
1.L2P:継続学習にプロンプトを導入してコンパクトな記憶を実現(2/2)まとめ
・L2PはリハーサルバッファやタスクIDが既知でなくとも高い性能を出す事ができる
・タスクに依存しない設定など、様々な複雑な継続的学習シナリオを扱う事も可能
・L2Pは実用的な継続学習アプリケーションに向けた新しい学習手法になる可能性
2.実用的な継続学習
以下、ai.googleblog.comより「Learning to Prompt for Continual Learning」の意訳です。元記事は2022年4月19日、Zifeng WangさんとZizhao Zhangさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Jed Villejo on Unsplash
継続学習(continual learning)シナリオでは、L2Pは学習可能なプロンプトプールを保持し、プロンプトは柔軟にサブセットとしてグループ化され、共同で動作することができます。
具体的には、各プロンプトは、キーと関連付けられています。キーはマッチした入力クエリの特徴表現間のコサイン類似度損失を減らすことによって学習されます。
これらのキーは、入力特徴量に基づいてタスクに関連するプロンプトのサブセットを動的に検索するクエリ機能によって利用されます。テスト時には、入力はクエリ関数によってプロンプトプールの上位N個のキーにマップされ、関連するプロンプトのembeddingがモデルの残りの部分に供給され、出力予測が生成されます。学習時には、プロンプトプールと分類ヘッドをクロスエントロピー損失により最適化します。
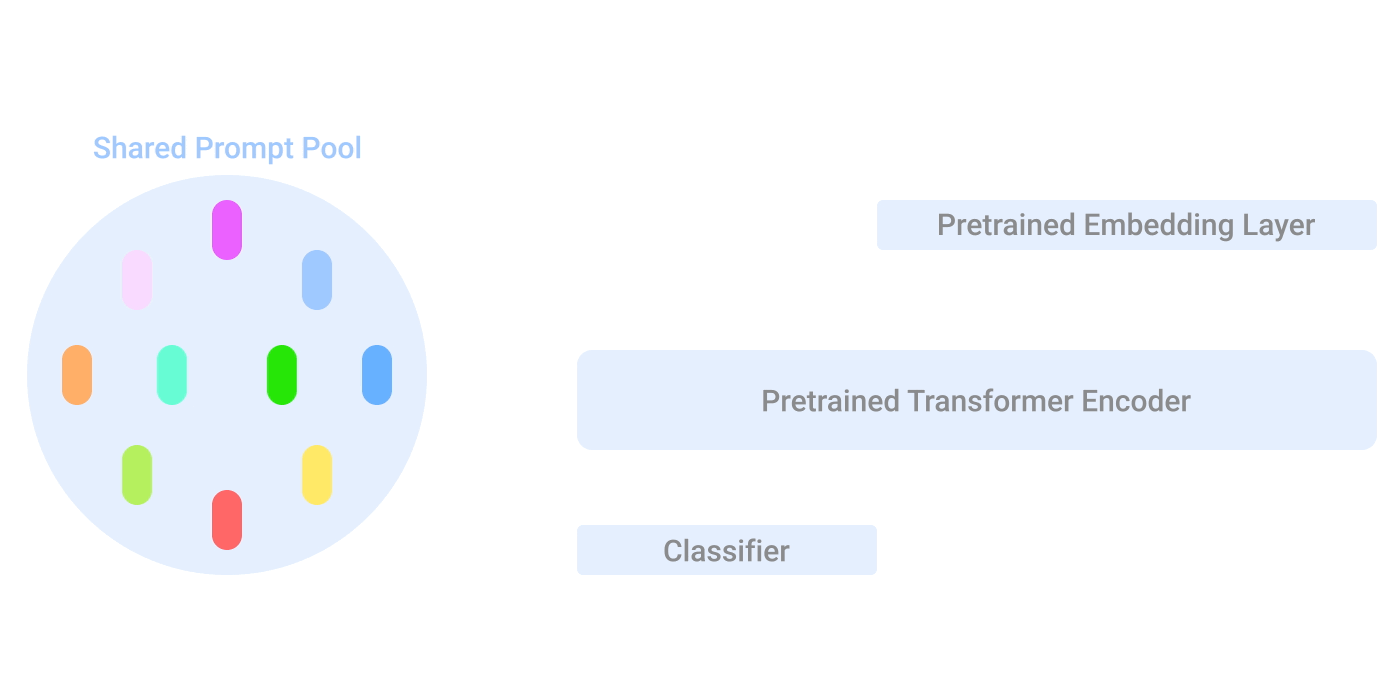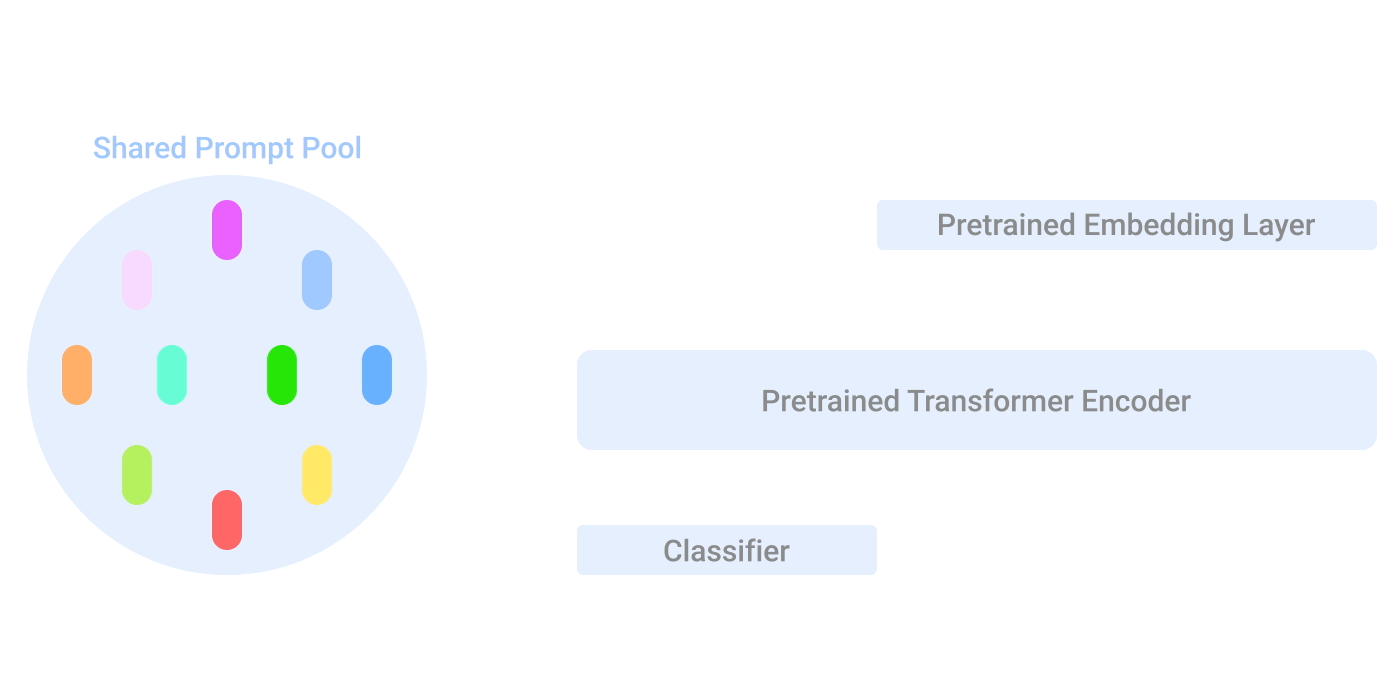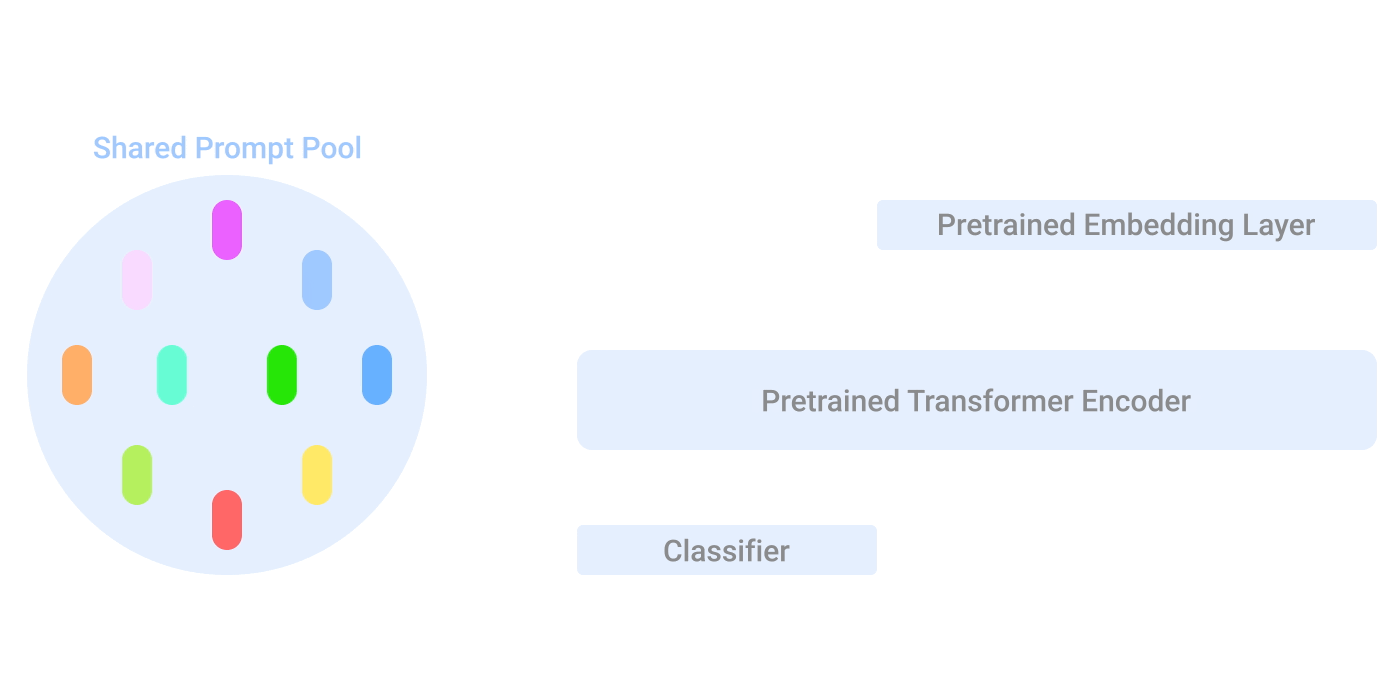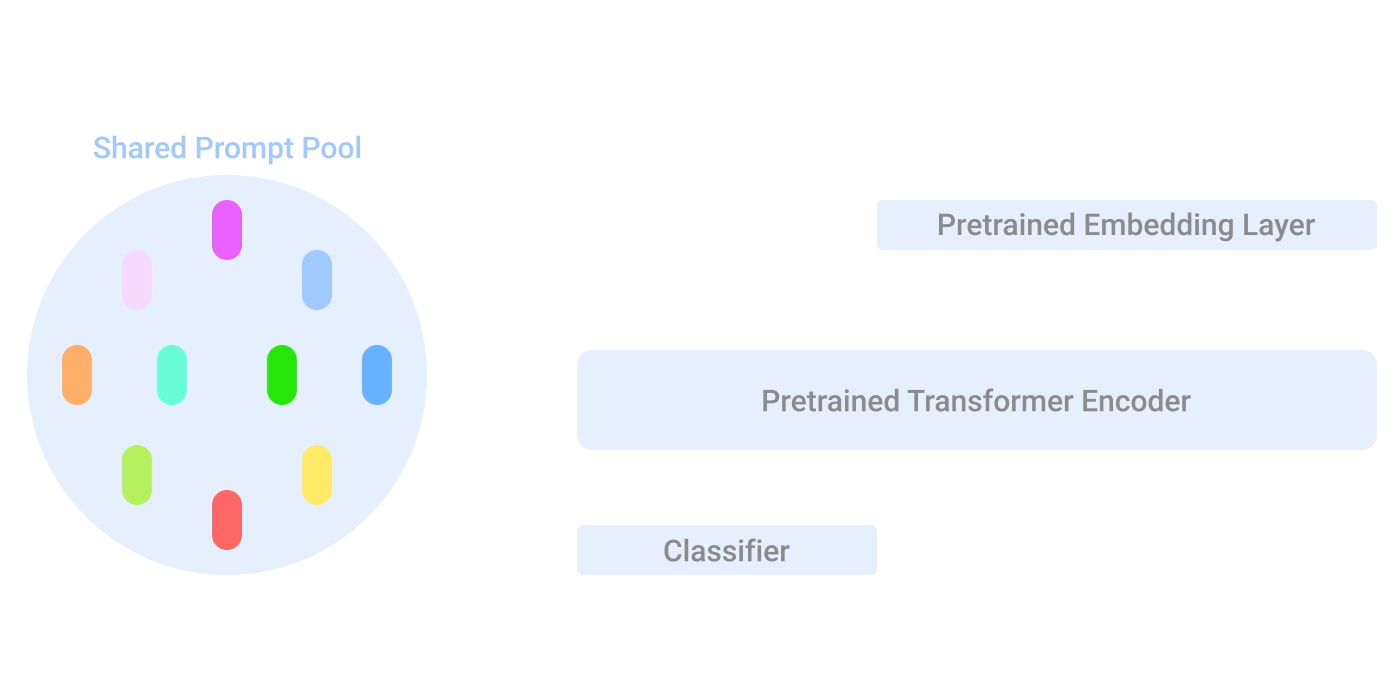
テスト時のL2Pの図解。まず、L2Pは提案する実体単位のクエリ機構に基づいて、キーと値のペアを持つプロンプトプールからプロンプトのサブセットを選択します。次に、L2Pは選択されたプロンプトを入力トークンの前に付加します。最後に、L2Pは拡張されたトークンを予測モデルに与えます。
直感的には、類似した入力例は類似したプロンプトのセットを選択する傾向があり、逆もまた同様です。したがって、頻繁に共有されるプロンプトはより一般的な知識を、他のプロンプトはよりタスクに特化した知識をエンコードしています。さらに、プロンプトは高レベルの命令を保存し、低レベルの事前学習された特徴表現表現を凍結しておくので、リハーサルバッファがない場合でも、破局的忘却を軽減することができます。実体単位のクエリ機構は、タスクの正体や境界を知る必要性を排除し、このアプローチはタスクにとらわれない継続学習という未解明の課題に取り組むことを可能にします。
