
1.StylEx:犬と猫の違いは何かを視覚的に説明する新しい手法(1/2)まとめ
・ニューラルネットワークが何に着目して画像を分類しているか特定する事は困難
・従来手法は注目している場所や全体的な特徴はわかるが特徴が分離できていない
・StylExは画像分類器に影響を与える解きほぐされた属性を自動的に発見し視覚化可能
2.StylExとは?
以下、ai.googleblog.comより「Introducing StylEx: A New Approach for Visual Explanation of Classifiers」の意訳です。元記事は2022年1月18日、Oran LangさんとInbar Mosseriさんによる投稿です。
犬は確かに口が空いている傾向あるんだなぁ、と思いながら選んだアイキャッチ画像のクレジットはPhoto by Tran Mau Tri Tam on Unsplash
ニューラルネットワークは、ある種のタスクを驚くほどうまくこなしますが、その判断がどのようになされたのかはしばしば謎に包まれており、理解することは難しいです。
例えば、どのような信号に着目してモデルが画像を分類しているか特定することです。
ニューラルモデルの意思決定プロセスを説明することは、医療画像の解析や自律走行自動車など、人間の監視が不可欠な特定の分野において、高い社会的インパクトを与える可能性があります。
また、これらの知見は、医療従事者の指導、モデルが内包する偏見の解明、下流タスクにおける意思決定者への支援、さらには科学的発見の支援に役立つ可能性があります。
分類器を視覚的に説明する従来のアプローチには、例えばアテンションマップ(Grad-CAMなど)は、画像中のどの領域が分類に影響を与えるかを強調表示できますが、その領域内のどの属性が分類を決定するかまでは説明しません。それは色合いなのでしょうか?形状なのでしょうか?
また、別の手法群では、あるクラスと別のクラスの間で画像を滑らかに変換することで説明を行います。(例:GANalyze)。しかし、これらの手法は、すべての属性を一度に変更する傾向があり、影響を与える個々の属性を解きほぐす事が困難です。
ICCV 2021で発表した論文「Training a GAN to explain a classifier in StyleSpace」では、分類器を視覚的に説明するための新しいアプローチを提案します。
私たちのアプローチであるStylExは、分類器に影響を与える解きほぐされた属性を自動的に発見し、視覚化します。これにより、個々の属性を個別に操作することで、その影響を探ることができます。(ある属性を変更しても、他の属性には影響しません)。
StylExは、動物、葉、顔、網膜画像など、幅広い領域に適用可能です。
その結果、StylExは意味を持つ属性とよく一致する属性を見つけ出し、画像に関する説明を生成可能です。ユーザ研究で測定されたように、人間が解釈可能であることを示します。

ネコ対イヌ分類器に関する説明
StylEx は、分類を説明するトップ K個の発見し、分離した属性を提供します。
各ツマミを動かすと、画像中の対応する属性のみが操作されます。被写体の他の属性は固定されたままです。
例えば、ネコ対イヌ分類器を理解するために、StylExは与えられた画像から自動的に属性を解きほぐして検出し、それぞれの属性を操作することで分類器の確率にどのような影響があるかを視覚化することができます。
そして、ユーザーはこれらの属性を見て、それらが何を表しているのか意味的に解釈することができます。例えば上図では、「犬は猫よりも口を開けていることが多い」(上画像の属性#4)、「猫の瞳孔は切れ長である」(属性#5)、「猫の耳は折れていることが少ない」(属性#1)などといった結論を導き出すことができるのです。
以下の動画で、その方法を簡単に解説しています。
StylExのしくみ。分類器を説明するためにStyleGANをトレーニング
分類器と入力画像が与えられたとしましょう。私たちの目標はその分類に影響を与える個々の属性を見つけ、視覚化する事です。
そのために、高品質な画像を生成することで知られるStyleGAN2アーキテクチャを利用します。本手法は2つのフェーズから構成されます。
フェーズ1:StylExの学習
最近の研究により、StyleGAN2には 「StyleSpace」と呼ばれる解きほぐされた潜在空間があり、学習データセット内の画像の個々の意味的に意味のある属性が含まれていることが示されました。
しかし、StyleGANの学習は分類器に依存しないため、説明したい特定の分類器の判断に重要な属性を表現していない可能性があります。そこで、分類器を満足させるStyleGANのような生成器をトレーニングすることで、そのStyleSpaceが分類器固有の属性を収容するように促します。
これは、StyleGAN の生成器に2つのコンポーネントを追加して学習させることで実現されます。1つ目はエンコーダで、GANと共に再構成損失(reconstruction-loss)を用いて学習され、生成する出力画像が入力画像と視覚的に類似するように強制します。これにより、任意の入力画像にこの生成器を適用することができます。
しかし、画像の視覚的類似性だけでは十分ではありません、特定の分類器にとって重要な微妙な視覚的詳細(医療病理など)を必ずしも捉えているとは限らないからです。
そこで、StyleGAN の学習に分類損失(classification-loss)を追加し、生成された画像の分類確率を入力画像の分類確率と同じにすることを強制します。これにより、分類器にとって重要な微妙な視覚的詳細(例えば、医学的病理などが、生成された画像に含まれることが保証されます。
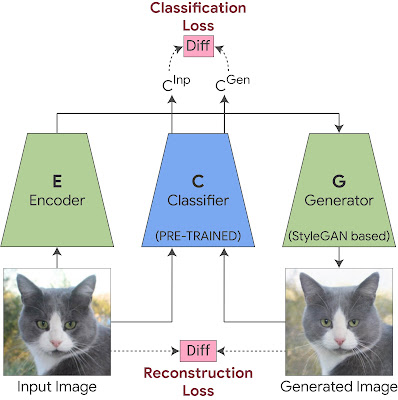
StyleExの学習
ジェネレータとエンコーダーを合同で学習させます。生成された画像と元画像の間に再構成損失を適用し、視覚的な類似性を保持します。生成された画像の分類出力と元画像の分類出力の間に分類損失を適用し、ジェネレータが分類に重要な微妙な視覚的詳細を捉えることを保証します。
3.StylEx:犬と猫の違いは何かを視覚的に説明する新しい手法(1/2)関連リンク
1)ai.googleblog.com
Introducing StylEx: A New Approach for Visual Explanation of Classifiers
2)arxiv.org
Explaining in Style: Training a GAN to explain a classifier in StyleSpace
3)explaining-in-style.github.io
Explaining in Style: Training a GAN to explain a classifier in StyleSpace

