、提案を受け入れるかどうかの嗜好は異なります。このような嗜好の違いは、単一グローバルモデルを各ユーザー用に個別化するアルゴリズムの動機付けとなります。
しかし、プライバシーを考慮すると、完全にグローバルなモデルを学習することができない場合もあります。推薦システムのために使われる行列分解モデル(matrix factorization models)のような、ユーザー固有のembeddingsを持つモデルを考えてみましょう。
完全にグローバルな連合モデルを学習するためには、ユーザーのembeddingsの更新を中央サーバーに送る必要があり、embeddingsにエンコードされたプライベートな嗜好が明らかになってしまう可能性があります。
ユーザー固有のembeddingsを行わないモデルであっても、いくつかのパラメータをユーザーの端末内に置くことで、サーバーとクライアント間の通信を減らし、各ユーザーのプライバシーに対して責任を持ちながら、これらのパラメータを個人向けに設定することができます。
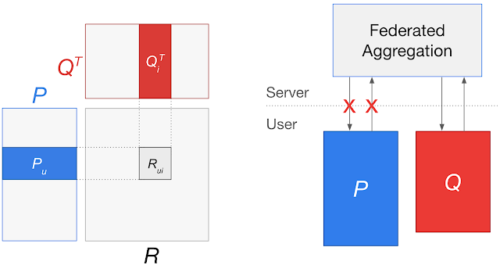
左図:ユーザ行列Pとアイテム行列Qを持つ行列分解モデル
あるユーザuに対するユーザembeddings(Pu)とアイテムiに対するアイテムembeddings(Qi)を学習し、そのアイテムに対するユーザの評価(Rui)を予測します。
右図:グローバルなモデルを学習するために連合学習アプローチを適用すると、Puの更新を中央サーバに送信する必要があり、個々のユーザの好みが漏れる可能性があります。
NeurIPS 2021で発表した「Federated Reconstruction: Partially Local Federated Learning」では、一部のモデルパラメータをサーバに集約しない、規模を拡大可能な部分的端末内連合学習(partially local federated learning)を可能にするアプローチを紹介しています。
このアプローチでは、各ユーザーデバイス内にユーザーembeddingsを保持しながら行列分解を使用する推薦モデルを学習します。また、他のモデルについては、モデルの一部を各ユーザに完全に対応するように学習させ、これらのパラメータを中央サーバーに送信する事を回避するアプローチです。
私たちは、部分的局所連合学習をGboardに導入することに成功し、何億人ものキーボードユーザに対してより良い推薦を行うことができるようになりました。また、Federated Reconstructionの使い方を実演するTensorFlow Federatedチュートリアルを公開します。
Federated Reconstruction
従来の局所連合学習は、ステートフル(stateful)なアルゴリズムを使用しており、各ユーザが学習の進捗を保持する必要がありました。
具体的には、これらのアプローチでは、ユーザーのデバイスが連合学習の各学習回に渡ってローカルパラメータを保存を保存する必要がありました。
しかし、これらのアルゴリズムは、大規模な連合学習環境において劣化する傾向があります。大多数のユーザーは学習に参加せず、参加したユーザーも一度しか参加しない可能性が高いため、保存した状態が利用可能になることはほとんどなく、古くなってしまう可能性があるのです。
また、参加しないすべてのユーザは学習済みのローカルパラメータを持たないままとなるので、実用的な応用ができません。
Federated Reconstructionはステートレス(stateless)であり、状態を保存せずとも、いつでも再構成できるので、ユーザーデバイスにローカルパラメータを保存する必要性を回避します。
ユーザが連合学習に参加する場合、グローバルに集約するモデルのパラメータを更新する前に、グローバルパラメータを凍結した状態でローカルデータに対して勾配降下法を用いてランダムに初期化し、ローカルパラメータを学習させます。
その後、ローカルパラメータを凍結したまま、グローバルパラメータの更新を計算することができます。Federated Reconstructionのトレーニングの一例を以下に示します。
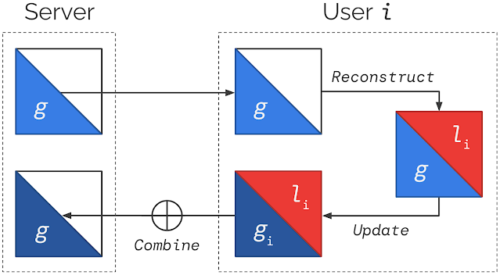
モデルは、グローバルパラメータとローカルパラメータに分割されます。
Federated Reconstructionトレーニングの各学習回では、以下のようになります。
(1) サーバは現在のグローバルパラメータgを各ユーザiに送信する。
(2) 各ユーザiはgを凍結し、ローカルパラメータliを再構築する。
(3) 各ユーザiはliを凍結し、gを更新してgiを生成する。
(4) 各ユーザのgiを平均化し,次回のグローバルパラメータを生成する。
(2)と(3)は一般にローカルデータの異なる部分を使用します。
3.Federated Reconstruction:部分的に端末内で連合学習を行い連合学習の規模を拡大(1/2)関連リンク
1)ai.googleblog.com
A Scalable Approach for Partially Local Federated Learning
2)arxiv.org
Federated Reconstruction: Partially Local Federated Learning
3)www.tensorflow.org
Module: tff.learning.reconstruction

