1.毛先まで明瞭に自撮りできるPixel 6のポートレートモード(1/2)まとめ
・従来のマスク手法は画素が前景に属するか背景に属するかをYes or Noの2値で判断していた
・2値しか持たないと透明度の値を推定する必要があり髪の毛などの細部を含む画像は困難
・Pixel 6のアルファマットは毛先レベル髪の詳細と正確な前景境界を保持することが可能
2.アルファマットとは?
以下、ai.googleblog.comより「Accurate Alpha Matting for Portrait Mode Selfies on Pixel 6」の意訳です。元記事は2022年1月24日、Sergio Orts EscolanoさんとJana Ehmanさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Erica Marsland Huynh on Unsplash
イメージマット(image matting)とは、画像内の前景と背景の物体を分離する正確なアルファマット(alpha matte)を抽出するプロセスです。この技術は、映画制作や写真業界において、背景の置き換え、合成ボケ、その他の視覚効果など、画像やビデオの編集目的で伝統的に使用されています。
イメージマットは「画像が前景と背景の合成画像であり各画素の強度(intensity)は前景と背景の線形結合である」と仮定しています。従来のマスク手法では、1つの画素が前景に属するか背景に属するかをYes or Noで判断して画像を分割していました。しかし、このような2値しか持たないセグメンテーションマスクでは、前景物体の各画素に対して透明度の値を推定する必要があるため、髪の毛や毛皮などの細部を含む自然な風景に対応することができません。
アルファマットは、セグメンテーションマスクとは異なり、通常、極めて正確であり、毛先レベル髪の詳細と正確な前景境界を保持することができます。
最近の深層学習技術は画像マット処理における可能性を示していますが、正確な真のアルファマットの生成、研究室外でとった写真に対する汎用性の改善、高解像度画像を扱うモバイルデバイスでの推論の実行など、多くの課題が残されています。
Pixel 6スマートフォンでは、自撮り画像から高解像度かつ正確なアルファマットを推定する新しいアプローチを導入することで、ポートレートモード(肖像画モード)で撮影した自撮り画像の見栄えを大幅に向上させることができました。
被写界深度効果を合成する際、アルファマットを使用することで、撮影した被写体のシルエットをより正確に抽出し、前景と背景をより分離させることができます。これにより、様々なヘアスタイルのユーザーが自撮りカメラでポートレートモード写真を美しく撮影することが可能になります。この記事では、この改善を実現するために使用した技術について説明し、前述の課題にどのように取り組んだかを考察しています。

低解像度で粗いアルファマットで撮影した自撮り写真と、新しい高品質なアルファマットを使用した場合のポートレートモード効果の違い
ポートレートマット
ポートレートマット(Portrait Matting)の設計では、高品質なアルファマットを段階的に推定するために、一連のエンコーダ・デコーダブロックからなる完全畳み込みニューラルネットワークを学習させました。
入力されたRGB画像と、低解像度の人物セグメンテーションツールを用いて生成された粗いアルファマットを連結し、ネットワークへの入力として渡します。
新しいポートレートマッティングモデルは、MobileNetV3のバックボーンと浅い(つまりレイヤー数が少ない)デコーダを用いて、まず低解像度画像上で動作する洗練された低解像度アルファマットを予測します。
次に、浅いエンコーダ・デコーダと一連の残差ブロックを使って、高解像度画像と前のステップで精製されたアルファマットを処理します。
浅いエンコーダーデコーダーは、前工程のMobileNetV3バックボーンよりも低レベルの特徴に依存しており、各画素の最終的な透明度の値を予測するために高解像度構造特徴に重点を置いています。
このようにして、このモデルは前景のアルファマットを改良し、髪の毛の束のような非常に細かい細部を正確に抽出することができるようになりました。提案するニューラルネットワークアーキテクチャは、Tensorflow Liteを使用してPixel 6上で効率的に実行されます。
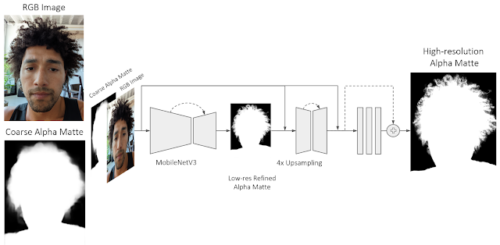
このネットワークは、カラー画像と最初に作る粗いアルファマットから高品質のアルファマットを予測します。MobileNetV3バックボーンと浅いデコーダを用いて、まず洗練された低解像度のアルファマットを予測します。次に、浅いエンコーダ・デコーダと一連の残差ブロックを用いて、最初に推定されたアルファマットをさらに精緻化します。
画像マットのための最近の深層学習のほとんどは、画素単位のアルファマットに手動で注釈付けしたデータに依存しています。このデータは画像編集ツールやグリーンスクリーンを使って生成されたもので、前景と背景を分離する学習のために使用されます。
注釈付けプロセスは面倒で、大規模なデータセットを生成するために簡単に規模拡大できません。
また、不正確なアルファマットや、背景からの反射光によって汚染された前景画像(例えば、「グリーンスピル(green spill、グリーンスクリーン使用時に被写体周囲に緑色のぼやけた輪郭が出来てしまう事)」)が生成されることがよくあります。さらに、この方法では、被写体の照明が背景環境の照明と一致していることを確認することはできません。
これらの課題を解決するために、Portrait Mattingは、独自撮影装置であるLight Stageを用いて生成された高品質なデータセットを用いて学習します。従来のデータセットと比較して、再照明により前景の被写体の照明が背景と一致するため、より現実的なものとなっています。さらに、後述するモデルの汎化性を向上させるために、実写画像から得た疑似的なグランドトゥルースラベルのアルファマットを用いてモデルの学習を監督しています。このグランドトゥルースデータ生成プロセスは、本作業の重要な構成要素の一つです。
3.毛先まで明瞭に自撮りできるPixel 6のポートレートモード(1/2)関連リンク
1)ai.googleblog.com
Accurate Alpha Matting for Portrait Mode Selfies on Pixel 6
