
1.CALM:簡単な語順には手間をかけないようにして人工知能による文章生成を高速化(1/2)まとめ
・文章生成タスクは直前の単語に基づいて行われるため並列化が困難である
・幾つかの単語は他の単語より次の単語を予測することが簡単な事実に着目した
・CALMはより困難な予測に対してのみ選択的に計算資源を割り当てる新手法
2.CALMとは?
以下、ai.googleblog.comより「Accelerating Text Generation with Confident Adaptive Language Modeling (CALM)」の意訳です。元記事は2022年12月16日、Tal Schusterさんによる投稿です。
アイキャッチ画像はstable diffusion 2.1のDreamBooth拡張をstable diffusionのアウトペインティングで更にサイズ拡張した画像。ガンシップをコクピットで操縦する加速(Accelerating)な感じを出したかったのですが、ナウシカ先生が機体から身を乗り出す傾向を制御できず、更にアウトペインティングすると機体そのものも異世界召喚されてしまう傾向に苦戦しています。
言語モデル(LM:Language model)は、自然言語処理における最近の多くの革新の原動力です。
T5、LaMDA、GPT-3、PaLMなどのモデルは、さまざまな言語タスクで素晴らしい性能を実証しています。LMの性能向上には複数の要因がありますが、最近のいくつかの研究では、モデルのサイズを拡大することが、創発的な能力を明らかにするために重要であることが示唆されています。つまり、小さなモデルで解ける事象もありますが、解けない場合はモデルの規模を拡大する事で解けるようになる場合があると思われます。
最近の取り組みにより、大量のデータに対するLMの効率的な学習が可能になりましたが、モデルを学習させる事は実用上まだ時間がかかり、コストもかかる場合があります。
推論時にテキストを生成する場合、ほとんどの自己回帰型LMは、私達が話したり書いたりするのと同じように(単語の後に単語を)、つまり、前の単語に基づいてそれぞれの新しい単語を予測し、内容を出力します。LMはある単語の予測を完了してから次の単語の計算を開始する必要があるため、このプロセスは並列化できません。また、各単語の予測には数十億のパラメータが必要であり、膨大な計算が必要となります。
NeurIPS 2022で発表した「Confident Adaptive Language Modeling」では、推論時の効率化によりLMのテキスト生成を高速化する新しい方法を紹介しています。
「信頼性の高い適応的な言語モデリング(CALM:Confident Adaptive Language Modeling)」と名付けられた本手法は「幾つかの単語は他の単語より次の単語を予測することが簡単である」という直感を動機としています。文章を書くとき、特定の語順は簡単な事ですが、他の語順はより多くの労力を必要とするかもしれません。現在のLMは、すべての予測に同じ量の計算能力を割いています。しかし、CALMでは、計算能力を生成時の各タイムステップに動的に分散させます。より困難な予測に対してのみ選択的に計算資源を割り当てることで、CALMは出力品質を維持したままテキストを高速に生成します。
CALMは、可能な限り、特定の予測に対して計算を省略します。これを実証するために、一般的なエンコーダ・デコーダであるT5アーキテクチャを使用します。エンコーダは入力テキスト(例えば要約すべきニュース記事)を読み、テキストを密な特徴表現に変換します。次に、デコーダは要約を単語単位で予測して出力します。
エンコーダーとデコーダーの両方は長く連続するTransformerレイヤーを含みます。各層は多くの行列の乗算を伴うAttentionモジュールとfeedforwardモジュールを含みます。これらのレイヤーは最終的に次の単語を予測するために使用される隠れ特徴表現を徐々に修正します。
