
1.データセット蒸留による機械学習モデルの効率的なトレーニング(1/2)まとめ
・蒸留はトレーニングを効率的に行うためのアイディアでモデルとデータセットが対象となる
・蒸留したデータセットでモデルを学習させるとメモリと計算量を減らすことができる
・2つの新しいデータセット蒸留アルゴリズム、KIPとLSを発表し、蒸留済データも公開した
2.データセット蒸留とは?
以下、ai.googleblog.comより「Training Machine Learning Models More Efficiently with Dataset Distillation」の意訳です。元記事は2021年12月15日、Timothy NguyenさんとJaehoon Leeさんによる投稿です。
いやー、「モデルの気持ちになって考える」なんて話がありますけれどもアイキャッチ画像を見て如何でしょうか?データセット蒸留したCIFAR-10だそうなのですが、私はかろうじて自動車が感じ取れるくらいで飛行機、鳥、猫、鹿、犬、カエル等は全く気持ちが通じ合えてない感じがします。
機械学習(ML:Machine Learning)アルゴリズムを有効に活用するためには、(多くの場合)大量の学習データから有用な特徴を抽出する必要があります。しかし、このような大規模なデータセットを使って学習を行う事は、利用可能な計算機と計算にかかる物理的な時間の2点においてコストがかかるため、困難です。
蒸留(distillation)の考え方は、このような状況において、モデルが効果を発揮するために必要なリソースを削減することで重要な役割を果たします。蒸留の最も広く知られている形態は、モデル蒸留(model distillation、知識蒸留(knowledge distillation)とも呼ばれます)です。これは大規模で複雑な教師モデルの予測をより小さなモデルとして蒸留するものです。
このモデルを対象にしたアプローチに代わる選択肢としては、データセット蒸留(dataset distillation)があります。
これは大規模なデータセットをより小さな合成データセットに蒸留するものです。このような蒸留したデータセットでモデルを学習することにより、必要なメモリと計算量を減らすことができます。例えば、CIFAR-10データセットの5万枚の画像とラベルを全て使用する代わりに、10枚の合成データ(クラスあたり1枚)からなる蒸留データセットを使用して、初見のテストセットで良い性能を達成するMLモデルを学習することができます。

上図:本来(=無修正)のCIFAR-10画像
下図:CIFAR-10分類タスクの蒸留データセット(各クラス1画像)。これらの10枚の合成画像のみを学習データとして用いた場合、モデルはテストセットで51%にの精度を達成することができます。
ICLR 2021で発表した論文「Dataset Meta-Learning from Kernel Ridge Regression」とNeurIPS 2021で発表した論文「Dataset Distillation with Infinitely Wide Convolutional Networks」では2つの新しいデータセット蒸留アルゴリズム、KIP(Kernel Inducing Points)とLS(Label Solve)を紹介します。
これらはカーネル回帰(カーネルを通して定義された特徴量に線形モデルを当てはめる古典的な機械学習アルゴリズム)から生じる損失関数を用いてデータセットを最適化します。
KIPとLSのアルゴリズムを適用することで、画像分類のための非常に効率的な蒸留データセットが得られ、データセットをクラスあたり1、10、または50データポイントに削減しながら、多くの画像分類データセットで最先端の結果を得ることができます。
さらに、私たちは、より広い研究コミュニティに貢献するために、蒸留されたデータセットをgithubで公開することに興奮しています。
方法論
近年のディープニューラルネットワーク(DNN:Deep Neural Networks)の理論的な重要な知見の1つは、DNNの幅を広げると挙動が規則的になり、理解しやすくなることでした。
幅を無限大に近づけていくと、勾配降下法で学習したDNNは、ニューラルタンジェントカーネル(NTK:neural tangent kernel)のカーネル回帰から生じる身近でシンプルなモデルに収束していきます。
NTKはニューラルネットワークの勾配のドット積を計算して入力の類似性を測定するカーネルです。Neural Tangentsライブラリのおかげで、様々なDNNアーキテクチャ用にニューラルカーネルの規模を拡大して計算することができます。
私たちは、上記のニューラルネットワークの無限幅極限理論(infinite-width limit theory)を利用して、データセット蒸留に取り組みました。
データセット蒸留は、2段階の最適化プロセスとして定式化することが可能です。
すなわち、「学習したデータに対してモデルを学習させる「内側ループ(inner loop)」」と、「学習したデータを自然な(つまり、修正されていない)データを使った際に良いスコアをだすように最適化する「外側ループ(outer loop)」」です。
無限幅極限法では、有限幅のニューラルネットワークを使って学習する内部ループを、単純なカーネル回帰に置き換えます。正則化項の追加により、カーネル回帰はカーネルリッジ回帰(KRR:Kernel Ridge-Regression)問題となります。
これは非常に価値のある発見です。
なぜなら、カーネルリッジ回帰器(すなわち、このアルゴリズムによる予測器)は、(ニューラルネットワークの予測器とは異なり)その学習データに関して明示的な式を持っているからです。
ということは、外側のループ実行時にKRR損失関数を簡単に最適化することができるのです。
元のデータのラベルはワンホットベクトルで表すことができます。すなわち、真のラベルには1が与えられ、それ以外のラベルには0が与えられたベクトルです。
したがって、猫の画像には「猫」というラベルが1として割り当てられ、「犬」と「馬」のラベルは0となります。私たちが用いるラベルは、その後の平均中心化ステップ(mean-centering step)を含み、各成分からクラス数の逆数を差し引き(10項目の分類では0.1になります)、データセット全体の各ラベル成分の期待値が0に正規化されるようにします。
自然画像のラベルはこのような標準的な形で表現できますが、学習された蒸留データセットのラベルは性能を優先するために自由に最適化することができます。
内側ループでカーネルリッジ回帰器を得た後、外側ループのKRR損失関数は、自然画像の元のラベルとカーネルリッジ回帰器によって予測されるラベルの間の平均二乗誤差を計算します。KIPは勾配に基づく手法によりKRR損失関数を最小化することで、サポートデータ(画像と場合によってはラベル)を最適化します。
ラベル解決アルゴリズム(LS)は、KRR損失関数を最小化するサポートラベルの集合を直接求め、各(自然な)サポート画像に対して一意の密なラベルベクトルを生成します。
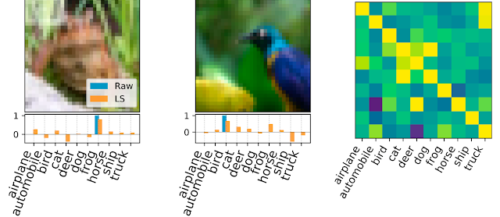
ラベル解決で得られたラベルの例
左と中央図:下側に示すラベルの可能性があるサンプル画像。生のワンホットラベルは青で、最終的にLSで生成された密なラベルはオレンジで示されています。
右図:元ラベルと学習済みラベルの共分散行列。ここでは、CIFAR-10データセットから500個のラベルを抽出しました。これらのラベルを用いてカーネルリッジ回帰を行ったところ、69.7%のテスト精度が達成されました。
3.データセット蒸留による機械学習モデルの効率的なトレーニング(1/2)関連リンク
1)ai.googleblog.com
Training Machine Learning Models More Efficiently with Dataset Distillation
2)openreview.net
Dataset Meta-Learning from Kernel Ridge-Regression
Dataset Distillation with Infinitely Wide Convolutional Networks
3)github.com
google-research/kip/

