
1.PRIME:のシミュレーションログ使ってアクセラレータを新規に設計(3/3)まとめ
・PRIMEは複数アプリケーション対応とゼロショット対応の2つの目的で設計されている
・一部モデルではシミュレータ駆動型の方が待ち時間が短いがPRIMEはメモリを優先していた
・PRIMEはハードウェアとソフトウェアの協調設計に使用する事が有望と考えられる
2.PRIMEのトレードオフ
以下、ai.googleblog.comより「Offline Optimization for Architecting Hardware Accelerators」の意訳です。元記事は2022年3月17日、Amir YazdanbakhshさんとAviral Kumarさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Wesley Tingey on Unsplash
新規、もしくは複数アプリケーション用にアクセラレータをゼロから設計
私達は、PRIMEが保存されているアクセラレータデータを使用して、以下の2つの目的でPRIMEを最適化します。
(1)複数のアプリケーションで同時にうまく機能する単一のアクセラレータを設計する
(2)ゼロショット設定で、PRIMEは新しい未知のアプリケーションのためのアクセラレータを、そのようなアプリケーションからのデータで訓練せずとも生成できなければならない
両設定において、私達は、ターゲットアプリケーションを識別するコンテキストベクトル(contextual version)で条件付けして、PRIMEのコンテキストバージョンを訓練し、最終的なアクセラレータを得るために学習したモデルを最適化します。
私達は、PRIMEが両方の設定において最高のシミュレータ駆動型アプローチを上回ることを見いだしました。学習用に提供されるデータが非常に少なくても、多くのアプリケーションで利用することができます。
特にゼロショット設定では、PRIMEは比較した最良のシミュレータ駆動型手法を上回り、1.26倍の待ち時間の短縮を達成しました。また、学習アプリケーションの数が増えるにつれて、性能の差は大きくなっていきます。

ゼロショット設定でのテストアプリケーションの平均待ち時間(低いほど良い)を最先端のシミュレータ駆動アプローチと比較
各棒グラフの上にあるテキストは、トレーニングアプリケーションのセットを示しています。
PRIMEで設計したアクセラレータを詳細に分析
ハードウェアアーキテクチャをより深く理解するために、PRIMEによって設計された最適なアクセラレータを検証し、シミュレータ駆動型アプローチによって見つかった最適なアクセラレータと比較します。
ここでは、チップ面積100mm2という制約のもと、MobileNetEdge、MobileNetV2、MobileNetV3、M4、M5、M64、t-RNN Dec、t-RNN Enc、U-Netという9つのアプリケーションすべてに対して最適化したアクセラレータをする必要があるという設定を考えています。その結果、PRIMEはシミュレータ主導のアプローチに比べ、レイテンシーを1.35倍改善することがわかりました。
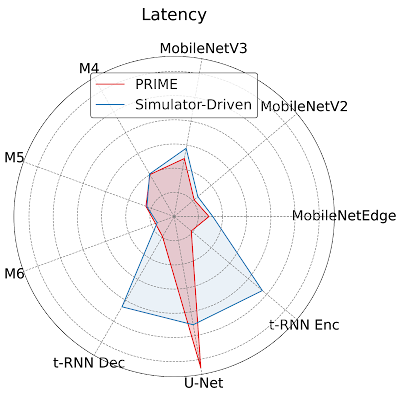
PRIMEが提案する最適なアクセラレータ設計と、マルチタスクアクセラレータ設計のための最先端のシミュレータ駆動型アプローチのアプリケーションごとの待ち時間(低いほど良い)。PRIMEは、シミュレータ駆動方式に比べて、9つのアプリケーションの平均待ち時間を1.35倍短縮しました。
このように、MobileNetEdge、MobileNetV2、MobileNetV3、M4、t-RNN Dec、t-RNN EncではPRIMEで設計したアクセラレータの方が待ち時間が短いのに対し、M5、M6、U-Netではシミュレータ駆動型で求めたアクセラレータがより短い待ち時間を実現していることがわかりました。
アクセラレータの構成を詳しく調べたところ、PRIMEは「計算能力(PRIMEは64コア、シミュレータ駆動型は128コア)」を、より「メモリーサイズ(2,097,152バイト、1,048,576バイト)と引き換えにしていることが判明しました。
これらの結果は、待ち時間の大幅な短縮が可能なt-RNN Decとt-RNN Encにおいて、より大きなメモリ要件に対応するためにPRIMEがメモリサイズを優先していることを示しています。固定された面積予算のもとでは、より大きなオンチップメモリを優先すると、アクセラレータの計算能力が犠牲になります。このアクセラレータの演算能力の低下は,演算量の多いモデル(M5,M6,U-Net)において、待ち時間を増加させることになります。
まとめ
PRIME の有効性は、アクセラレータの設計パイプラインにおいて、ログに記録されたオフラインデータを活用する可能性を浮き彫りにしています。なぜなら、シミュレータ主導のアプローチでは、干し草の山から針を探すような複雑な最適化問題を解く必要がありますが、PRIMEでは元のモデルを代用モデルとして一般化することで利益を得ることができるからです。
一方、PRIMEは、今回の実験で利用した先行シミュレータ駆動型手法の性能を上回っており、このため、シミュレータ駆動型手法の中で候補として使用する事も有望ななる事にも注目に値します。
より一般的には、性能の低い設計のオフラインデータセットで強力なオフライン最適化アルゴリズムをトレーニングすることは、少なくとも、以前のデータを捨ててしまうのではなく、ハードウェア設計を開始する上で非常に効果的な材料となりえます。最後に、PRIMEの一般性を考えると、私たちはこれをハードウェアとソフトウェアの協調設計に使用することを望んでいます。また、PRIMEの学習コードとアクセラレータのデータセットも公開しています。
謝辞
共著者のSergey Levine, Kevin Swersky, Milad Hashemiの助言、考察、提案に感謝します。
James Laudon, Cliff Young, Ravi Narayanaswami, Berkin Akin, Sheng-Chun Kao, Samira Khan, Suvinay Subramanian, Stella Aslibekyan, Christof Angermueller, およびOlga Wichrowskafor にはご協力とご支援、そして Sergey Levine にはこのブログ記事に対するご意見をお寄せいただきました。さらに、「Learn to Design Accelerators」、「EdgeTPU」、およびVizierチームの皆さんからは、貴重なフィードバックと示唆をいただきましたので、感謝の意を表したいと思います。
また、この記事で使用したアニメーション図を提供してくださったTom Smallに感謝します。
3.PRIME:のシミュレーションログ使ってアクセラレータを新規に設計(3/3)関連リンク
1)ai.googleblog.com
Offline Optimization for Architecting Hardware Accelerators
2)arxiv.org
Data-Driven Offline Optimization For Architecting Hardware Accelerators
3)github.com
google-research/prime/

