
1.ALX:大規模な行列計算をTPU上で実現(3/3)まとめ
・ALXのパラメータを慎重に調整し、メモリを半減させながら精度を維持する事ができた
・理想はコア数を増すと線形に学習時間が減少する事だがネットワーク通信時間の影響を受ける
・ALXは簡単に使えるように、コードはオープンソース化されておりGCPで容易に実行可能
2.ALXと大規模データ
以下、ai.googleblog.comより「Large-Scale Matrix Factorization on TPUs」の意訳です。元記事は2022年4月8日、Harsh Mehtaさんによる投稿です。
映画のMatrix(行列)をイメージしたアイキャッチ画像のクレジットはPhoto by Brian Wangenheim on Unsplash
結果
精度と線形ソルバーの選択に関する考察を基に、ALXのシステムパラメータと品質パラメータを慎重に調整しました。embeddingテーブルの格納精度(bfloat16)と線形ソルバーの入力精度(float32)を慎重に選択することで、embeddingに必要なメモリを半減させながら、ソルバー段階で値が低精度である事に起因する問題を回避できることを確認しました。
線形ソルバーには、TPUで最速であることが判明した共役勾配(conjugate gradients)を選択しました。embedding次元は128次元とし、16エポック分の学習を行いました。私達の経験では、以下の表に示すように、ノルムペナルティ(λ)と非観測重み(α)の両方に対するハイパーパラメータのチューニングは、良好な再現率を得るために欠かせないものでした。

WebGraphデータセットの全バージョンでALXを実行した結果
再現率1.0は完全な再現を意味します。
規模拡大時の性能
入力データはTPUコア間で並列処理されるため、コア数を増やすと、理想的には線形に学習時間が減少します。しかし同時に、コア数を増やすと、より多くのネットワーク通信が必要になります。(シャード内embeddingテーブルが原因)。高速なTPU間接続のおかげで、このオーバーヘッドはコア数が少ないうちは無視できますが、コア数が増えるにつれて、オーバーヘッドは最終的に理想的な線形スケーリングを鈍らせることになります。
この仮説を実証するため、利用可能なTPUコアの数を増やしながら、4種類のWebGraphの規模を拡大させて特性を学習時間の観点から分析しました。以下に示すように、経験的にも、あるスイートスポットまでは予測された学習時間が線形に減少する傾向が観察され、それ以降はネットワークのオーバーヘッドが減少を遅らせることが確認されました。
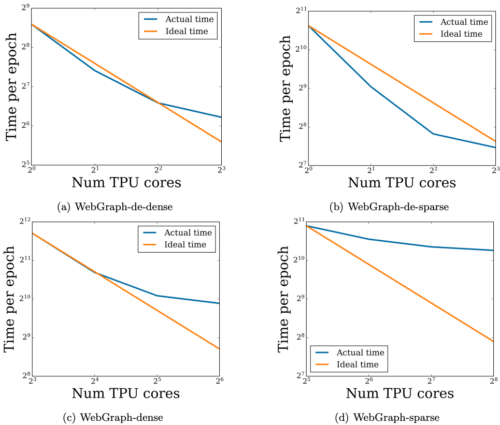
TPUコア数の増加と実行時間の関係
各図は、1エポックの学習に要した時間を秒単位でグラフ化したものです
まとめ
ALXは簡単に使えて、再現できるように、コードはオープンソース化されており、Google Cloud上で容易に実行することができます。実際、WebGraph-denseのようなサイズ1.35億 x 1.35億(220億のエッジを持つ)の疎行列を、8つのTPUコアに接続したcolab(訳注:特殊な設定をしたものだと思います)で1日もかからずに因数分解できることを例示しました。
私たちは規模拡張性を念頭にALXフレームワークを設計しています。256個のTPUコアで、最大のWebGraphのバリエーションであるWebGraph-sparse(3.65億 x 3.65億のスパース行列)の1エポックは約20分で終了します(全トレーニング実行で5.5時間)。最終的なモデルのパラメータは約1000億です。ALXとWebGraphがこれらの分野の研究者と実務者の両方に役立つことを期待しています。ALXのコードはgithubにあります。
謝辞
コアチームにはSteffen Rendle, Walid Krichene そして Li Zhangがいます。このプロジェクトの様々な段階で協力してくれた多くのGoogleの同僚に感謝します。特に、James BradburyとSkye Wanderman-MilneをはじめとするJAXチームには多くの議論を、Blake HechtmanにはXLAを、Rasmus LarsenにはTPU上の線形ソルバーの性能について有益な議論を、それぞれ提供していただき、感謝しています。最後に、有益なフィードバックを提供してくれた Nicolas Mayoraz、John Anderson、Fernando Pereira にも感謝します。
3.ALX:大規模な行列計算をTPU上で実現(3/3)関連リンク
1)ai.googleblog.com
Large-Scale Matrix Factorization on TPUs
2)arxiv.org
ALX: Large Scale Matrix Factorization on TPUs
3)github.com
google-research/alx/
4)www.tensorflow.org
web_graph

