
1.TensorStore:ペタサイズの高次元データを柔軟に効率的に処理する(2/2)まとめ
・Apache BeamやDaskなどの並列コンピューティングライブラリと互換性を持つ
・大規模言語モデルではT5XやPathwaysなどのフレームワークと統合されている
・脳の視覚化であるコネクトミクスなどの超大規模データにも使用されている
2.TensorStoreの使用例
以下、ai.googleblog.comより「TensorStore for High-Performance, Scalable Array Storage」の意訳です。
元記事の投稿は2022年9月22日、Jeremy Maitin-ShepardさんとLaramie Leavittさんによる投稿です。
アイキャッチ画像はstable diffusionの生成
多数のマシンが同じデータセットにアクセスする際の並列処理の安全性は、楽観的並行性制御(optimistic concurrency)によって達成されており、パフォーマンスに大きな影響を与えることなく、多様なストレージ層(ローカルファイルシステムだけでなく、GCSなどのクラウドストレージプラットフォームを含む)との互換性を維持します。また、TensorStoreは、単一のランタイム内で実行される個々の処理に対して強力なACID保証を提供します。
また、TensorStoreを用いた分散コンピューティングを既存の多くのデータ処理ワークフローと互換性を持たせるために、Apache Beam(元サイトにコード例あり)やDask(元サイトにコード例あり)などの並列コンピューティングライブラリとTensorStoreの統合を図りました。
使用例 言語モデル
機械学習(ML:Machine Learning)における最近のエキサイティングな開発は、PaLMのようなより高度な言語モデルの出現です。これらのニューラルネットワークは数千億のパラメータを持ち、自然言語の理解や生成において驚くべき能力を発揮します。
また、これらのモデルは、計算機インフラの限界に挑戦しています。特に、PaLMのような言語モデルの学習には、数千のTPUが並列に動作する必要があります。
この学習プロセスで発生する課題のひとつが、モデルのパラメーターを効率的に読み書きすることです。学習は多くのマシンに分散して行われますが、学習プロセス全体を減速させることなく、パラメータを永久保存システム上の1つの対象(つまり、チェックポイント)に定期的に保存することが必要です。
また、個々のトレーニングジョブは、モデルパラメータのセット全体(数百ギガバイトにもなる)を読み込むのに必要なオーバーヘッドを避けるために、関係する特定のパラメータセットだけを読み込むことができなければなりません。
TensorStoreは、すでにこれらの課題に対処するために使用されています。JAXで学習させた大規模「multipod」なモデルのチェックポイント管理に適用され(元サイトにコード例あり)、T5X(元サイトにコード例あり)やPathwaysなどのフレームワークと統合されています。
モデルの並列性を利用して、1テラバイト以上のメモリを占めることもあるパラメータ一式を数百のTPUに分割しています。チェックポイントはTensorStoreを使用してzarr形式で保存され、各TPUのパーティションが独立して並行して読み書きできるようにチャンク構造が選択されています。

チェックポイントを保存する際、各モデルパラメータは、TensorStoreを使用して、TPU上のパラメータを分割するために使用されるグリッドをさらに細分化したチャンクグリッドを用いてzarr形式で書き込まれます。ホストマシンは、そのホストに接続されたTPUに割り当てられた各パーティションのzarrチャンクを並列に書き込みます。TensorStoreの非同期APIを使用すると、データが永続ストレージに書き込まれたままでも学習が進みます。チェックポイントから再開する際、各ホストはそのホストに割り当てられたパーティションを構成するチャンクのみを読み取ります。
