
1.Table Tennis:俊敏な動きを研究するためにロボットと卓球をする(2/2)まとめ
・実データだけで学習する事が望ましい場合もあるが既存手法には問題があった
・GoalsEyeでは行動クローニング技術を組み合わせて徐々に継続的に学習させた
・非構造化データからの学習と自己教師付き練習の組み合わで目標を達成できた
2.GoalsEyeとは?
以下、ai.googleblog.comより「Table Tennis: A Research Platform for Agile Robotics」の意訳です。元記事は2022年10月18日、Avi SinghさんとLaura Graesserさんによる投稿です。
アイキャッチ画像はstable diffusionの生成で卓球をするトトロ
GoalsEye:物理ロボットで正確に返球する学習
i-S2Rではシミュレーションと実世界の両方のデータ学習を重視しましたが、実世界のデータだけで学習することが望ましい場合もあります。その場合はシミュレーションと実世界のギャップを埋める必要はありません。
模倣学習(IL:Imitation Learning)は実世界で学習するためのシンプルで安定したアプローチですが、実演を見る必要があり、教師のパフォーマンスを超えることはできません。
高速な環境で正確な目標達成を行う専門家の人間の実演を集めることは困難であり、時には(人間の動作の精度に限界があるため)不可能です。
強化学習(RL:Reinforcement Learning)はこのような高速で高精度なタスクに適していますが、特に開始時に困難な探索問題(exploration problem)に直面し、非常にサンプル効率が悪くなることがあります。
GoalsEyeでは、最近の行動クローニング(behavior cloning)技術を組み合わせ、小さく緩い構造を持つ非ターゲットデータセットから出発して、正確なターゲットポリシーを学習するアプローチを実証しています。
ここでは、精度を重視した異なる卓球タスクを考えます。例えば「左隅に打つ」「右側のネットすれすでにボールを着地させる」など、テーブル上の任意のゴール位置にロボットがボールを返すようにしたいです。(下の左の動画を参照)。
さらに、シミュレーションを行わず、実世界の卓球環境に直接適用できる方法を探しました。私たちは、既存の2つの模倣学習技術、LFP(Learning from Play)とGCSL(Goal-Conditioned Supervised Learning)を統合することで、この設定に規模を拡大できることを発見しました。LFPは、卓球台上の特定のゴールにボールを返すというタスクにおいて、素人の人間と同程度の精度を持つ物理ロボットの方針を訓練するのに十分な安全性とサンプル効率を有しています。


直径20cmのゴールを狙うGoalsEye(左)
同じゴールを目指す人間プレイヤー(右)
成功のための必須条件は
(1)ロボットがボールを打つという、最小限の、しかしゴールに直接結びつかない「ブートストラップ」データセットにより、最初の困難な探索問題を克服する事
(2)後付けでラベル付けしたゴール条件付き行動クローニング(GCBC:Goal Conditioned Behavioral Cloning)により、データセット内の任意のゴールに到達するゴール指向のポリシーを学習する事
(3)反復的自己教師付きゴール到達法(Iterative self-supervised goal reaching)。エージェントが、ランダムなゴールを設定し、現在のポリシーを使ってゴールを達成しようとすることで、継続的に改善する。全ての試みは再ラベル化され、継続的に拡大する学習セットに追加される。この自己練習は、ロボットが目標を設定し到達を試みることによって学習データを拡張するものであり、繰り返し行われる。
GoalsEyeの手法
鍵となるのは実践を通したデモンストレーションと自己練習
総合的な技術力が重要です。ポリシーの目的は、飛んでくるさまざまなボールを相手側の任意の位置に返すことです。最初の2,480回のデモンストレーションで訓練されたポリシーは、9%の確率でゴールから30cm以内にしか到達しません。
しかし、13,500回ほど練習した結果、ゴール到達率は43%に向上しました(下図右)。
この向上は、以下の動画ではっきりと確認することができます。しかし、自己練習(self-practice)しかしないポリシーの場合、この設定では学習は完全に失敗します。興味深いことに、デモンストレーションの回数を増やすと、その後の自己練習の効率は、逓減するものの、改善されます。このことは、自己練習と比較してデモデータを収集する時間とコストの相対的な違いにより、デモデータと自己練習を代替できることを示しています。
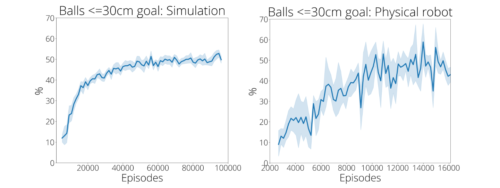
自己練習で精度が大幅に向上
左:シミュレータ訓練の様子
右:実際のロボットの訓練。デモデータセットには、シミュレーションと実世界の両方で、約2500のエピソードが含まれています。

自己練習の効果を可視化
左:最初の2,480回のデモでトレーニングされたポリシー
右:13,500回の自己練習を追加した後の方針ポリシー
GoalsEyeの詳細については、論文および私達のウェブサイトをご覧ください。
まとめと今後の課題
私達は、ロボット卓球の研究プラットフォームを用いた2つの補完的なプロジェクトを発表しました
i-S2Rは人間との対戦が可能なRLを学習し、GoalsEyeは実世界の非構造化データからの学習と自己教師付き練習を組み合わせることで、精密で動的な環境における目標条件付きポリシーの学習に有効であることを実証しました。
卓球のプラットフォームで追求すべき興味深い研究の1つの方向性は、人間の参加者のスキルレベルに応じてプレイスタイルを適応させ、挑戦的でエキサイティングな状況を維持できるロボット「コーチ」を構築することです。
謝辞
共著者のSaminda Abeyruwan, Alex Bewley, Krzysztof Choromanski, David B. D’Ambrosio, Tianli Ding, Deepali Jain, Corey Lynch, Pannag R. Sanketi, Pierre Sermanet および Anish Shankarに感謝します。また、各論文の謝辞に記載されているロボット工学チームの多くのメンバーの支援に感謝します。
3.Table Tennis:俊敏な動きを研究するためにロボットと卓球をする(2/2)関連リンク
1)ai.googleblog.com
Table Tennis: A Research Platform for Agile Robotics
2)arxiv.org
i-Sim2Real: Reinforcement Learning of Robotic Policies in Tight Human-Robot Interaction Loops
GoalsEye: Learning High Speed Precision Table Tennis on a Physical Robot
3)sites.google.com
i-Sim2Real: Reinforcement Learning of Robotic Policies in Tight Human-Robot Interaction Loops
GoalsEye: Learning High Speed Precision Table Tennis on a Physical Robot