L2Pの有効性
ImageNetで学習したVision Transformer(ViT)を用いて、代表的なベンチマークを対象に、異なるベースライン方式におけるL2Pの有効性を評価しました。以下のグラフでSequentialと呼ばれる素朴なベースラインは、全てのタスクに対して1つのモデルを逐次学習することを指します。
EWCモデルは正則化項を追加して忘却を軽減し、リハーサルモデルは過去のサンプルをバッファに保存して現在のデータとの混合学習(mixed training)を行います。全体的な継続学習性能を測定するために、すべてのタスク(最後のタスクを除く)において、精度と、学習中に達成した最高精度と最終精度の間の平均差(忘却と呼びます)の両方を測定します。
その結果、L2Pは両方の指標において、Sequential法とEWC法を大幅に上回ることがわかりました。特に、L2Pは過去のデータを保存する追加のバッファを使用するリハーサルアプローチをも凌駕しています。L2P法はリハーサル法と相互に影響を与えないため、リハーサルバッファを用いれば、さらに性能が向上する可能性があります。
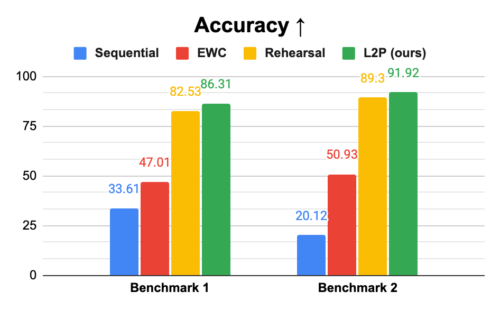
