
1.JSRL:事前ポリシーを効率的に使用して強化学習をジャンプスタート(2/2)まとめ
・JSRLは任意の初期ガイドポリシーや微調整アルゴリズムと組み合わせて使用する事が可能
・視覚ベースタスクでも他のすべての手法よりも高速に改善可能で最も高い成功率を達成
・今後はSim2Realなどの問題にJSRLを適用し複数のガイドポリシーで訓練する方法を検討予定
2.JSRLの性能
以下、ai.googleblog.comより「Efficiently Initializing Reinforcement Learning With Prior Policies」の意訳です。元記事は2022年4月6日、Ikechukwu UchenduさんとTed Xiaoさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Erik Dungan on Unsplash
IL+RLベースラインとの比較
JSRLは強化学習(RL:Reinforcement Learning)を初期化するために事前学習を用いることができるため、オフラインのデータセットで学習を行い、新しいオンラインデータを使った経験によって事前学習を微調整する模倣・強化学習(IL+RL:Imitation and Reinforcement learning)手法と比較するのが自然でしょう。
本論文では、D4RLベンチマークタスクにおいて、JSRLとIL+RL手法の比較を行います。これらのタスクには、ロボット制御環境のシミュレーションや、人間の実演者のオフラインデータ、プランナー、その他の学習済みポリシーのデータセットが含まれます。D4RLタスクのうち、私達は難易度の高い蟻の迷路(ant maze)と器用な操作(dexterous manipulation)環境に着目します。

蟻の迷路(左)と器用な操作(右)の環境例
各実験では、オフラインのデータセットで学習を行い、その後オンラインで微調整を行いました。
各実験では、AWAC、IQL、CQL、行動クローニング(behavioral cloning)など、各設定に特化して設計されたアルゴリズムと比較しています。JSRLは任意の初期ガイドポリシーや微調整アルゴリズムと組み合わせて使用することができますが、私たちの最強のベースラインであるIQLを事前学習したガイドとして、また微調整して使用しています。
D4RLの完全データセットには、蟻の迷路タスクの各オフライン遷移が100万件含まれています。各遷移は、エージェントがどの状態で開始したか(S)、エージェントが取った行動(A)、エージェントが受け取った報酬(R)、エージェントが行動Aを取った後に終了した状態(S’)を指定する一連のフォーマット(S、A、R、S’)です。
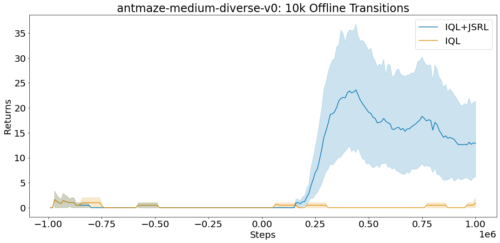
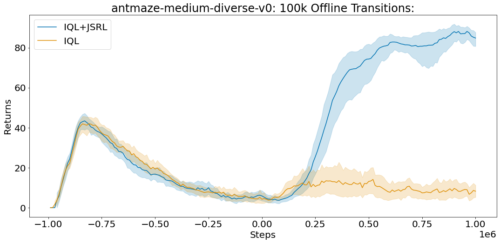
D4RL benchmark suiteのantmaze-medium-diverse-v0環境での平均スコア(max=100)。JSRLは、オフライン遷移へのアクセスが限定されている場合でも、改善することができます。
視覚に基づくロボットタスク
オフラインデータの活用は、次元の呪い(curse of dimensionality)により、視覚ベースのロボット操作のような複雑なタスクでは特に困難です。
連続制御行動空間(continuous-control action space)と画素ベースの状態空間(pixel-based state space)の両方が高次元であるため、IL+RL手法にとって、良いポリシーを学習するために必要なデータ量の観点から規模拡大の課題があります。
そこで、JSRLがこのような環境に対してどのように適応できるかを調べるために、無差別把持(indiscriminate grasping:任意の物体を持ち上げる)と実体把持(instance grasping:特定の対象物を持ち上げる)という二つの難しいロボット操作タスクのシミュレーションに注目します。

模擬ロボットアームは、様々なカテゴリの物体が置かれたテーブルの前に置かれます。ロボットが物体を持ち上げたとき、無差別把持課題では疎な報酬が与えられます。実体把持タスクでは、特定の対象物を把持したときのみ、疎な報酬が与えられます。
JSRLをQT-OptやAW-Optのような複雑な視覚ベースのロボティクス設定に拡張できる手法と比較します。各手法は、成功したデモンストレーションの同じオフラインデータセットにアクセスし、最大10万ステップのオンライン微調整を実行することができる事とします。
この実験では、行動クローニングをガイドポリシーとして用い、JSRLとQT-Optを組み合わせて微調整を行います。QT-Opt+JSRLの組み合わせは、他のすべての手法よりも高速に改善され、かつ最も高い成功率を達成することができました。
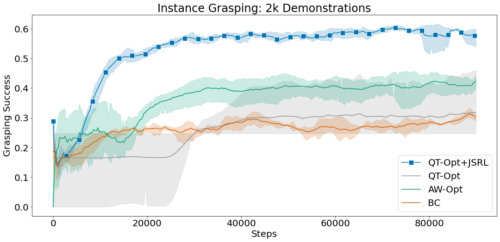
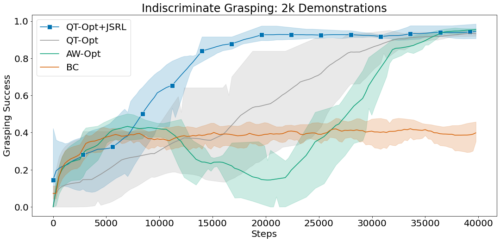
2000回の成功デモを用いた無差別把持環境と実体把持環境における平均把持成功率
まとめ
RLタスクの初期化において、任意の形式の事前方針を利用して探索を改善する手法JSRLを提案しました。このアルゴリズムでは、既存のガイドポリシーを巻き込んで学習カリキュラムを作成し、その後に自己改善型の探索ポリシーが続きます。
探索ポリシーはゴールに近い状態から探索を開始するため、探索ポリシーの仕事は非常に単純化されます。探索ポリシーが改善されるにつれて、ガイドポリシーの効果は減少し、十分なRLポリシーが得られるようになります。今後は、Sim2Realなどの問題にJSRLを適用し、複数のガイドポリシーを利用してRLエージェントを訓練する方法を検討する予定です。
謝辞
この研究は、Ikechukwu Uchendu, Ted Xiao, Yao Lu, Banghua Zhu, Mengyuan Yan, Joséphine Simon, Matthew Bennice, Chuyuan Fu, Cong Ma, Jiantao Jiao, Sergey Levine, そしてKarol Hausmanなしには実現できなかっただろう。この記事のアニメーションを制作してくれたTom Smallに感謝します。
3.JSRL:事前ポリシーを効率的に使用して強化学習をジャンプスタート(2/2)関連リンク
1)ai.googleblog.com
Efficiently Initializing Reinforcement Learning With Prior Policies
2)arxiv.org
Jump-Start Reinforcement Learning

