
1.Expert Choice:大規模なMoEモデルを偏らせずに学習させる工夫(1/2)まとめ
・MoEは巨大モデル内のFFレイヤーを複数の同じFFレイヤーに置き換える事
・MoEとスパース設計を組み合わせる事で効率的なデータ処理が可能になる
・Expert ChoiceはMoE設計のネットワークでデータの振り分けを工夫する処理
2.Expert Choiceとは?
以下、ai.googleblog.comより「Mixture-of-Experts with Expert Choice Routing」の意訳です。元記事の投稿は2022年11月16日、Yanqi Zhouさんによる投稿です。
MoE、すなわちMixture-of-Expertsとは何度か出てきているお話なのですが直訳すると「寄せ集められたエキスパート」です。巨大モデル内のフィードフォワードレイヤーを複数の同じフィードフォワードレイヤー(これをエキスパートと呼びます)で置き換える設計です。
MoEにすると何が嬉しいかというと、スパースな(まばらな)設計と組み合わせる事で、全データを全てのニューロンに与える必要がなくなり、特定のデータを特定のエキスパート群だけに与えて処理させる振り分けが出来るようになり、例えば視覚分類モデルであれば「車分類用のエキスパート群」や「動物分類用のエキスパート群」と言う効率化が出来るようになり、もっと言えば画像データと音声データなどの異種データを同時に扱えるマルチモーダルな単一巨大ネットワークの実現に近づくと言う利点があります。
MoEで難しいのは「どのデータをどの単位でどうやってどのエキスパートに割り当てるのか?」というルーティング、つまり振り分けの問題であって、過去には例えばタスク単位で割り当てるTaskMoEなども発表されていますが、上手に振り分けないと暇なエキスパートと容量オーバーしてしまうエキスパートが出来てしまう事があり、そこを上手に工夫したアルゴリズムが出来ました、と言うのが今回のお話です。
ちょっと私が誤解していて誤りを流布してしまっていたら申し訳ないのですが「MoE」と言えば、スパースと思っていましたが、密なMoEがあり得ると言う事が今回勉強になりました。特殊なケースではあると思いますが、ルーターの設定によっては全エキスパートにデータを流す処理もあり得るので、そういったケースではMoEであっても密なネットワークと言う事になると思います。
アイキャッチ画像はstable diffusionの1.5版の生成でルーティングを司る門番(GateKeeper)の役割を与えたところ、それっぽい体勢と表情をしてくれたトトロ
モデル容量、すなわちニューラルネットワークが情報を吸収する能力は、そのパラメータの数によって制限されます。その結果、モデルのパラメータをより効果的に増やす方法を見つけることが、ディープラーニング研究のトレンドになっています。
計算量を比例的に増やすことなく、モデル容量を飛躍的に増やす方法としてMixture-of-experts(MoE)が提案されています。
MoEは、入力データを振り分けて、ネットワークの一部を活性化させるようにする条件付き計算(conditional computation)の一種です。
ネットワークを疎らに活性化するスパースなMoE モデル(Switch Transformer、GLaM、V-MoE など)では、エキスパートの一部をトークンごと、あるいはサンプルごとに選択し、ネットワークにスパース性(sparsity、疎らな構成にする事)を持たせています。
このようなモデルは、複数の領域においてより優れたスケーリングと、継続学習(continual learning)の設定におけるより優れた保持能力を実証しています。(例:Expert Gate)
しかし、エキスパートへのルーティング戦略が不適切だと、特定のエキスパートの学習が不足し、エキスパートが過小または過大に専門化する可能性があります。
NeurIPS 2022で発表した「Mixture-of-Experts with Expert Choice Routing」では、エキスパートチョイス(EC:Expert Choice)と呼ばれる新しいMoEルーティングアルゴリズムを紹介します。
この新しいアプローチにより、トークンを各エキスパートに割り当てる際に異種性を許容しながら、MoEシステムにおいて最適な負荷分散を実現できることを議論します。
従来のMoEネットワークにおけるトークンベースのルーティングや他のルーティング手法と比較して、ECは非常に強力な学習効率と下流タスクスコアを実証しています。