CALMはすべてのデコーダ層が完了するのを待つのではなく、ある中間層の後で、より早く次の単語を予測することを試みます。ある予測に任せる事にするか、あるいは予測を後のレイヤーまで延期するかを決定するために、私達はモデルの中間予測に対する信頼度を測定します。
予測値が変化しないとモデルが十分に確信したときのみ、残りの計算が省略されます。何が「十分な確信(confident enough)」なのかを定量化するために、全出力列に対して任意の品質保証を統計的に満たす閾値を較正します。
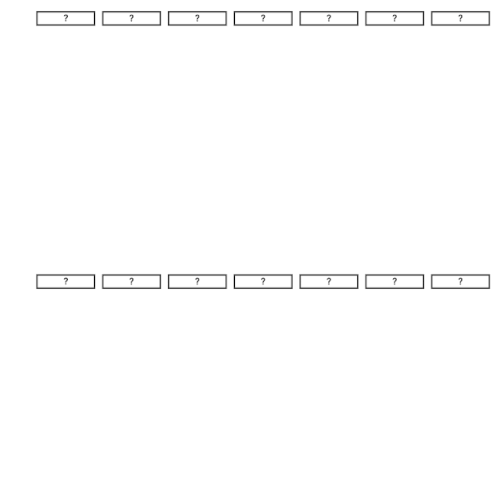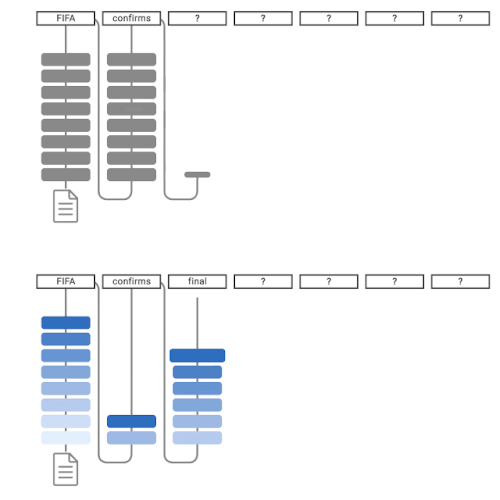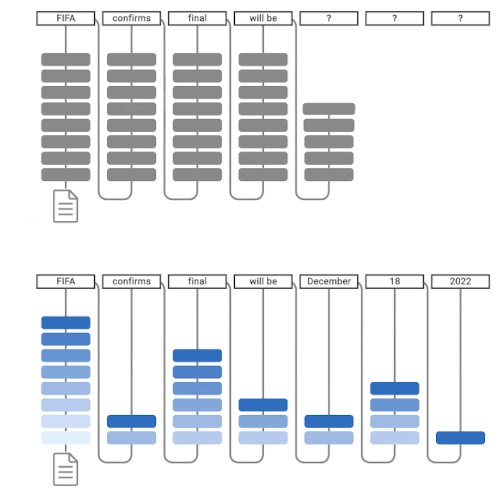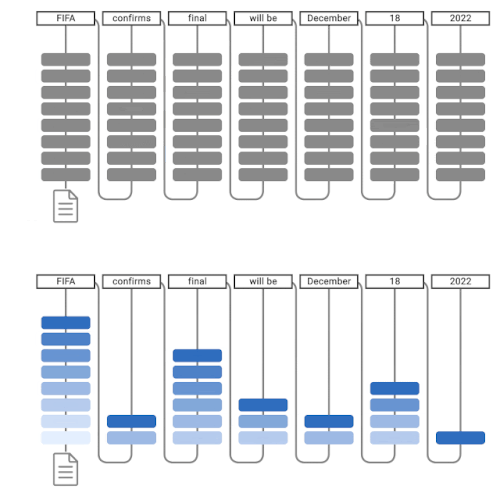
通常の言語モデルによるテキスト生成(上)、CALMによるテキスト生成(下)。CALMは早期予測を試みます。十分な自信がある場合(濃い青色)、予測をスキップして時間を節約します。
言語モデルによる早期終了
学習と推論に最小限の変更を加えるだけで言語モデルの早期終了(early exit)が可能になります。学習中、私達はモデルが中間レイヤーで意味のある特徴表現を生成することを推奨します。
学習時の損失関数は、最上位レイヤーのみを用いて予測するのではなく、全てのレイヤーの予測値を加重平均し、最上位レイヤーに高い重み付けをしています。この結果、中間レイヤーの予測値が大幅に改善され、かつモデル全体の性能が維持されることが実験により確認されました。
モデルのバリエーションの一つでは、私達は局所的な中間レイヤーの予測が最上位レイヤーと一致するかどうかを分類するために訓練された小さな早期離脱分類器を含めます。この分類器は、モデルの残りの部分を凍結させて、2番目のステップで早期に学習させます。
モデルの学習が完了したら、早期離脱を可能にする事が必要です。
まず、中間予測に対するモデルの信頼度を表す局所的な信頼度指標を定義します。
私達は3つの信頼性指標を検討しました。(以下の結果セクションで述べます)。
(1)ソフトマックス応答:ソフトマックス分布から最大予測確率を取り出す
(2)状態伝播:現在の隠れ特徴表現と前のレイヤーからの特徴表現間のコサイン距離
(3)早期終了分類器:特に局所整合性の予測のために学習した分類器の出力
私達は、ソフトマックス応答(softmax response)が統計的に強力であると同時に、シンプルで高速な計算が可能であることを見出しました。他の2つの選択肢は、浮動小数点演算(FLOPS)時に軽量です。
もう一つの課題は、各層のself-attentionが前の単語から得る隠れ状態に依存することです。もし、ある単語を予測して早期に終了した場合、これらの隠れ状態が欠落する可能性があります。そのため、最後に計算されたレイヤーの隠れ状態に戻るようにします。
最後に、早期に終了するための局所的な信頼度閾値を設定します。次の章では、良い閾値を見つけるための私達の制御したプロセスを説明します。最初のステップとして、私達は以下の有用な観察に基づいて、この無限の探索空間を単純化します。
「生成プロセスの開始時に行われるミスは、以降の出力のすべてに影響を与える事になるので、より有害です」
したがって、より高い(より保守的な)閾値で開始し、時間と共に徐々に減らしていきます。この減衰率を制御するために、ユーザー定義の温度感(temperature)で負の指数を使用します。これにより、性能と効率のトレードオフ(品質レベルごとに得られる高速化)をよりよく制御できることがわかります。
3.CALM:簡単な語順には手間をかけないようにして人工知能による文章生成を高速化(1/2)関連リンク
1)ai.googleblog.com
Accelerating Text Generation with Confident Adaptive Language Modeling (CALM)
2)arxiv.org
Confident Adaptive Language Modeling

