
1.Platform-Aware NAS:ハードウェア性能を最高に引き出すニューラル・アーキテクチャ探索(2/2)まとめ
・プラットフォームを意識したNASを使いTPUやGPUに最適化したEfficientNet-Xを設計
・TPUv3およびGPUv100においてEfficientNet-XはEfficientNetの平均1.5~2倍の高速化を達成
・EfficientNet-XはTPUv2からTPUv4iに移行させると2.6倍の高速化を実現する
2.EfficientNet-Xとは?
以下、ai.googleblog.comより「Unlocking the Full Potential of Datacenter ML Accelerators with Platform-Aware Neural Architecture Search」の意訳です。元記事は2022年2月8日、Sheng LiさんとNorman P. Jouppiさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by jesse orrico on Unsplash
先進的なプラットフォーム対応型NASは、TPUやGPU上でのMLモデル実行の並列性を総合的に向上させるための補完的な技術群を含む最適化された探索空間を持っています。
・行列乗算ユニット(MXU:Matrix Multiplication Units) / TensorCoresの並列性を最大化するために、特殊なテンソル再成形テクニックを使用します。
・ベクトル処理と行列・テンソル処理の重複を防ぐため、行列演算の種類に応じて異なる活性化関数を動的に選択します。
・ハイブリッド畳み込みと新しい融合戦略(fusion strategy)を採用し、総計算量と演算強度のバランスをとることで、計算とメモリアクセスが並列に行われ、ベクトル処理ユニット(VPU:Vector Processing Units) / CUDAコアの競合が減少するように設計されています。
・FLOPsの代わりにハードウェア性能を性能目標としてモデルの深さ、幅、解像度を探索するLACS(Latency-Aware Compound Scaling)により、モデル群全体について、すべてのレベルで効率的な選択肢を限界まで追求しつつ、並列性を確保します。
EfficientNet-X: TPU/GPU向けのプラットフォームを意識したNASによる最適化コンピュータ視覚モデル
このようにプラットフォームを意識したNASのアプローチを用いて、TPUやGPUに最適化されたコンピュータビジョンモデル群であるEfficientNet-Xを設計しています。このモデル群は、EfficientNetアーキテクチャをベースとしています。
EfficientNetアーキテクチャ自体は、本当の意味でのハードウェア対応最適化機能を持たない従来の多目的NASによって設計されたものです。その結果、EfficientNet-Xモデルファミリーは、同等の精度で、TPUv3およびGPUv100において、それぞれEfficientNetの平均1.5倍から2倍の高速化を達成しました。
EfficientNet-Xは、高速化だけでなく、FLOPsと真の性能の非比例性にも光を当てています。多くの人は、FLOPsがMLの性能の良い代用品(つまり、FLOPsと性能は比例する)だと思っていますが、そうではありません。FLOPsはスカラーマシンのような単純なハードウェアでは良い性能代理ですが、高度な行列/テンソルマシンでは最大400%の誤差を示すことがあります。例えば、EfficientNet-Xは、そのハードウェアに適したモデルアーキテクチャにより、EfficientNetの2倍以上のFLOPsを必要としますが、TPUやGPUでは2倍以上高速になります。
EfficientNet-Xは、高速化だけでなく、FLOPsと真の性能の非比例性にも光を当てました。多くの人は、FLOPs、つまり1秒間に浮動小数点演算を何回できるかを示した数値がMLの性能を表す良い指標値(つまり、FLOPsとMLの性能は比例する)だと思っていますが、そうではありません。
FLOPsはスカラー演算を行う単純なハードウェアでは良い性能指標ですが、高度な行列/テンソルマシンでは最大400%の誤差を示すことがあります。例えば、EfficientNet-Xは、そのハードウェアに適したモデルアーキテクチャにより、EfficientNetの2倍以上の浮動小数点演算が必要になりますが、TPUやGPUで実行すると2倍以上高速になります。
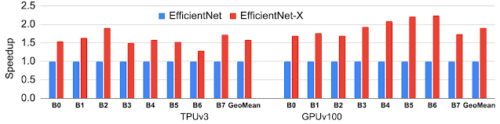
EfficientNet-Xモデル群は、TPUv3およびGPUv100において、同等の精度で、最先端のEfficientNetモデル群と比較して平均1.5倍から2倍の速度向上を達成しました。
新しいアクセラレータにも対応する遺伝子を持つプラットフォーム対応のNAS
プラットフォームを意識したNASは、ハードウェアの内部構造を明らかにし、ハードウェアに最適化されたMLモデルを設計する際にその特性を活用します。
モデルの「プラットフォーム対応」とは、いわば、特定のハードウェアの性能を最適化する知識を保持する「遺伝子」を持つ事です。新しい世代のハードウェアに対してモデルを再設計する必要はありません。
例えば、TPUv4iは前世代のTPUv2に比べて最大3倍のピーク性能(FLOPS)を実現しますが、TPUv2からTPUv4iに移行してもEfficientNetの性能は30%しか向上しません。
これに対し、EfficientNet-Xは、新しいハードウェアでもプラットフォームを意識した特性を維持し、TPUv2からTPUv4iへの移行時に2.6倍の高速化を達成し、2世代間のアップグレードで期待できる3倍のピーク性能向上の恩恵をほぼ利用することができます。
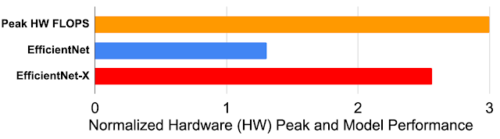
TPUv2からTPUv4iへ移行した際のハードウェアピーク性能比と、EfficientNet-XとEfficientNetファミリーの速度向上の平均
まとめと今後の課題
私たちは、データセンターのMLアクセラレータ、特にTPUとGPUのためにプラットフォーム対応NASの機能を向上させる方法を実証しました。プラットフォーム対応NASとEfficientNet-Xモデルファミリーの両方が実運用に導入され、Googleの様々な内部コンピュータビジョンプロジェクトにおいて、最大40%の効率向上と大幅な品質改善を実現しました。
さらに、アクセラレータのハードウェアアーキテクチャを深く理解しているため、プラットフォーム対応NASは、TPUv2とv4iアーキテクチャの重要な性能ボトルネックを特定することができ、将来のTPUに対して大幅な性能向上が期待できる設計強化を可能にしました。
次のステップとして、コンピュータビジョン以外のMLハードウェアやモデル設計にプラットフォームアウェアNASの機能を拡張することに取り組んでいます。
謝辞
共著者に感謝します。Mingxing Tan, Ruoming Pang, Andrew Li, Liqun Cheng, Quoc Le。
また、Jeff Dean, David Patterson, Shengqi Zhu, Yun Ni, Gang Wu, Tao Chen, Xin Li, Yuan Qi, Amit Sabne, Shahab Kamali、その他、プラットフォーム対応 NAS の研究およびその後の幅広い製品展開に協力してくれた Google の幅広い研究・エンジニアリングチームからの多くの共同研究者に感謝しています。
3.Platform-Aware NAS:ハードウェア性能を最高に引き出すニューラル・アーキテクチャ探索(2/2)関連リンク
1)ai.googleblog.com
Unlocking the Full Potential of Datacenter ML Accelerators with Platform-Aware Neural Architecture Search
2)openaccess.thecvf.com
Searching for Fast Model Families on Datacenter Accelerators(PDF)