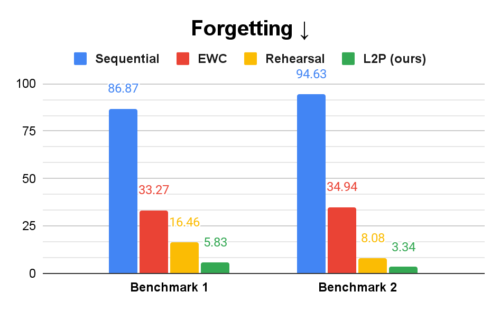
L2Pは、精度(上、accuracy)、忘却(下、forgetting)ともに比較手法を上回ります。精度は全タスクの平均精度を指し、忘却はトレーニング中に達成した最高精度と全タスク(最後のタスクを除く)の最終精度の平均差と定義されます。
また、類似タスクと多様なタスクを持つ2種類のベンチマークにおいて、実体単位のクエリ戦略によるプロンプト選択結果を可視化しました。その結果、L2Pは共有プロンプトを多くすることで類似タスク間の知識共有を促進し、タスク固有のプロンプトを多くすることで多様なタスク間の知識共有を減らすことが示されました。
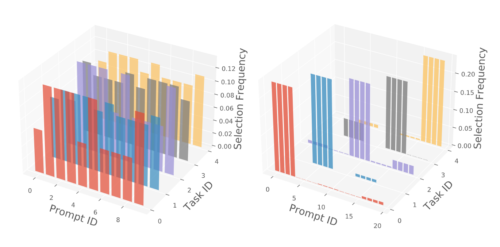
(左)類似タスクにおけるベンチマークプロンプト選択ヒストグラム
(右)多様なタスクにおけるベンチマークのプロンプト選択ヒストグラム
左のベンチマークはタスク内の類似性が高いため、タスク間でプロンプトを共有することで良好なパフォーマンスが得られ、右のベンチマークはよりタスクに特化したプロンプトを優先します
まとめ