本手法は、異種のデータを扱うエキスパート同士のとりまとめを可能にするものでGoogleの長期ビジョンであるPathwaysに含まれるMPMD(multi program, multi data)思想と共振しています。
MoEルーティングの概要
MoEは、複数のエキスパートをそれぞれサブネットワークとして採用し、各入力トークンに対して1人または数人のエキスパートだけを活性化させることで動作します。
各トークンを最適なエキスパートにルーティングするためには、ゲーティングネットワークを選択し、最適化する必要があります。トークンがどのようにエキスパートに割り当てられるかに応じて、MoEは疎または密なネットワークになり得えます。
疎なMoEは、各トークンをルーティングする際にエキスパートのサブセットのみを選択し、密なMoEと比較して計算コストを削減します。例えば、最近の研究では、k-meansクラスタリング、トークン-エキスパートの親和性を最大化する線形割り当て、またはハッシュ化によってスパースルーティングを実装しています。
Googleは最近、GLaMとV-MoEを発表しましたが、これらはいずれも上位kトークンルーティングを備えたスパースゲートMoEによって自然言語処理とコンピュータビジョンの技術水準を向上させ、アクティブなMoEレイヤーによってより優れたスパースな性能スケーリングを実証しています。
これらの先行研究の多くは、ルーティングアルゴリズムが各トークンに対して最適な1~2のエキスパートを選ぶ、トークン選択ルーティング戦略を用いています。
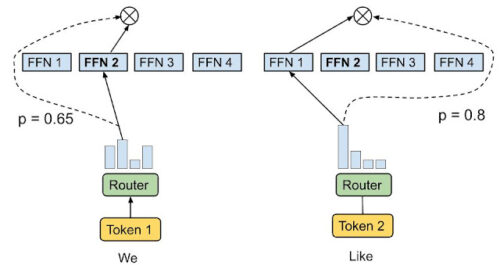
トークン選択ルーティング
ルーティングアルゴリズムは、各トークンに対して最も高い親和性スコア(affinity scores)を持つ上位1または上位2のエキスパートを選択します。親和性スコアはモデルパラメータと一緒に学習させることができます。
独立したトークン選択アプローチはしばしばエキスパートの負荷が不均衡になり、利用率が低くなります。これを緩和するために、以前のスパース性ゲートネットワークでは、単一のエキスパートにルーティングされるトークンが多すぎないように、正則化として追加の補助損失を導入しましたが、その効果は限定的でした。その結果、トークン選択ルーティングは、バッファオーバーフローが発生したときにトークンを落とさないように、かなりの余裕(計算容量の2x~8x)でエキスパート容量を過剰に割り当てる必要があります。
エキスパート選択ルーティング
上記の課題を解決するために、以下に示すエキスパート選択ルーティング方式を採用した異種データを扱えるヘテロジニアスなMoE(heterogeneous MoE)を提案します。トークンに上位kのエキスパートを選択させるのではなく、予め決められたバッファ容量を持つエキスパートを上位kトークンに割り当てます。
この方式は、負荷分散を均等にし、各トークンのエキスパート数を可変にすることで、トレーニング効率と下流タスク性能を大幅に向上させることができます。ECルーティングは、8B/64E(80億活性化パラメータ、64エキスパート)モデルにおいて、Switch Transformer、GShard、GLaMのtop-1およびtop-2ゲーティングと比較して、2倍以上、学習収束を速めることができます。
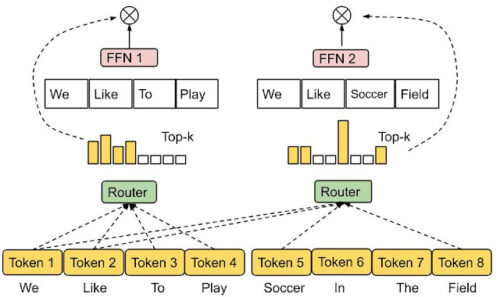
エキスパート選択ルーチング。
あらかじめ決められたバッファ容量を持つエキスパートには、上位kトークンが割り当てられ、均等な負荷分散が保証されます。各トークンは可変数のエキスパートによって受け取ることができます。
ECルーティングでは、エキスパート容量kを、入力シーケンスのバッチにおけるエキスパートあたりの平均トークンに容量係数を掛けたものとし、これにより各トークンが受け取ることのできるエキスパートの平均数を決定します。トークンとエキスパートの親和性を学習するために、本手法はトークンとエキスパートのスコア行列を生成し、ルーティングの決定に利用します。スコア行列は、入力シーケンスのバッチ中のあるトークンが、あるエキスパートにルーティングされる可能性を示します。
3.Expert Choice:大規模なMoEモデルを偏らせずに学習させる工夫(1/2)まとめ
1)ai.googleblog.com
Mixture-of-Experts with Expert Choice Routing
2)arxiv.org
Mixture-of-Experts with Expert Choice Routing