使用例:三次元の脳マッピング
脳を視覚化するコネクトミクスの分野では、動物やヒトの脳の配線を、個々のシナプス結合の詳細レベルでマッピングすることを目指しています。
そのためには、ミリメートル以上の視野で脳を超高解像度(ナノメートル)でイメージングする必要があり、ペタバイト級のデータセットが生成されます。
将来的には、マウスや霊長類の脳を丸ごとマッピングすることで、このデータセットはエクサバイトにまで拡大する可能性があります。しかし、現在のデータセットでさえ、保存、操作、処理に関する大きな課題があります。特に、脳のサンプル1つでさえ、各次元で数十万画素の座標系(画素空間)で数百万ギガバイトを必要とする場合があります。
私達は、TensorStoreを利用して、大規模コネクトミクスデータセットに関連する計算上の課題を解決してきました。具体的には、TensorStoreは、Google Cloud Storageをオブジェクトストレージシステムの基盤として、最大かつ最も広くアクセスされているコネクトミクスデータセットのいくつかを管理してきました。
例えば、ヒトの脳組織の3dナノメートル解像度の画像であるヒト皮質「h01」データセットに適用されています。生データは1.4ペタバイト(約50万×35万×5千ピクセル)で、さらに同じ座標系にある3Dセグメンテーションや注釈などの付加コンテンツと関連付けられています。生データは128x128x16画素に分割され、「Neuroglancer precomputed」フォーマットで保存されます。これはウェブベースのインタラクティブな表示に最適化されており、TensorStoreから容易に操作することが可能です。
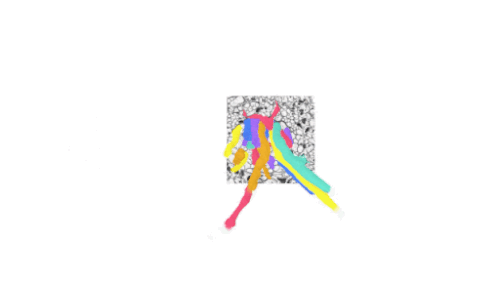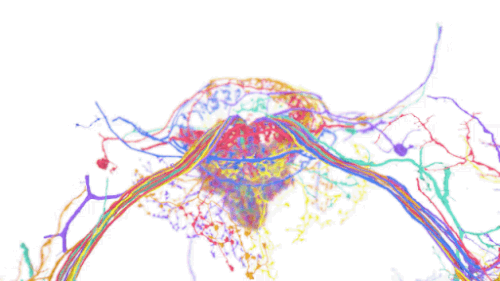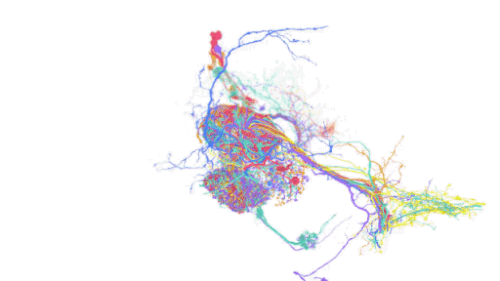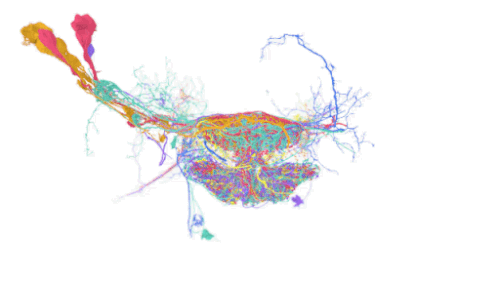
はじめ方
TensorStore Python API を使い始めるには、tensorstore PyPI パッケージをインストールします。
pip install tensorstore
使い方の詳細については、チュートリアルとAPIドキュメントを参照ください。その他のインストール方法やC++ APIの使用方法については、インストール方法を参照してください。
謝辞
Google ResearchのTim Blakely, Viren Jain, Yash Katariya, Jan-Matthis Luckmann, Michał Januszewski, Peter Li, Adam Roberts, Brain Williams, and Hector Yeeと、より広い科学コミュニティから設計、初期テスト、デバッグに関する貴重なフィードバックを頂いたDavis Bennet, Stuart Berg, Eric Perlman, Stephen Plaza, Juan Nunez-Iglesiasに感謝します。
3.TensorStore:ペタサイズの高次元データを柔軟に効率的に処理する(2/2)関連リンク
1)ai.googleblog.com
TensorStore for High-Performance, Scalable Array Storage
2)github.com
google / tensorstore

