
1.ViT-VQGAN:画像量子化技術を再考して画像生成と画像理解の性能を向上(1/2)まとめ
・事前学習は入力信号が文章である事を仮定しないので量子化すれば画像も扱う事が可能
・画像を離散トークンにエンコードし、それをCNNまたはTransformerでモデル化する
・ViT-VQGANはVQVAEに敵対的損失とViTと量子化を導入して改良したモデル
2.ViT-VQGANとは?
以下、ai.googleblog.comより「Vector-Quantized Image Modeling with Improved VQGAN」の意訳です。元記事は2022年5月18日、Jiahui YuさんとJing Yu Kohさんによる投稿です。
本文中のサンプル画像とattentionを引き付けている感から連想したアイキャッチ画像のクレジットはPhoto by Bonnie Kittle on Unsplash
近年、自然言語処理モデルは汎用的な特徴表現を学習する能力を飛躍的に向上させ、幅広い自然言語生成タスクや自然言語理解タスクにおいて大幅な性能向上を実現しています。これは、ラベル付けされていない膨大なテキスト資料を用いて言語モデルを事前学習させることによって達成されています。
この事前学習は、入力信号のモダリティ(言語、視覚、音声など)を仮定しません。最近のいくつかの論文では、この入力を仮定しない性質を利用して、画像を離散整数コード(自然数として表現)に事前量子化し、自己回帰的にモデル化(すなわち、一度に1トークンずつシーケンスを予測)することにより、画像生成結果を劇的に向上させることに成功しています。
これらのアプローチでは、畳み込みニューラルネットワーク(CNN:convolutional neural network)が、それぞれ画像の小さな断片に対応する離散トークンに画像をエンコードするように訓練される。次に、第2段階ではCNNまたはTransformerが、コード化された潜在変数の分布をモデル化するために学習します。第2段階は、学習後の画像を自己回帰的に生成するために適用することも可能です。しかし、このようなモデルは画像生成に対しては強力なパフォーマンスを達成していますが、識別タスク(画像分類など)に対して学習された特徴表現を評価した研究はほとんどありません。
論文「Vector-Quantized Image Modeling with Improved VQGAN」では、従来の画像量子化技術を再定義し、画像生成と画像理解タスクの性能を向上させる2段階のモデルを提案します。
第一段階では、VQGANと呼ばれる画像量子化モデルが画像を低次元離散潜在コードに符号化します。次に、画像の量子化された潜在コードをモデル化するために、Transformerモデルを学習させます。このアプローチは、ベクトル量子化画像モデリング(VIM:Vector-quantized Image Modeling)と呼ばれ、画像生成と教師なし画像特徴表現学習の両方に利用できます。私達は、画像量子化器の複数の改良点について述べ、より強力な画像量子化器を訓練することが、画像生成と画像理解の両方を改善するための重要な要素であることを示します。
ViT-VQGANによるベクトル量子化画像モデリング
画像を整数のトークンに量子化するモデルとして、最近よく使われているのが、Vector-quantized Variational AutoEncoder(VQVAE)です。これはCNNベースのオートエンコーダで、潜在空間が学習可能な離散変数の行列であり、直接学習されます。
VQGANはこれを改良したもので、高品質な再構成を促進するために敵対的損失を導入しています。VQGANは非局所的なattentionブロックでtransformerに似た要素を用いることで、より少ないレイヤー数で離れた位置にある相互作用を捉えることを可能にしています。
本研究では、CNNエンコーダとデコーダの両方をViTに置き換えることで、このアプローチをさらに一歩進めることを提案します。
さらに、整数トークンを参照するために、エンコーダの出力から低次元の潜在変数空間への線形射影を導入します。
具体的には、エンコーダの出力を768次元のベクトルから32次元または8次元のベクトルに縮小し、1つのコードにしました。これにより、デコーダがトークン出力をより有効に活用できるようになり、モデルの容量と効率が向上することを確認しました。
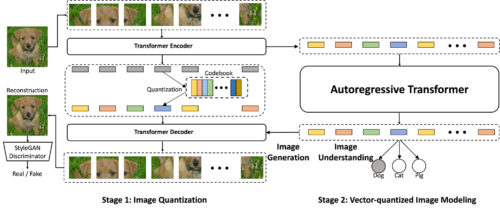
提案するViT-VQGAN(左)とVIM(右)の概要
連携することで画像生成と画像理解の両方が可能となります。第一段階でViT-VQGANは画像を離散的な整数に変換し、第二段階の自己回帰Transformerがそのモデル化を学習します。最後に、第一段階のデコーダがこれらのトークンに適用され、ゼロから高品質の画像を生成することができます。
3.ViT-VQGAN:画像量子化技術を再考して画像生成と画像理解の性能を向上(1/2)関連リンク
1)ai.googleblog.com
Vector-Quantized Image Modeling with Improved VQGAN
2)arxiv.org
Vector-quantized Image Modeling with Improved VQGAN