本研究では、継続学習における重要な課題を新しい視点から解決するために、L2Pを発表しました。L2Pは、高い性能を達成するために、リハーサルバッファやテスト時にタスクIDが既知である事を必要としません。さらに、タスクに依存しない設定など、様々な複雑な継続的学習シナリオを扱うことができます。大規模な事前学習済みモデルは、実世界の問題に対する堅牢な性能から機械学習コミュニティで広く用いられているため、L2Pは実用的な継続学習アプリケーションに向けた新しい学習パラダイムを切り開くものと考えています。
謝辞
Chen-Yu Lee, Han Zhang, Ruoxi Sun, Xiaoqi Ren, Guolong Su, Vincent Perot, Jennifer Dy, Tomas Pfisterを含む他の共著者の貢献に対して感謝します。また、Chun-Liang Li, Jeremy Martin Kubica, Sayna Ebrahimi, Stratis Ioannidis, Nan Hua, Emmanouil Koukoumidis には、貴重な議論とフィードバック、そして Tom Small には図の作成に感謝します。
3.L2P:継続学習にプロンプトを導入してコンパクトな記憶を実現(2/2)関連リンク
1)ai.googleblog.com
Learning to Prompt for Continual Learning
2)arxiv.org
Learning to Prompt for Continual Learning

