
1.スマホ写真で学習した人工知能はStable Diffusionの画像をどう評価するか?まとめ
・写真に写っている人とイラストに描かれている人は人工知能にとって異なる
・スマホ撮影写真の評価を行う人工知能にstable diffusionのイラストを与えた
・評価が低かったイラストは撮影失敗写真に通じる部分があるイラストであった
2.最先端の人工知能に敢えてお門違いの事をやってもらう
人間であれば「写真内に写っている人」も「イラスト内に描かれている人」も特に意識せずに同様に「人」と認識する事ができますが、人工知能にとっては写真とイラストは領域(ドメイン)が異なります。
例えば、現実世界の写真を使って顔認識を学習した人工知能にイラストを与えてイラスト内の顔を認識させようとすると精度はかなり落ちます。
とは言え、最近はマルチドメイン学習といって、両方の領域を同時に扱えるようにしようとするMPNASのような試みなども増えて起きており、全く使えないわけではありません。
今回の投稿は最先端の美観評価モデル(ただし、学習元データがスマホ写真)でStable Diffusionの生成した画像を評価して貰ったらどんな感じになるのだろう?との疑問を確かめたものです。
スマホ写真の美観というと、撮影失敗のパターン、例えば、手振れ、ぼやけ、被写体が誤ってフレーム内に収まってない、などが考えられます。
これらはStable Diffusionの生成した画像内で足が増えたとか、顔がゆがんだとか、わけのわからないものが映っている等に通じるものがありそうなので全く使えないわけではないかもな、という思いでした。
また、上記を想定していたため「一部分が歪んだ画像データセットでトレーニングされた学習済モデル」でも評価してみました。
評価した画像は「Stable Diffusionは写真とイラストのどちらが得意なのか?」で作った18000枚の画像です。
結論を書くと、低評価画像についてはまさに想定通りで撮影失敗のパターンに類似した画像が選択されましたが、高評価画像についてはよくわかりませんでした。
それでは、スタートです!
paq2piqで学習したMUSIQが高評価した上位画像
paq2piqは一部分が歪んだ現実世界の画像40,000枚とそれを断片化したデータセットです。
| 1位 | 2位 | 3位 | 4位 | 5位 |
 |
 |
 |
 |
 |
1位はRealisticスタイルで写真と見間違える程の精緻さなので上位入賞は納得ですが、2位-5位がまさかのジブリスタイル独占!そしてう~ん?これ上位入賞?と疑問に感じるレベルの絵も含まれています。
SPAQで学習したMUSIQが高評価した上位画像
SPAQは66台のスマートフォンで撮影された 11,125 枚の写真からなるデータセットです。
| 1位 | 2位 | 3位 | 4位 | 5位 |
 |
 |
 |
 |
 |
まさかのジブリスタイル上位独占!
RealisticスタイルやArtStationスタイルの画像には歪みが入ってきたり、敢えてぼやかす画風の絵などが混ざる時があるので、それらが撮影失敗写真に類似性があるのかな、と想像しています。
ジブリスタイルは人物がやや崩壊していても背景部分は明瞭さが一貫しているので、そのあたりが評価されているように感じます。
下位画像
両データセットでほぼ同様な感じで撮影失敗画像に雰囲気が似たものでした。ビリの真っ黒画像は職場閲覧注意(NSFW:Not Safe For Work)警告が出て黒一色の画像が出力された際のもので同時最下位多数です。やはりぼやけた感じの画像が低評価になっていますね。
| 後ろから1位 | 後ろから2位 | 後ろから3位 | 後ろから4位 | 後ろから5位 |
 |
 |
 |
 |
 |
スタイル別評価分布
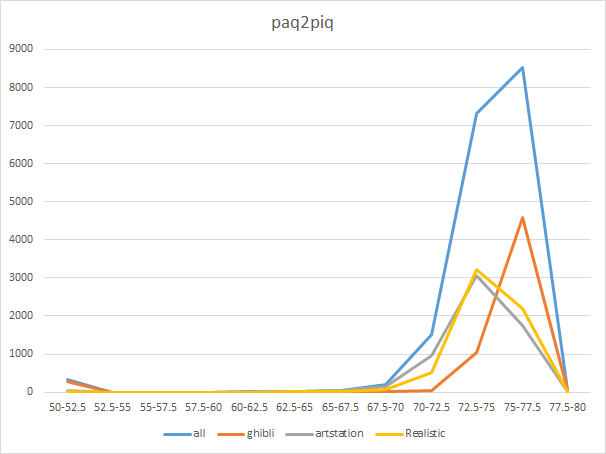
全体的に高評価です。そのため、わかりやすくするためにpaq2piqでは横軸の倍率は変えてあるのですが、微妙な差ではあるのですが、やはりジブリスタイルが右に重心がよっており、相対的に高評価が多いです。
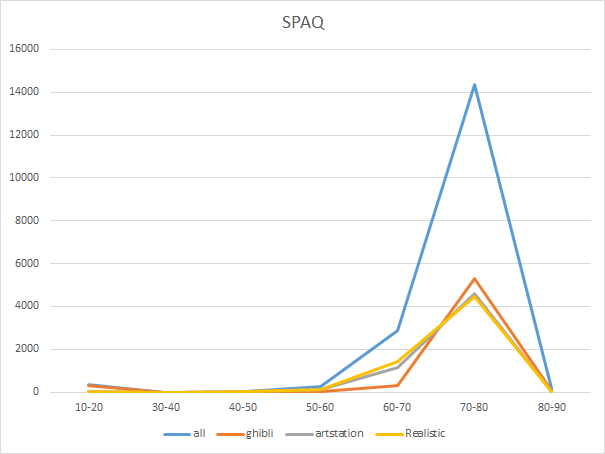
SPAQでもジブリの60-70部分が他より減っており、70-80は他より増えているので相対的にジブリスタイルの高評価が多いです。
結論
明らかにおかしい画像の足きりには使えそうですが、綺麗なイラストを抽出すると言う用途には難しそうに感じました。
「綺麗なイラスト」という主観が入る評価をシステマチックにやるのは難しいのだろうな、とは思います。
3.スマホ写真で学習した人工知能はStable Diffusionの画像をどう評価するか?関連リンク
1)github.com
google-research/musiq/
baidut / PaQ-2-PiQ
h4nwei / SPAQ

