
1.PRIME:のシミュレーションログ使ってアクセラレータを新規に設計(2/3)まとめ
・PRIMEを未知のアプリケーションに汎化させるためにレイヤー数など高レベル特徴を与えている
・PRIMEはEdgeTPUに比べて2.69倍(t-RNN Encでは最大11.84倍)遅延を改善できた
・更にチップ面積削減用のトレーニングを受けていないのチップ面積を1.50倍削減できた
2.PRIMEの一般化性能
以下、ai.googleblog.comより「Offline Optimization for Architecting Hardware Accelerators」の意訳です。元記事は2022年3月17日、Amir YazdanbakhshさんとAviral Kumarさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Wesley Tingey on Unsplash
原理的には、データ駆動型アプローチの主な利点の1つは、モデルを何に対して最適化させるのか指示した上で、目的とするアプリケーションに対して一般化可能な高度な表現力と汎用性のあるモデルを学習できることです。
同時に、設計者がアクセラレータの最適化を試みたことがない新しい未知のアプリケーションに対しても有効である可能性があります。
PRIME が未知のアプリケーションに汎化するように学習させるために、私達はモデルを、コンテキストベクトルに条件付けして修正します。
これは、高速化したいニューラルネットのアプリケーションを特定するもので、以下の実験で説明するように、ターゲットとするアプリケーションの高レベルの特徴(フィードフォワード層の数、畳み込み層の数、総パラメータなど)を使用することにします。
そして、設計者達がこれまで調査した全てのアプリケーション用のアクセラレータデータで単一の大きなモデルを学習させます。
後述の結果にあるように、PRIMEのこのコンテキストに基づく修正により、複数の同時アプリケーションと新しい未知のアプリケーションの両方に対して、ゼロショット方式でアクセラレータを最適化することが可能になるのです。
PRIMEは手動設計されたアクセラレータを凌駕するでしょうか?
PRIMEを実際のアクセラレータ設計の様々なタスクで評価しました。まず、9つのアプリケーションを対象にPRIMEが設計した最適化アクセラレータと、手動で最適化したEdgeTPUの設計を比較します。
EdgeTPUアクセラレータは、主に画像分類のアプリケーション、特にMobileNetV2、MobileNetV3、MobileNetEdgeを実行するために最適化されています。
私達の目標は、PRIMEがベースラインのEdgeTPUアクセラレータよりも低遅延で、かつチップ面積を27mm2以下(EdgeTPUアクセラレータのデフォルト)に抑えたアクセラレータを設計できるかどうかを確認することです。
下図に示すように、PRIMEはEdgeTPUに比べて2.69倍(t-RNN Encでは最大11.84倍)遅延を改善し、同時にチップ面積を1.50倍(MobileNetV3では最大2.28倍)削減することができました。チップ面積削減用のトレーニングを受けていないのにです!
カスタムメイドのEdgeTPUアクセラレータが最適化対象にしたMobileNetの画像分類モデルでも、PRIMEは待ち時間を1.85倍に改善しました。
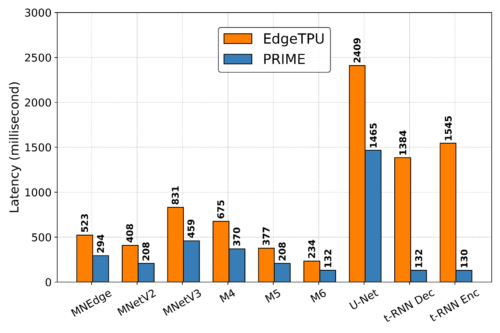
PRIMEとEdgeTPUが提案する単一モデル特化型のアクセラレータ設計の遅延時間を比較(低い方が良い)
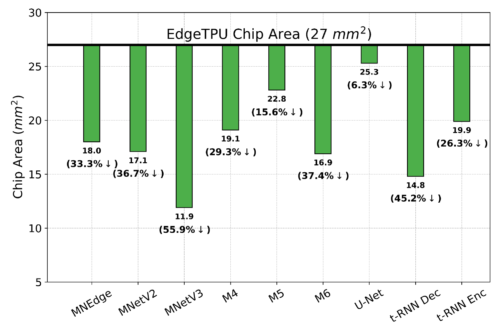
単一モデル特化型のベースラインEdgeTPU設計と比較したチップ面積(小さい方が良い)の削減量
3.PRIME:のシミュレーションログ使ってアクセラレータを新規に設計(2/3)関連リンク
1)ai.googleblog.com
Offline Optimization for Architecting Hardware Accelerators
2)arxiv.org
Data-Driven Offline Optimization For Architecting Hardware Accelerators
3)github.com
google-research/prime/
