
1.Stable Diffusionは写真とイラストのどちらが得意なのか?まとめ
・18000枚の画像をStable Diffusionで生成し、スコア付けして傾向を分析した
・今回の実験では写真系よりイラスト系画像の方が相対的によい品質と評価された
・モデルのような女性画像の方がデータとして多そうだがそうでもなかった
2.18000枚の画像内で評価が高かった画像とは?
18000枚の画像(3描画スタイル x 3シーン x 2性別 x 1000シード)を生成し「人工知能に描いて貰ったイラストを人工知能に採点してもらう」で紹介した画像美観評価モデルの改良版でスコア付けし、傾向をさっと探ってみました。
限定的ではありますが、有望そうな方向を検討するには十分かな、と思っています。
設定したスタイル
スタイル1
写真や写実的な画像の出力を期待したプロンプトです。
Realistic, Highly detailed, superrealism
スタイル2
(ジブリの)イラスト系の画像の出力を期待したプロンプトです。私の趣味です。
by Studio Ghibli, Hayao Miyazaki, Nausicaa, Kushana, San, Sheeta, Clarisse
スタイル3
ArtStationはクリエイター向けの作品投稿サイトです。このスタイルを追加する事でリアルタッチなイラスト系の画像が生成される事が期待されます。
trending on artstation
設定したシーン
プロンプト1
見た目のよい若い女性がモデル歩きをしているシーンです。
good-looking young girl fashion model walking on the runway
プロンプト2
見た目のよい若い男性がモデル歩きをしているシーンです。
good-looking young man fashion model walking on the runway
プロンプト3
若い女性のアスリートが公園を走っているシーンです。
young woman athlete is running at the park
プロンプト4
若い男性のアスリートが公園を走っているシーンです。
young man athlete is running at the park
プロンプト5
女性研究者が図書館で本を読んでいるシーンです。
woman researcher is reading book in the library
プロンプト6
男性研究者が図書館で本を読んでいるシーンです。
man researcher is reading book in the library
それではスタートです!
スコア上位トップ5のイラスト
1位と3位は髪の毛や顔が完全であり、中々このレベルの精緻さの画像は生成出きないので納得です。2,4,5位はどれも綺麗な画像ですが背景の本棚が色彩の豊富さに繋がってそれが高評価になっている気がします。
| 1位 | 2位 | 3位 | 4位 | 5位 |
 |
 |
 |
 |
 |
スコア下位トップ5のイラスト
これらは黒塗り画像(Stable Diffusionが出力した画像が見た目が非常にトラウマ級、もしくは不健全であった際に職場閲覧注意(NSFW:Not Safe For Work)警告が出て黒一色の画像が出力される)より低いスコアになっています。
こちらはaesthetic predictor V1と同様に透かしや文字が映りこんだ画像は評価が下がる傾向があるためと思います。
| 後ろから1位 | 後ろから2位 | 後ろから3位 | 後ろから4位 | 後ろから5位 |
 |
 |
 |
 |
 |
18枚の平均スコアが最も高かったシードの出力作品
評価の高い画像を生み出せる有望なシードとそうでもないシードで差があるのではないかと思いシード同士を比較してみました。
左から、Realistic、Ghibli、ArtStation。上からmodel、athlete、researcherに並べています。
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
18枚の平均スコアが最も低かったシードの出力作品
透かしの映り込みが低評価に繋がってそうですね。高品質画像を生み出しやすいシードとそうでないシードはあるような気がします。
こちらも左から、Realistic、Ghibli、ArtStation。上からmodel、athlete、researcherに並べています。
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
スタイル別のスコア分布
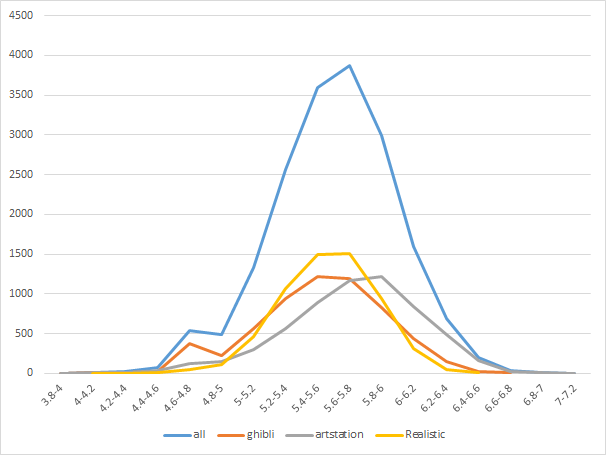
横軸はスコア、縦軸が件数です。artstation、つまりリアルタッチなイラスト系の画像が右に重心が寄っており、相対的に高評価画像を多く生成出来ています。
プロンプト別のスコア分布
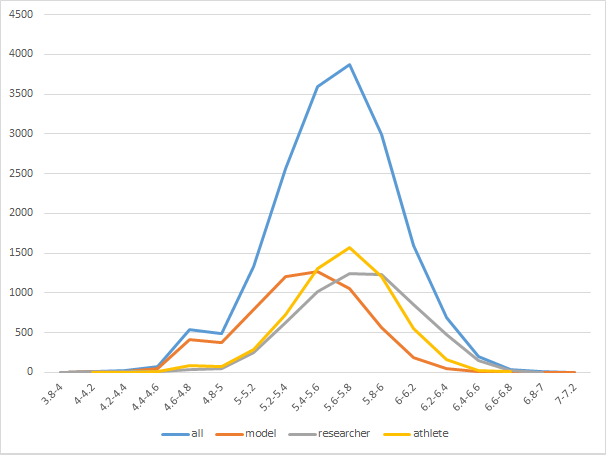
resercher、つまり研究者画像が右に重心が寄っており、相対的に高評価画像を多く生成出来ています。(ただこれは前述の本棚の影響の気もします)
男女別のスコア分布
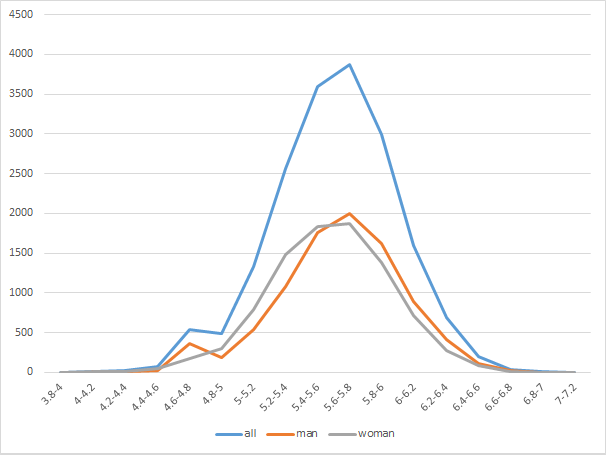
意外ですが、man、つまり男性の方がわずかに右に重心が寄っており、相対的に高評価画像を多く生成出来ています。
結論
この結果はimproved aesthetic predictorが各画像に採点したスコアに依存しているので他の画像美観評価モデルでやってみると異なった風景が見えてくるだろうとは思います。
しかし、写真系のモデルのような女性画像の方がデータとして多いだろうから得意なのだろうな、と思っていたところ、そうでもなさそうという結果は意外でした。
3.Stable Diffusionは写真とイラストのどちらが得意なのか?関連リンク
1)github.com
christophschuhmann / improved-aesthetic-predictor

