
1.Google Universal Image Embeddingチャレンジの紹介(2/2)まとめ
・同じ実体レベルの認識でもランドマークとアパレルでは実体にばらつきがあり性質が異なる
・従来の実体レベル認識を競うコンペでは対象とする領域を限定して認識能力を競っていた
・ユニバーサルイメージエンベッディングチャレンジは9つの領域を混在させて認識を行う
2.マルチドメインで実体レベルの認識を行う
以下、ai.googleblog.comより「Introducing the Google Universal Image Embedding Challenge」の意訳です。元記事は2022年8月4日、Bingyi CaoさんとMário Lipovskýさんによる投稿です。
アイキャッチ画像はlatent diffusionでプロンプトは「Arc de Triomphe de l’Étoile」。
| ドメイン | ランドマーク | アパレル |
| 画像 |  |
|
| 実体名 | エンパイアステートビル | Androidロゴ入りのサイクリングジャージ |
| 実体はクラスに属していますか? | 世界に1つしか実体がありません。 | 多くの物理的な実体があります。大きさや模様が異なる場合があります(例:模様のある布の切り方が違うなど) |
| 物体はどのような見え方をしますか? | 撮影条件(例:照明や視点)による外観の変化のみ、限られた数の共通の外部視点、多くの内部視点を持つ可能性 | 外観は変形可能(例:装着の有無)、共通する外観は正面、背面、側面と限定的 |
| 周辺はどのようなものですか?認識に有用ですか? | 周辺は、日や年の周期以外ではあまり変化しません。対象を認識する際に有用な可能性があります | 周辺は、環境の違い、衣服の追加、またはアクセサリーが目的の衣服を部分的に覆っている(例:ジャケットやスカーフ)ために大きく変化することがあります。 |
| 実体が含まれるクラスに属さない厄介なケースにはどんなものがありますか? | ランドマークのレプリカ(例:ラスベガスに存在するエッフェル塔)、お土産の模型 | 素材や色が異なる同じ服装、視覚的に非常によく似た服装で詳細をみる事でわずかに区別がつく(小さなブランドロゴなど)、同じモデルが着用する異なる服装 |
ランドマークとアパレルの例では、ドメイン間でばらつきがあります。
マルチドメイン特徴表現の学習
様々な領域をカバーする画像のコレクションが作成された後、次の課題は単一の普遍的なモデルを訓練することです。色彩の特徴表現など、いくつかの特徴やタスクは多くのドメインにまたがって有用であるため、どのドメインからの学習データを追加しても、色彩の識別能力の向上に役立つ可能性が高いです。
一方、特定のドメインに特化した特徴もあり、他のドメインからの学習データを追加すると、モデルの性能が低下する可能性があります。例えば、2Dアートワークの場合、複製に近いものを見つけることを学習するのはモデルにとって非常に有用ですが、変形や隠れた実体を認識する必要がある衣服の場合は、パフォーマンスが低下する可能性があります。
学習が必要な入力物体やタスクは多種多様であるため、学習データの選択、拡張、クリーニング、重み付けに新しいアプローチが必要になります。また、モデルの学習やチューニングのための新しいアプローチ、さらには新しいアーキテクチャが必要とされる事もあります。
ユニバーサルイメージエンベッディングチャレンジ
これらの課題に取り組む研究コミュニティのモチベーションを高めるために、Google Universal Image Embedding Challengeを開催しています。このチャレンジは7月にKaggleで開始され、10月まで開催され、総額$50,000の賞金が提供されます。優勝チームは、ECCV 2022のInstance-Level Recognitionワークショップでその手法を発表するよう招待される予定です。
参加者は、~5,000枚のテストクエリ画像と~200,000枚のインデックス画像から類似画像を検索するデータセットに対する検索タスクで評価される予定です。ImageNetがカテゴリラベルを含むのに対し、本データセットの画像は実体レベルでラベル付けされています。
評価データは、アパレル・アクセサリー、パッケージ商品、家具・家庭用品、玩具、車、ランドマーク、店頭、食器、アートワーク、ミーム、イラストなどの画像から構成されています。
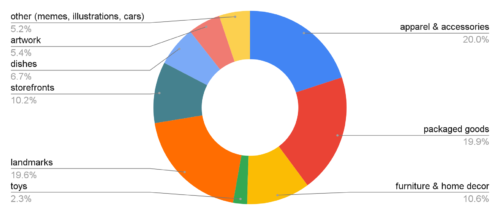
検索対象となる画像のドメイン分布
私達はECCV 2022で開催されるGoogle Universal Image Embedding Challengeへの参加とInstance-Level Recognitionワークショップへの参加を研究者や機械学習愛好家に呼びかけます。このチャレンジとワークショップが、マルチドメイン特徴表現に関する最先端の技術を発展させることを期待しています。
謝辞
このプロジェクトの中心的な貢献者は、Andre Araujo, Boris Bluntschli, Bingyi Cao, Kaifeng Chen, Mário Lipovský, Grzegorz Makosa, Mojtaba Seyedhosseini 及び Pelin Dogan Schönbergerです。また、Kaggleチャレンジの運営を手伝ってくれたTobias Weyand, Bohyung Han, Shih-Fu Chang, Ondrej Chum, Torsten Sattler, Giorgos Tolias, Xu Zhang, Noa Garcia, Guangxing Han, Pradeep Natarajan と Sanqiang Zhaoに感謝します。さらに、このプロジェクトのさまざまな場面でフィードバックやアイデア、サポートを提供してくれた Igor Bonaci, Tom Duerig, Vittorio Ferrari, Victor Gomes, Futang Peng, Howard Zhou に感謝します。
3.Google Universal Image Embeddingチャレンジの紹介(2/2)関連リンク
1)ai.googleblog.com
Introducing the Google Universal Image Embedding Challenge
2)www.kaggle.com
Google Universal Image Embedding

